How to write a case study — examples, templates, and tools

It’s a marketer’s job to communicate the effectiveness of a product or service to potential and current customers to convince them to buy and keep business moving. One of the best methods for doing this is to share success stories that are relatable to prospects and customers based on their pain points, experiences, and overall needs.
That’s where case studies come in. Case studies are an essential part of a content marketing plan. These in-depth stories of customer experiences are some of the most effective at demonstrating the value of a product or service. Yet many marketers don’t use them, whether because of their regimented formats or the process of customer involvement and approval.
A case study is a powerful tool for showcasing your hard work and the success your customer achieved. But writing a great case study can be difficult if you’ve never done it before or if it’s been a while. This guide will show you how to write an effective case study and provide real-world examples and templates that will keep readers engaged and support your business.
In this article, you’ll learn:

What is a case study?
How to write a case study, case study templates, case study examples, case study tools.
A case study is the detailed story of a customer’s experience with a product or service that demonstrates their success and often includes measurable outcomes. Case studies are used in a range of fields and for various reasons, from business to academic research. They’re especially impactful in marketing as brands work to convince and convert consumers with relatable, real-world stories of actual customer experiences.
The best case studies tell the story of a customer’s success, including the steps they took, the results they achieved, and the support they received from a brand along the way. To write a great case study, you need to:
- Celebrate the customer and make them — not a product or service — the star of the story.
- Craft the story with specific audiences or target segments in mind so that the story of one customer will be viewed as relatable and actionable for another customer.
- Write copy that is easy to read and engaging so that readers will gain the insights and messages intended.
- Follow a standardized format that includes all of the essentials a potential customer would find interesting and useful.
- Support all of the claims for success made in the story with data in the forms of hard numbers and customer statements.
Case studies are a type of review but more in depth, aiming to show — rather than just tell — the positive experiences that customers have with a brand. Notably, 89% of consumers read reviews before deciding to buy, and 79% view case study content as part of their purchasing process. When it comes to B2B sales, 52% of buyers rank case studies as an important part of their evaluation process.
Telling a brand story through the experience of a tried-and-true customer matters. The story is relatable to potential new customers as they imagine themselves in the shoes of the company or individual featured in the case study. Showcasing previous customers can help new ones see themselves engaging with your brand in the ways that are most meaningful to them.
Besides sharing the perspective of another customer, case studies stand out from other content marketing forms because they are based on evidence. Whether pulling from client testimonials or data-driven results, case studies tend to have more impact on new business because the story contains information that is both objective (data) and subjective (customer experience) — and the brand doesn’t sound too self-promotional.

Case studies are unique in that there’s a fairly standardized format for telling a customer’s story. But that doesn’t mean there isn’t room for creativity. It’s all about making sure that teams are clear on the goals for the case study — along with strategies for supporting content and channels — and understanding how the story fits within the framework of the company’s overall marketing goals.
Here are the basic steps to writing a good case study.
1. Identify your goal
Start by defining exactly who your case study will be designed to help. Case studies are about specific instances where a company works with a customer to achieve a goal. Identify which customers are likely to have these goals, as well as other needs the story should cover to appeal to them.
The answer is often found in one of the buyer personas that have been constructed as part of your larger marketing strategy. This can include anything from new leads generated by the marketing team to long-term customers that are being pressed for cross-sell opportunities. In all of these cases, demonstrating value through a relatable customer success story can be part of the solution to conversion.
2. Choose your client or subject
Who you highlight matters. Case studies tie brands together that might otherwise not cross paths. A writer will want to ensure that the highlighted customer aligns with their own company’s brand identity and offerings. Look for a customer with positive name recognition who has had great success with a product or service and is willing to be an advocate.
The client should also match up with the identified target audience. Whichever company or individual is selected should be a reflection of other potential customers who can see themselves in similar circumstances, having the same problems and possible solutions.
Some of the most compelling case studies feature customers who:
- Switch from one product or service to another while naming competitors that missed the mark.
- Experience measurable results that are relatable to others in a specific industry.
- Represent well-known brands and recognizable names that are likely to compel action.
- Advocate for a product or service as a champion and are well-versed in its advantages.
Whoever or whatever customer is selected, marketers must ensure they have the permission of the company involved before getting started. Some brands have strict review and approval procedures for any official marketing or promotional materials that include their name. Acquiring those approvals in advance will prevent any miscommunication or wasted effort if there is an issue with their legal or compliance teams.
3. Conduct research and compile data
Substantiating the claims made in a case study — either by the marketing team or customers themselves — adds validity to the story. To do this, include data and feedback from the client that defines what success looks like. This can be anything from demonstrating return on investment (ROI) to a specific metric the customer was striving to improve. Case studies should prove how an outcome was achieved and show tangible results that indicate to the customer that your solution is the right one.
This step could also include customer interviews. Make sure that the people being interviewed are key stakeholders in the purchase decision or deployment and use of the product or service that is being highlighted. Content writers should work off a set list of questions prepared in advance. It can be helpful to share these with the interviewees beforehand so they have time to consider and craft their responses. One of the best interview tactics to keep in mind is to ask questions where yes and no are not natural answers. This way, your subject will provide more open-ended responses that produce more meaningful content.
4. Choose the right format
There are a number of different ways to format a case study. Depending on what you hope to achieve, one style will be better than another. However, there are some common elements to include, such as:
- An engaging headline
- A subject and customer introduction
- The unique challenge or challenges the customer faced
- The solution the customer used to solve the problem
- The results achieved
- Data and statistics to back up claims of success
- A strong call to action (CTA) to engage with the vendor
It’s also important to note that while case studies are traditionally written as stories, they don’t have to be in a written format. Some companies choose to get more creative with their case studies and produce multimedia content, depending on their audience and objectives. Case study formats can include traditional print stories, interactive web or social content, data-heavy infographics, professionally shot videos, podcasts, and more.
5. Write your case study
We’ll go into more detail later about how exactly to write a case study, including templates and examples. Generally speaking, though, there are a few things to keep in mind when writing your case study.
- Be clear and concise. Readers want to get to the point of the story quickly and easily, and they’ll be looking to see themselves reflected in the story right from the start.
- Provide a big picture. Always make sure to explain who the client is, their goals, and how they achieved success in a short introduction to engage the reader.
- Construct a clear narrative. Stick to the story from the perspective of the customer and what they needed to solve instead of just listing product features or benefits.
- Leverage graphics. Incorporating infographics, charts, and sidebars can be a more engaging and eye-catching way to share key statistics and data in readable ways.
- Offer the right amount of detail. Most case studies are one or two pages with clear sections that a reader can skim to find the information most important to them.
- Include data to support claims. Show real results — both facts and figures and customer quotes — to demonstrate credibility and prove the solution works.
6. Promote your story
Marketers have a number of options for distribution of a freshly minted case study. Many brands choose to publish case studies on their website and post them on social media. This can help support SEO and organic content strategies while also boosting company credibility and trust as visitors see that other businesses have used the product or service.
Marketers are always looking for quality content they can use for lead generation. Consider offering a case study as gated content behind a form on a landing page or as an offer in an email message. One great way to do this is to summarize the content and tease the full story available for download after the user takes an action.
Sales teams can also leverage case studies, so be sure they are aware that the assets exist once they’re published. Especially when it comes to larger B2B sales, companies often ask for examples of similar customer challenges that have been solved.
Now that you’ve learned a bit about case studies and what they should include, you may be wondering how to start creating great customer story content. Here are a couple of templates you can use to structure your case study.
Template 1 — Challenge-solution-result format
- Start with an engaging title. This should be fewer than 70 characters long for SEO best practices. One of the best ways to approach the title is to include the customer’s name and a hint at the challenge they overcame in the end.
- Create an introduction. Lead with an explanation as to who the customer is, the need they had, and the opportunity they found with a specific product or solution. Writers can also suggest the success the customer experienced with the solution they chose.
- Present the challenge. This should be several paragraphs long and explain the problem the customer faced and the issues they were trying to solve. Details should tie into the company’s products and services naturally. This section needs to be the most relatable to the reader so they can picture themselves in a similar situation.
- Share the solution. Explain which product or service offered was the ideal fit for the customer and why. Feel free to delve into their experience setting up, purchasing, and onboarding the solution.
- Explain the results. Demonstrate the impact of the solution they chose by backing up their positive experience with data. Fill in with customer quotes and tangible, measurable results that show the effect of their choice.
- Ask for action. Include a CTA at the end of the case study that invites readers to reach out for more information, try a demo, or learn more — to nurture them further in the marketing pipeline. What you ask of the reader should tie directly into the goals that were established for the case study in the first place.
Template 2 — Data-driven format
- Start with an engaging title. Be sure to include a statistic or data point in the first 70 characters. Again, it’s best to include the customer’s name as part of the title.
- Create an overview. Share the customer’s background and a short version of the challenge they faced. Present the reason a particular product or service was chosen, and feel free to include quotes from the customer about their selection process.
- Present data point 1. Isolate the first metric that the customer used to define success and explain how the product or solution helped to achieve this goal. Provide data points and quotes to substantiate the claim that success was achieved.
- Present data point 2. Isolate the second metric that the customer used to define success and explain what the product or solution did to achieve this goal. Provide data points and quotes to substantiate the claim that success was achieved.
- Present data point 3. Isolate the final metric that the customer used to define success and explain what the product or solution did to achieve this goal. Provide data points and quotes to substantiate the claim that success was achieved.
- Summarize the results. Reiterate the fact that the customer was able to achieve success thanks to a specific product or service. Include quotes and statements that reflect customer satisfaction and suggest they plan to continue using the solution.
- Ask for action. Include a CTA at the end of the case study that asks readers to reach out for more information, try a demo, or learn more — to further nurture them in the marketing pipeline. Again, remember that this is where marketers can look to convert their content into action with the customer.
While templates are helpful, seeing a case study in action can also be a great way to learn. Here are some examples of how Adobe customers have experienced success.
Juniper Networks
One example is the Adobe and Juniper Networks case study , which puts the reader in the customer’s shoes. The beginning of the story quickly orients the reader so that they know exactly who the article is about and what they were trying to achieve. Solutions are outlined in a way that shows Adobe Experience Manager is the best choice and a natural fit for the customer. Along the way, quotes from the client are incorporated to help add validity to the statements. The results in the case study are conveyed with clear evidence of scale and volume using tangible data.

The story of Lenovo’s journey with Adobe is one that spans years of planning, implementation, and rollout. The Lenovo case study does a great job of consolidating all of this into a relatable journey that other enterprise organizations can see themselves taking, despite the project size. This case study also features descriptive headers and compelling visual elements that engage the reader and strengthen the content.
Tata Consulting
When it comes to using data to show customer results, this case study does an excellent job of conveying details and numbers in an easy-to-digest manner. Bullet points at the start break up the content while also helping the reader understand exactly what the case study will be about. Tata Consulting used Adobe to deliver elevated, engaging content experiences for a large telecommunications client of its own — an objective that’s relatable for a lot of companies.
Case studies are a vital tool for any marketing team as they enable you to demonstrate the value of your company’s products and services to others. They help marketers do their job and add credibility to a brand trying to promote its solutions by using the experiences and stories of real customers.
When you’re ready to get started with a case study:
- Think about a few goals you’d like to accomplish with your content.
- Make a list of successful clients that would be strong candidates for a case study.
- Reach out to the client to get their approval and conduct an interview.
- Gather the data to present an engaging and effective customer story.
Adobe can help
There are several Adobe products that can help you craft compelling case studies. Adobe Experience Platform helps you collect data and deliver great customer experiences across every channel. Once you’ve created your case studies, Experience Platform will help you deliver the right information to the right customer at the right time for maximum impact.
To learn more, watch the Adobe Experience Platform story .
Keep in mind that the best case studies are backed by data. That’s where Adobe Real-Time Customer Data Platform and Adobe Analytics come into play. With Real-Time CDP, you can gather the data you need to build a great case study and target specific customers to deliver the content to the right audience at the perfect moment.
Watch the Real-Time CDP overview video to learn more.
Finally, Adobe Analytics turns real-time data into real-time insights. It helps your business collect and synthesize data from multiple platforms to make more informed decisions and create the best case study possible.
Request a demo to learn more about Adobe Analytics.
https://business.adobe.com/blog/perspectives/b2b-ecommerce-10-case-studies-inspire-you
https://business.adobe.com/blog/basics/business-case
https://business.adobe.com/blog/basics/what-is-real-time-analytics

The Ultimate Guide to Qualitative Research - Part 1: The Basics

- Introduction and overview
- What is qualitative research?
- What is qualitative data?
- Examples of qualitative data
- Qualitative vs. quantitative research
- Mixed methods
- Qualitative research preparation
- Theoretical perspective
- Theoretical framework
- Literature reviews
Research question
- Conceptual framework
- Conceptual vs. theoretical framework
Data collection
- Qualitative research methods
- Focus groups
- Observational research
What is a case study?
Applications for case study research, what is a good case study, process of case study design, benefits and limitations of case studies.
- Ethnographical research
- Ethical considerations
- Confidentiality and privacy
- Power dynamics
- Reflexivity
Case studies
Case studies are essential to qualitative research , offering a lens through which researchers can investigate complex phenomena within their real-life contexts. This chapter explores the concept, purpose, applications, examples, and types of case studies and provides guidance on how to conduct case study research effectively.

Whereas quantitative methods look at phenomena at scale, case study research looks at a concept or phenomenon in considerable detail. While analyzing a single case can help understand one perspective regarding the object of research inquiry, analyzing multiple cases can help obtain a more holistic sense of the topic or issue. Let's provide a basic definition of a case study, then explore its characteristics and role in the qualitative research process.
Definition of a case study
A case study in qualitative research is a strategy of inquiry that involves an in-depth investigation of a phenomenon within its real-world context. It provides researchers with the opportunity to acquire an in-depth understanding of intricate details that might not be as apparent or accessible through other methods of research. The specific case or cases being studied can be a single person, group, or organization – demarcating what constitutes a relevant case worth studying depends on the researcher and their research question .
Among qualitative research methods , a case study relies on multiple sources of evidence, such as documents, artifacts, interviews , or observations , to present a complete and nuanced understanding of the phenomenon under investigation. The objective is to illuminate the readers' understanding of the phenomenon beyond its abstract statistical or theoretical explanations.
Characteristics of case studies
Case studies typically possess a number of distinct characteristics that set them apart from other research methods. These characteristics include a focus on holistic description and explanation, flexibility in the design and data collection methods, reliance on multiple sources of evidence, and emphasis on the context in which the phenomenon occurs.
Furthermore, case studies can often involve a longitudinal examination of the case, meaning they study the case over a period of time. These characteristics allow case studies to yield comprehensive, in-depth, and richly contextualized insights about the phenomenon of interest.
The role of case studies in research
Case studies hold a unique position in the broader landscape of research methods aimed at theory development. They are instrumental when the primary research interest is to gain an intensive, detailed understanding of a phenomenon in its real-life context.
In addition, case studies can serve different purposes within research - they can be used for exploratory, descriptive, or explanatory purposes, depending on the research question and objectives. This flexibility and depth make case studies a valuable tool in the toolkit of qualitative researchers.
Remember, a well-conducted case study can offer a rich, insightful contribution to both academic and practical knowledge through theory development or theory verification, thus enhancing our understanding of complex phenomena in their real-world contexts.
What is the purpose of a case study?
Case study research aims for a more comprehensive understanding of phenomena, requiring various research methods to gather information for qualitative analysis . Ultimately, a case study can allow the researcher to gain insight into a particular object of inquiry and develop a theoretical framework relevant to the research inquiry.
Why use case studies in qualitative research?
Using case studies as a research strategy depends mainly on the nature of the research question and the researcher's access to the data.
Conducting case study research provides a level of detail and contextual richness that other research methods might not offer. They are beneficial when there's a need to understand complex social phenomena within their natural contexts.
The explanatory, exploratory, and descriptive roles of case studies
Case studies can take on various roles depending on the research objectives. They can be exploratory when the research aims to discover new phenomena or define new research questions; they are descriptive when the objective is to depict a phenomenon within its context in a detailed manner; and they can be explanatory if the goal is to understand specific relationships within the studied context. Thus, the versatility of case studies allows researchers to approach their topic from different angles, offering multiple ways to uncover and interpret the data .
The impact of case studies on knowledge development
Case studies play a significant role in knowledge development across various disciplines. Analysis of cases provides an avenue for researchers to explore phenomena within their context based on the collected data.

This can result in the production of rich, practical insights that can be instrumental in both theory-building and practice. Case studies allow researchers to delve into the intricacies and complexities of real-life situations, uncovering insights that might otherwise remain hidden.
Types of case studies
In qualitative research , a case study is not a one-size-fits-all approach. Depending on the nature of the research question and the specific objectives of the study, researchers might choose to use different types of case studies. These types differ in their focus, methodology, and the level of detail they provide about the phenomenon under investigation.
Understanding these types is crucial for selecting the most appropriate approach for your research project and effectively achieving your research goals. Let's briefly look at the main types of case studies.
Exploratory case studies
Exploratory case studies are typically conducted to develop a theory or framework around an understudied phenomenon. They can also serve as a precursor to a larger-scale research project. Exploratory case studies are useful when a researcher wants to identify the key issues or questions which can spur more extensive study or be used to develop propositions for further research. These case studies are characterized by flexibility, allowing researchers to explore various aspects of a phenomenon as they emerge, which can also form the foundation for subsequent studies.
Descriptive case studies
Descriptive case studies aim to provide a complete and accurate representation of a phenomenon or event within its context. These case studies are often based on an established theoretical framework, which guides how data is collected and analyzed. The researcher is concerned with describing the phenomenon in detail, as it occurs naturally, without trying to influence or manipulate it.
Explanatory case studies
Explanatory case studies are focused on explanation - they seek to clarify how or why certain phenomena occur. Often used in complex, real-life situations, they can be particularly valuable in clarifying causal relationships among concepts and understanding the interplay between different factors within a specific context.

Intrinsic, instrumental, and collective case studies
These three categories of case studies focus on the nature and purpose of the study. An intrinsic case study is conducted when a researcher has an inherent interest in the case itself. Instrumental case studies are employed when the case is used to provide insight into a particular issue or phenomenon. A collective case study, on the other hand, involves studying multiple cases simultaneously to investigate some general phenomena.
Each type of case study serves a different purpose and has its own strengths and challenges. The selection of the type should be guided by the research question and objectives, as well as the context and constraints of the research.
The flexibility, depth, and contextual richness offered by case studies make this approach an excellent research method for various fields of study. They enable researchers to investigate real-world phenomena within their specific contexts, capturing nuances that other research methods might miss. Across numerous fields, case studies provide valuable insights into complex issues.
Critical information systems research
Case studies provide a detailed understanding of the role and impact of information systems in different contexts. They offer a platform to explore how information systems are designed, implemented, and used and how they interact with various social, economic, and political factors. Case studies in this field often focus on examining the intricate relationship between technology, organizational processes, and user behavior, helping to uncover insights that can inform better system design and implementation.
Health research
Health research is another field where case studies are highly valuable. They offer a way to explore patient experiences, healthcare delivery processes, and the impact of various interventions in a real-world context.

Case studies can provide a deep understanding of a patient's journey, giving insights into the intricacies of disease progression, treatment effects, and the psychosocial aspects of health and illness.
Asthma research studies
Specifically within medical research, studies on asthma often employ case studies to explore the individual and environmental factors that influence asthma development, management, and outcomes. A case study can provide rich, detailed data about individual patients' experiences, from the triggers and symptoms they experience to the effectiveness of various management strategies. This can be crucial for developing patient-centered asthma care approaches.
Other fields
Apart from the fields mentioned, case studies are also extensively used in business and management research, education research, and political sciences, among many others. They provide an opportunity to delve into the intricacies of real-world situations, allowing for a comprehensive understanding of various phenomena.
Case studies, with their depth and contextual focus, offer unique insights across these varied fields. They allow researchers to illuminate the complexities of real-life situations, contributing to both theory and practice.
Whatever field you're in, ATLAS.ti puts your data to work for you
Download a free trial of ATLAS.ti to turn your data into insights.
Understanding the key elements of case study design is crucial for conducting rigorous and impactful case study research. A well-structured design guides the researcher through the process, ensuring that the study is methodologically sound and its findings are reliable and valid. The main elements of case study design include the research question , propositions, units of analysis, and the logic linking the data to the propositions.
The research question is the foundation of any research study. A good research question guides the direction of the study and informs the selection of the case, the methods of collecting data, and the analysis techniques. A well-formulated research question in case study research is typically clear, focused, and complex enough to merit further detailed examination of the relevant case(s).
Propositions
Propositions, though not necessary in every case study, provide a direction by stating what we might expect to find in the data collected. They guide how data is collected and analyzed by helping researchers focus on specific aspects of the case. They are particularly important in explanatory case studies, which seek to understand the relationships among concepts within the studied phenomenon.
Units of analysis
The unit of analysis refers to the case, or the main entity or entities that are being analyzed in the study. In case study research, the unit of analysis can be an individual, a group, an organization, a decision, an event, or even a time period. It's crucial to clearly define the unit of analysis, as it shapes the qualitative data analysis process by allowing the researcher to analyze a particular case and synthesize analysis across multiple case studies to draw conclusions.
Argumentation
This refers to the inferential model that allows researchers to draw conclusions from the data. The researcher needs to ensure that there is a clear link between the data, the propositions (if any), and the conclusions drawn. This argumentation is what enables the researcher to make valid and credible inferences about the phenomenon under study.
Understanding and carefully considering these elements in the design phase of a case study can significantly enhance the quality of the research. It can help ensure that the study is methodologically sound and its findings contribute meaningful insights about the case.
Ready to jumpstart your research with ATLAS.ti?
Conceptualize your research project with our intuitive data analysis interface. Download a free trial today.
Conducting a case study involves several steps, from defining the research question and selecting the case to collecting and analyzing data . This section outlines these key stages, providing a practical guide on how to conduct case study research.
Defining the research question
The first step in case study research is defining a clear, focused research question. This question should guide the entire research process, from case selection to analysis. It's crucial to ensure that the research question is suitable for a case study approach. Typically, such questions are exploratory or descriptive in nature and focus on understanding a phenomenon within its real-life context.
Selecting and defining the case
The selection of the case should be based on the research question and the objectives of the study. It involves choosing a unique example or a set of examples that provide rich, in-depth data about the phenomenon under investigation. After selecting the case, it's crucial to define it clearly, setting the boundaries of the case, including the time period and the specific context.
Previous research can help guide the case study design. When considering a case study, an example of a case could be taken from previous case study research and used to define cases in a new research inquiry. Considering recently published examples can help understand how to select and define cases effectively.
Developing a detailed case study protocol
A case study protocol outlines the procedures and general rules to be followed during the case study. This includes the data collection methods to be used, the sources of data, and the procedures for analysis. Having a detailed case study protocol ensures consistency and reliability in the study.
The protocol should also consider how to work with the people involved in the research context to grant the research team access to collecting data. As mentioned in previous sections of this guide, establishing rapport is an essential component of qualitative research as it shapes the overall potential for collecting and analyzing data.
Collecting data
Gathering data in case study research often involves multiple sources of evidence, including documents, archival records, interviews, observations, and physical artifacts. This allows for a comprehensive understanding of the case. The process for gathering data should be systematic and carefully documented to ensure the reliability and validity of the study.
Analyzing and interpreting data
The next step is analyzing the data. This involves organizing the data , categorizing it into themes or patterns , and interpreting these patterns to answer the research question. The analysis might also involve comparing the findings with prior research or theoretical propositions.
Writing the case study report
The final step is writing the case study report . This should provide a detailed description of the case, the data, the analysis process, and the findings. The report should be clear, organized, and carefully written to ensure that the reader can understand the case and the conclusions drawn from it.
Each of these steps is crucial in ensuring that the case study research is rigorous, reliable, and provides valuable insights about the case.
The type, depth, and quality of data in your study can significantly influence the validity and utility of the study. In case study research, data is usually collected from multiple sources to provide a comprehensive and nuanced understanding of the case. This section will outline the various methods of collecting data used in case study research and discuss considerations for ensuring the quality of the data.
Interviews are a common method of gathering data in case study research. They can provide rich, in-depth data about the perspectives, experiences, and interpretations of the individuals involved in the case. Interviews can be structured , semi-structured , or unstructured , depending on the research question and the degree of flexibility needed.
Observations
Observations involve the researcher observing the case in its natural setting, providing first-hand information about the case and its context. Observations can provide data that might not be revealed in interviews or documents, such as non-verbal cues or contextual information.
Documents and artifacts
Documents and archival records provide a valuable source of data in case study research. They can include reports, letters, memos, meeting minutes, email correspondence, and various public and private documents related to the case.

These records can provide historical context, corroborate evidence from other sources, and offer insights into the case that might not be apparent from interviews or observations.
Physical artifacts refer to any physical evidence related to the case, such as tools, products, or physical environments. These artifacts can provide tangible insights into the case, complementing the data gathered from other sources.
Ensuring the quality of data collection
Determining the quality of data in case study research requires careful planning and execution. It's crucial to ensure that the data is reliable, accurate, and relevant to the research question. This involves selecting appropriate methods of collecting data, properly training interviewers or observers, and systematically recording and storing the data. It also includes considering ethical issues related to collecting and handling data, such as obtaining informed consent and ensuring the privacy and confidentiality of the participants.
Data analysis
Analyzing case study research involves making sense of the rich, detailed data to answer the research question. This process can be challenging due to the volume and complexity of case study data. However, a systematic and rigorous approach to analysis can ensure that the findings are credible and meaningful. This section outlines the main steps and considerations in analyzing data in case study research.
Organizing the data
The first step in the analysis is organizing the data. This involves sorting the data into manageable sections, often according to the data source or the theme. This step can also involve transcribing interviews, digitizing physical artifacts, or organizing observational data.
Categorizing and coding the data
Once the data is organized, the next step is to categorize or code the data. This involves identifying common themes, patterns, or concepts in the data and assigning codes to relevant data segments. Coding can be done manually or with the help of software tools, and in either case, qualitative analysis software can greatly facilitate the entire coding process. Coding helps to reduce the data to a set of themes or categories that can be more easily analyzed.
Identifying patterns and themes
After coding the data, the researcher looks for patterns or themes in the coded data. This involves comparing and contrasting the codes and looking for relationships or patterns among them. The identified patterns and themes should help answer the research question.
Interpreting the data
Once patterns and themes have been identified, the next step is to interpret these findings. This involves explaining what the patterns or themes mean in the context of the research question and the case. This interpretation should be grounded in the data, but it can also involve drawing on theoretical concepts or prior research.
Verification of the data
The last step in the analysis is verification. This involves checking the accuracy and consistency of the analysis process and confirming that the findings are supported by the data. This can involve re-checking the original data, checking the consistency of codes, or seeking feedback from research participants or peers.
Like any research method , case study research has its strengths and limitations. Researchers must be aware of these, as they can influence the design, conduct, and interpretation of the study.
Understanding the strengths and limitations of case study research can also guide researchers in deciding whether this approach is suitable for their research question . This section outlines some of the key strengths and limitations of case study research.
Benefits include the following:
- Rich, detailed data: One of the main strengths of case study research is that it can generate rich, detailed data about the case. This can provide a deep understanding of the case and its context, which can be valuable in exploring complex phenomena.
- Flexibility: Case study research is flexible in terms of design , data collection , and analysis . A sufficient degree of flexibility allows the researcher to adapt the study according to the case and the emerging findings.
- Real-world context: Case study research involves studying the case in its real-world context, which can provide valuable insights into the interplay between the case and its context.
- Multiple sources of evidence: Case study research often involves collecting data from multiple sources , which can enhance the robustness and validity of the findings.
On the other hand, researchers should consider the following limitations:
- Generalizability: A common criticism of case study research is that its findings might not be generalizable to other cases due to the specificity and uniqueness of each case.
- Time and resource intensive: Case study research can be time and resource intensive due to the depth of the investigation and the amount of collected data.
- Complexity of analysis: The rich, detailed data generated in case study research can make analyzing the data challenging.
- Subjectivity: Given the nature of case study research, there may be a higher degree of subjectivity in interpreting the data , so researchers need to reflect on this and transparently convey to audiences how the research was conducted.
Being aware of these strengths and limitations can help researchers design and conduct case study research effectively and interpret and report the findings appropriately.

Ready to analyze your data with ATLAS.ti?
See how our intuitive software can draw key insights from your data with a free trial today.
Home Blog Business How to Present a Case Study: Examples and Best Practices
How to Present a Case Study: Examples and Best Practices

Marketers, consultants, salespeople, and all other types of business managers often use case study analysis to highlight a success story, showing how an exciting problem can be or was addressed. But how do you create a compelling case study and then turn it into a memorable presentation? Get a lowdown from this post!
Table of Content s
- Why Case Studies are a Popular Marketing Technique
Popular Case Study Format Types
How to write a case study: a 4-step framework, how to do a case study presentation: 3 proven tips, how long should a case study be, final tip: use compelling presentation visuals, business case study examples, what is a case study .
Let’s start with this great case study definition by the University of South Caroline:
In the social sciences, the term case study refers to both a method of analysis and a specific research design for examining a problem, both of which can generalize findings across populations.
In simpler terms — a case study is investigative research into a problem aimed at presenting or highlighting solution(s) to the analyzed issues.
A standard business case study provides insights into:
- General business/market conditions
- The main problem faced
- Methods applied
- The outcomes gained using a specific tool or approach
Case studies (also called case reports) are also used in clinical settings to analyze patient outcomes outside of the business realm.
But this is a topic for another time. In this post, we’ll focus on teaching you how to write and present a business case, plus share several case study PowerPoint templates and design tips!

Why Case Studies are a Popular Marketing Technique
Besides presenting a solution to an internal issue, case studies are often used as a content marketing technique . According to a 2020 Content Marketing Institute report, 69% of B2B marketers use case studies as part of their marketing mix.
A case study informs the reader about a possible solution and soft-sells the results, which can be achieved with your help (e.g., by using your software or by partnering with your specialist).
For the above purpose, case studies work like a charm. Per the same report:
- For 9% of marketers, case studies are also the best method for nurturing leads.
- 23% admit that case studies are beneficial for improving conversions.
Moreover, case studies also help improve your brand’s credibility, especially in the current fake news landscape and dubious claims made without proper credit.
Ultimately, case studies naturally help build up more compelling, relatable stories and showcase your product benefits through the prism of extra social proof, courtesy of the case study subject.

Most case studies come either as a slide deck or as a downloadable PDF document.
Typically, you have several options to distribute your case study for maximum reach:
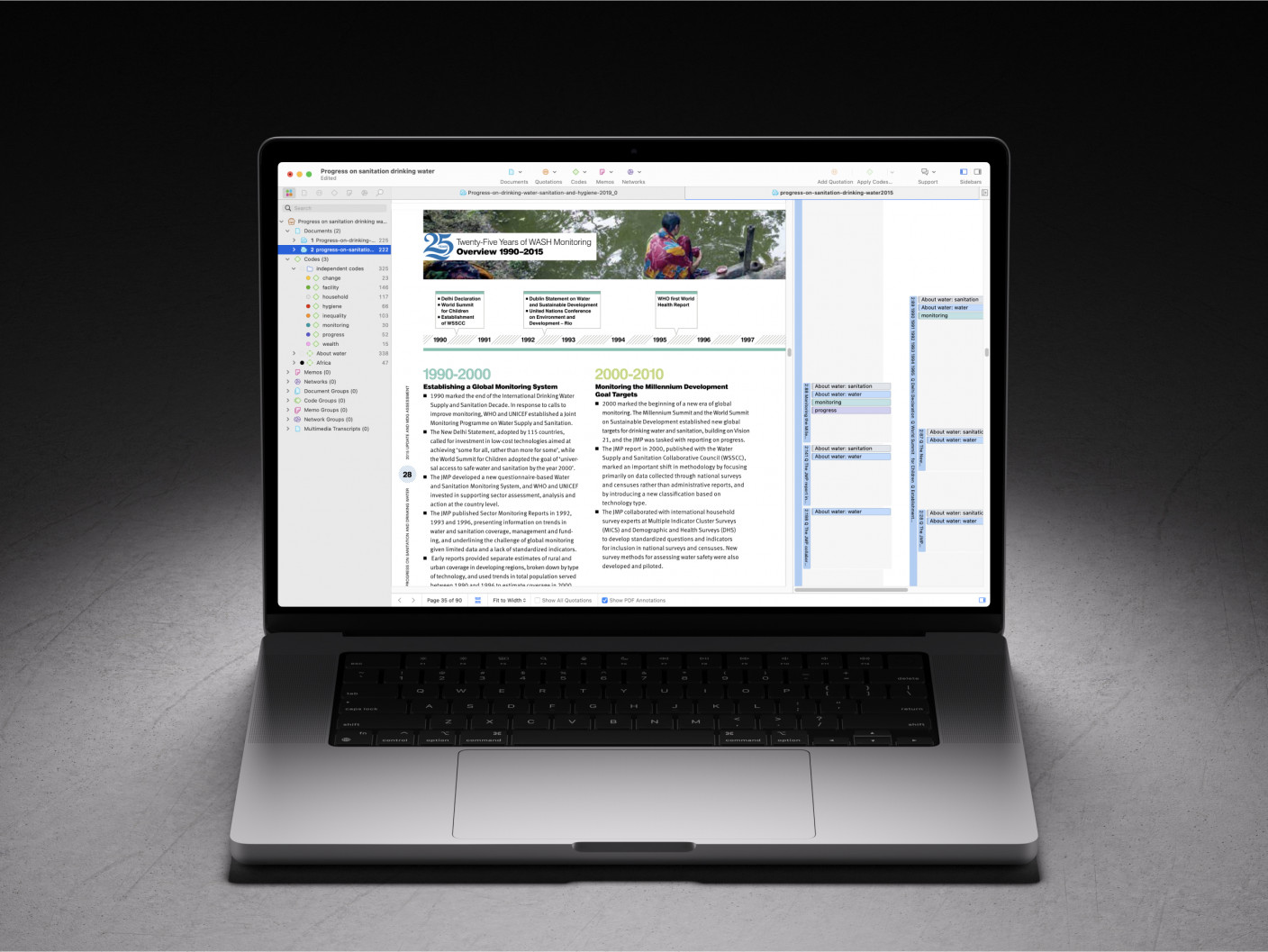
- Case study presentations — in-person, virtual, or pre-recorded, there are many times when a case study presentation comes in handy. For example, during client workshops, sales pitches, networking events, conferences, trade shows, etc.
- Dedicated website page — highlighting case study examples on your website is a great way to convert middle-on-the-funnel prospects. Google’s Think With Google case study section is a great example of a web case study design done right.

- Blog case studies — data-driven storytelling is a staunch way to stand apart from your competition by providing unique insights, no other brand can tell.
- Video case studies — video is a great medium for showcasing more complex business cases and celebrating customer success stories.
Once you decide on your case study format, the next step is collecting data and then translating it into a storyline. There are different case study methods and research approaches you can use to procure data.
But let’s say you already have all your facts straight and need to organize them in a clean copy for your presentation deck. Here’s how you should do it.

1. Identify the Problem
Every compelling case study research starts with a problem statement definition. While in business settings, there’s no need to explain your methodology in-depth; you should still open your presentation with a quick problem recap slide.
Be sure to mention:
- What’s the purpose of the case study? What will the audience learn?
- Set the scene. Explain the before, aka the problems someone was facing.
- Advertise the main issues and findings without highlighting specific details.
The above information should nicely fit in several paragraphs or 2-3 case study template slides
2. Explain the Solution
The bulk of your case study copy and presentation slides should focus on the provided solution(s). This is the time to speak at length about how the subject went from before to the glorious after.
Here are some writing prompts to help you articulate this better:
- State the subject’s main objective and goals. What outcomes were they after?
- Explain the main solution(s) provided. What was done? Why this, but not that?
- Mention if they tried any alternatives. Why did those work? Why were you better?
This part may take the longest to write. Don’t rush it and reiterate several times. Sprinkle in some powerful words and catchphrases to make your copy more compelling.
3. Collect Testimonials
Persuasive case studies feature the voice of customer (VoC) data — first-party testimonials and assessments of how well the solution works. These provide extra social proof and credibility to all the claims you are making.
So plan and schedule interviews with your subjects to collect their input and testimonials. Also, design your case study interview questions in a way that lets you obtain quantifiable results.
4. Package The Information in a Slide Deck
Once you have a rough first draft, try different business case templates and designs to see how these help structure all the available information.
As a rule of thumb, try to keep one big idea per slide. If you are talking about a solution, first present the general bullet points. Then give each solution a separate slide where you’ll provide more context and perhaps share some quantifiable results.
For example, if you look at case study presentation examples from AWS like this one about Stripe , you’ll notice that the slide deck has few texts and really focuses on the big picture, while the speaker provides extra context.
Need some extra case study presentation design help? Download our Business Case Study PowerPoint template with 100% editable slides.

Your spoken presentation (and public speaking skills ) are equally if not more important than the case study copy and slide deck. To make a strong business case, follow these quick techniques.
Focus on Telling a Great Story
A case study is a story of overcoming a challenge, and achieving something grand. Your delivery should reflect that. Step away from the standard “features => benefits” sales formula. Instead, make your customer the hero of the study. Describe the road they went through and how you’ve helped them succeed.
The premises of your story can be as simple as:
- Help with overcoming a hurdle
- Gaining major impact
- Reaching a new milestone
- Solving a persisting issue no one else code
Based on the above, create a clear story arc. Show where your hero started. Then explain what type of journey they went through. Inject some emotions into the mix to make your narrative more relatable and memorable.
Experiment with Copywriting Formulas
Copywriting is the art and science of organizing words into compelling and persuasive combinations that help readers retain the right ideas.
To ensure that the audience retains the right takeaways from your case study presentation, you can try using some of the classic copywriting formulas to structure your delivery. These include:
- AIDCA — short for A ttention, I nterest, D esire, C onviction, and A ction. First, grab the audience’s attention by addressing the major problem. Next, pique their interest with some teaser facts. Spark their desire by showing that you know the right way out. Then, show a conviction that you know how to solve the issue—finally, prompt follow-up action such as contacting you to learn more.
- PADS — is short for Problem, Agitation, Discredit, or Solution. This is more of a sales approach to case study narration. Again, you start with a problem, agitate about its importance, discredit why other solutions won’t cut it, and then present your option.
- 4Ps — short for P roblem, P romise, P roof, P roposal. This is a middle-ground option that prioritizes storytelling over hard pitches. Set the scene first with a problem. Then make a promise of how you can solve it. Show proof in the form of numbers, testimonials, and different scenarios. Round it up with a proposal for getting the same outcomes.
Take an Emotion-Inducing Perspective
The key to building a strong rapport with an audience is showing that you are one of them and fully understand what they are going through.
One of the ways to build this connection is by speaking from an emotion-inducing perspective. This is best illustrated with an example:
- A business owner went to the bank
- A business owner came into a bank branch
In the second case, the wording prompts listeners to paint a mental picture from the perspective of the bank employees — a role you’d like them to relate to. By placing your audience in the right visual perspective, you can make them more receptive to your pitches.

One common question that arises when creating a case study is determining its length. The length of a case study can vary depending on the complexity of the problem and the level of detail you want to provide. Here are some general guidelines to help you decide how long your case study should be:
- Concise and Informative: A good case study should be concise and to the point. Avoid unnecessary fluff and filler content. Focus on providing valuable information and insights.
- Tailor to Your Audience: Consider your target audience when deciding the length. If you’re presenting to a technical audience, you might include more in-depth technical details. For a non-technical audience, keep it more high-level and accessible.
- Cover Key Points: Ensure that your case study covers the key points effectively. These include the problem statement, the solution, and the outcomes. Provide enough information for the reader to understand the context and the significance of your case.
- Visuals: Visual elements such as charts, graphs, images, and diagrams can help convey information more effectively. Use visuals to supplement your written content and make complex information easier to understand.
- Engagement: Keep your audience engaged. A case study that is too long may lose the reader’s interest. Make sure the content is engaging and holds the reader’s attention throughout.
- Consider the Format: Depending on the format you choose (e.g., written document, presentation, video), the ideal length may vary. For written case studies, aim for a length that can be easily read in one sitting.
In general, a written case study for business purposes often falls in the range of 1,000 to 2,000 words. However, this is not a strict rule, and the length can be shorter or longer based on the factors mentioned above.
Our brain is wired to process images much faster than text. So when you are presenting a case study, always look for an opportunity to tie in some illustrations such as:
- A product demo/preview
- Processes chart
- Call-out quotes or numbers
- Custom illustrations or graphics
- Customer or team headshots
Use icons to minimize the volume of text. Also, opt for readable fonts that can look good in a smaller size too.
To better understand how to create an effective business case study, let’s explore some examples of successful case studies:
Apple Inc.: Apple’s case study on the launch of the iPhone is a classic example. It covers the problem of a changing mobile phone market, the innovative solution (the iPhone), and the outstanding outcomes, such as market dominance and increased revenue.
Tesla, Inc.: Tesla’s case study on electric vehicles and sustainable transportation is another compelling example. It addresses the problem of environmental concerns and the need for sustainable transportation solutions. The case study highlights Tesla’s electric cars as the solution and showcases the positive impact on reducing carbon emissions.
Amazon.com: Amazon’s case study on customer-centricity is a great illustration of how the company transformed the e-commerce industry. It discusses the problem of customer dissatisfaction with traditional retail, Amazon’s customer-focused approach as the solution, and the remarkable outcomes in terms of customer loyalty and market growth.
Coca-Cola: Coca-Cola’s case study on brand evolution is a valuable example. It outlines the challenge of adapting to changing consumer preferences and demographics. The case study demonstrates how Coca-Cola continually reinvented its brand to stay relevant and succeed in the global market.
Airbnb: Airbnb’s case study on the sharing economy is an intriguing example. It addresses the problem of travelers seeking unique and affordable accommodations. The case study presents Airbnb’s platform as the solution and highlights its impact on the hospitality industry and the sharing economy.
These examples showcase the diversity of case studies in the business world and how they effectively communicate problems, solutions, and outcomes. When creating your own business case study, use these examples as inspiration and tailor your approach to your specific industry and target audience.
Finally, practice your case study presentation several times — solo and together with your team — to collect feedback and make last-minute refinements!
1. Business Case Study PowerPoint Template

To efficiently create a Business Case Study it’s important to ask all the right questions and document everything necessary, therefore this PowerPoint Template will provide all the sections you need.
Use This Template
2. Medical Case Study PowerPoint Template

3. Medical Infographics PowerPoint Templates

4. Success Story PowerPoint Template

5. Detective Research PowerPoint Template

6. Animated Clinical Study PowerPoint Templates

Like this article? Please share
Business Intelligence, Business Planning, Business PowerPoint Templates, Content Marketing, Feasibility Study, Marketing, Marketing Strategy Filed under Business
Related Articles

Filed under Business • May 17th, 2024
How to Make a Transition Plan Presentation
Make change procedures in your company a successful experience by implementing transition plan presentations. A detailed guide with PPT templates.

Filed under Business • May 8th, 2024
Value Chain Analysis: A Guide for Presenters
Discover how to construct an actionable value chain analysis presentation to showcase to stakeholders with this detailed guide + templates.

Filed under Business • April 22nd, 2024
Setting SMART Goals – A Complete Guide (with Examples + Free Templates)
This guide on SMART goals introduces the concept, explains the definition and its meaning, along the main benefits of using the criteria for a business.
Leave a Reply
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- Case Study | Definition, Examples & Methods
Case Study | Definition, Examples & Methods
Published on 5 May 2022 by Shona McCombes . Revised on 30 January 2023.
A case study is a detailed study of a specific subject, such as a person, group, place, event, organisation, or phenomenon. Case studies are commonly used in social, educational, clinical, and business research.
A case study research design usually involves qualitative methods , but quantitative methods are sometimes also used. Case studies are good for describing , comparing, evaluating, and understanding different aspects of a research problem .
Table of contents
When to do a case study, step 1: select a case, step 2: build a theoretical framework, step 3: collect your data, step 4: describe and analyse the case.
A case study is an appropriate research design when you want to gain concrete, contextual, in-depth knowledge about a specific real-world subject. It allows you to explore the key characteristics, meanings, and implications of the case.
Case studies are often a good choice in a thesis or dissertation . They keep your project focused and manageable when you don’t have the time or resources to do large-scale research.
You might use just one complex case study where you explore a single subject in depth, or conduct multiple case studies to compare and illuminate different aspects of your research problem.
Prevent plagiarism, run a free check.
Once you have developed your problem statement and research questions , you should be ready to choose the specific case that you want to focus on. A good case study should have the potential to:
- Provide new or unexpected insights into the subject
- Challenge or complicate existing assumptions and theories
- Propose practical courses of action to resolve a problem
- Open up new directions for future research
Unlike quantitative or experimental research, a strong case study does not require a random or representative sample. In fact, case studies often deliberately focus on unusual, neglected, or outlying cases which may shed new light on the research problem.
If you find yourself aiming to simultaneously investigate and solve an issue, consider conducting action research . As its name suggests, action research conducts research and takes action at the same time, and is highly iterative and flexible.
However, you can also choose a more common or representative case to exemplify a particular category, experience, or phenomenon.
While case studies focus more on concrete details than general theories, they should usually have some connection with theory in the field. This way the case study is not just an isolated description, but is integrated into existing knowledge about the topic. It might aim to:
- Exemplify a theory by showing how it explains the case under investigation
- Expand on a theory by uncovering new concepts and ideas that need to be incorporated
- Challenge a theory by exploring an outlier case that doesn’t fit with established assumptions
To ensure that your analysis of the case has a solid academic grounding, you should conduct a literature review of sources related to the topic and develop a theoretical framework . This means identifying key concepts and theories to guide your analysis and interpretation.
There are many different research methods you can use to collect data on your subject. Case studies tend to focus on qualitative data using methods such as interviews, observations, and analysis of primary and secondary sources (e.g., newspaper articles, photographs, official records). Sometimes a case study will also collect quantitative data .
The aim is to gain as thorough an understanding as possible of the case and its context.
In writing up the case study, you need to bring together all the relevant aspects to give as complete a picture as possible of the subject.
How you report your findings depends on the type of research you are doing. Some case studies are structured like a standard scientific paper or thesis, with separate sections or chapters for the methods , results , and discussion .
Others are written in a more narrative style, aiming to explore the case from various angles and analyse its meanings and implications (for example, by using textual analysis or discourse analysis ).
In all cases, though, make sure to give contextual details about the case, connect it back to the literature and theory, and discuss how it fits into wider patterns or debates.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
McCombes, S. (2023, January 30). Case Study | Definition, Examples & Methods. Scribbr. Retrieved 14 May 2024, from https://www.scribbr.co.uk/research-methods/case-studies/
Is this article helpful?

Shona McCombes
Other students also liked, correlational research | guide, design & examples, a quick guide to experimental design | 5 steps & examples, descriptive research design | definition, methods & examples.
9 Creative Case Study Presentation Examples & Templates
Learn from proven case study presentation examples and best practices how to get creative, stand out, engage your audience, excite action, and drive results.
9 minute read

helped business professionals at:

Short answer
What makes a good case study presentation?
A good case study presentation has an engaging story, a clear structure, real data, visual aids, client testimonials, and a strong call to action. It informs and inspires, making the audience believe they can achieve similar results.
Dull case studies can cost you clients.
A boring case study presentation doesn't just risk putting your audience to sleep—it can actuallyl ead to lost sales and missed opportunities.
When your case study fails to inspire, it's your bottom line that suffers.
Interactive elements are the secret sauce for successful case study presentations.
They not only increase reader engagement by 22% but also lead to a whopping 41% more decks being read fully , proving that the winning deck is not a monologue but a conversation that involves the reader.
Let me show you shape your case studies into compelling narratives that hook your audience and drive revenue.
Let’s go!
How to create a case study presentation that drives results?
Crafting a case study presentation that truly drives results is about more than just data—it's about storytelling, engagement, and leading your audience down the sales funnel.
Here's how you can do it:
Tell a story: Each case study should follow a narrative arc. Start with the problem, introduce your solution, and showcase the results. Make it compelling and relatable.
Leverage data: Hard numbers build credibility. Use them to highlight your successes and reinforce your points.
Use visuals: Images, infographics, and videos can enhance engagement, making complex information more digestible and memorable.
Add interactive elements: Make your presentation a two-way journey. Tools like tabs and live data calculators can increase time spent on your deck by 22% and the number of full reads by 41% .
Finish with a strong call-to-action: Every good story needs a conclusion. Encourage your audience to take the next step in their buyer journey with a clear, persuasive call-to-action.
Visual representation of what a case study presentation should do:

How to write an engaging case study presentation?
Creating an engaging case study presentation involves strategic storytelling, understanding your audience, and sparking action.
In this guide, I'll cover the essentials to help you write a compelling narrative that drives results.
What is the best format for a business case study presentation?
4 best format types for a business case study presentation:
- Problem-solution case study
- Before-and-after case study
- Success story case study
- Interview style case study
Each style has unique strengths, so pick one that aligns best with your story and audience. For a deeper dive into these formats, check out our detailed blog post on case study format types .

What to include in a case study presentation?
An effective case study presentation contains 7 key elements:
- Introduction
- Company overview
- The problem/challenge
- Your solution
- Customer quotes/testimonials
To learn more about what should go in each of these sections, check out our post on what is a case study .
How to motivate readers to take action?
Based on BJ Fogg's behavior model , successful motivation involves 3 components:
This is all about highlighting the benefits. Paint a vivid picture of the transformative results achieved using your solution.
Use compelling data and emotive testimonials to amplify the desire for similar outcomes, therefore boosting your audience's motivation.
This refers to making the desired action easy to perform. Show how straightforward it is to implement your solution.
Use clear language, break down complex ideas, and reinforce the message that success is not just possible, but also readily achievable with your offering.
This is your powerful call-to-action (CTA), the spark that nudges your audience to take the next step. Ensure your CTA is clear, direct, and tied into the compelling narrative you've built.
It should leave your audience with no doubt about what to do next and why they should do it.
Here’s how you can do it with Storydoc:

How to adapt your presentation for your specific audience?
Every audience is different, and a successful case study presentation speaks directly to its audience's needs, concerns, and desires.
Understanding your audience is crucial. This involves researching their pain points, their industry jargon, their ambitions, and their fears.
Then, tailor your presentation accordingly. Highlight how your solution addresses their specific problems. Use language and examples they're familiar with. Show them how your product or service can help them reach their goals.
A case study presentation that's tailor-made for its audience is not just a presentation—it's a conversation that resonates, engages, and convinces.
How to design a great case study presentation?
A powerful case study presentation is not only about the story you weave—it's about the visual journey you create.
Let's navigate through the design strategies that can transform your case study presentation into a gripping narrative.
Add interactive elements
Static design has long been the traditional route for case study presentations—linear, unchanging, a one-size-fits-all solution.
However, this has been a losing approach for a while now. Static content is killing engagement, but interactive design will bring it back to life.
It invites your audience into an evolving, immersive experience, transforming them from passive onlookers into active participants.
Which of these presentations would you prefer to read?

Use narrated content design (scrollytelling)
Scrollytelling combines the best of scrolling and storytelling. This innovative approach offers an interactive narrated journey controlled with a simple scroll.
It lets you break down complex content into manageable chunks and empowers your audience to control their reading pace.
To make this content experience available to everyone, our founder, Itai Amoza, collaborated with visualization scientist Prof. Steven Franconeri to incorporate scrollytelling into Storydoc.
This collaboration led to specialized storytelling slides that simplify content and enhance engagement (which you can find and use in Storydoc).
Here’s an example of Storydoc scrollytelling:

Bring your case study to life with multimedia
Multimedia brings a dynamic dimension to your presentation. Video testimonials lend authenticity and human connection. Podcast interviews add depth and diversity, while live graphs offer a visually captivating way to represent data.
Each media type contributes to a richer, more immersive narrative that keeps your audience engaged from beginning to end.
Prioritize mobile-friendly design
In an increasingly mobile world, design must adapt. Avoid traditional, non-responsive formats like PPT, PDF, and Word.
Opt for a mobile-optimized design that guarantees your presentation is always at its best, regardless of the device.
As a significant chunk of case studies are opened on mobile, this ensures wider accessibility and improved user experience , demonstrating respect for your audience's viewing preferences.
Here’s what a traditional static presentation looks like as opposed to a responsive deck:

Streamline the design process
Creating a case study presentation usually involves wrestling with an AI website builder .
It's a dance that often needs several partners - designers to make it look good, developers to make it work smoothly, and plenty of time to bring it all together.
Building, changing, and personalizing your case study can feel like you're climbing a mountain when all you need is to cross a hill.
By switching to Storydoc’s interactive case study creator , you won’t need a tech guru or a design whizz, just your own creativity.
You’ll be able to create a customized, interactive presentation for tailored use in sales prospecting or wherever you need it without the headache of mobilizing your entire team.
Storydoc will automatically adjust any change to your presentation layout, so you can’t break the design even if you tried.

Case study presentation examples that engage readers
Let’s take a deep dive into some standout case studies.
These examples go beyond just sharing information – they're all about captivating and inspiring readers. So, let’s jump in and uncover the secret behind what makes them so effective.
What makes this deck great:
- A video on the cover slide will cause 32% more people to interact with your case study .
- The running numbers slide allows you to present the key results your solution delivered in an easily digestible way.
- The ability to include 2 smart CTAs gives readers the choice between learning more about your solution and booking a meeting with you directly.
Light mode case study
- The ‘read more’ button is perfect if you want to present a longer case without overloading readers with walls of text.
- The timeline slide lets you present your solution in the form of a compelling narrative.
- A combination of text-based and visual slides allows you to add context to the main insights.
Marketing case study
- Tiered slides are perfect for presenting multiple features of your solution, particularly if they’re relevant to several use cases.
- Easily customizable slides allow you to personalize your case study to specific prospects’ needs and pain points.
- The ability to embed videos makes it possible to show your solution in action instead of trying to describe it purely with words.
UX case study
- Various data visualization components let you present hard data in a way that’s easier to understand and follow.
- The option to hide text under a 'Read more' button is great if you want to include research findings or present a longer case study.
- Content segmented using tabs , which is perfect if you want to describe different user research methodologies without overwhelming your audience.
Business case study
- Library of data visualization elements to choose from comes in handy for more data-heavy case studies.
- Ready-to-use graphics and images which can easily be replaced using our AI assistant or your own files.
- Information on the average reading time in the cover reduces bounce rate by 24% .
Modern case study
- Dynamic variables let you personalize your deck at scale in just a few clicks.
- Logo placeholder that can easily be replaced with your prospect's logo for an added personal touch.
- Several text placeholders that can be tweaked to perfection with the help of our AI assistant to truly drive your message home.
Real estate case study
- Plenty of image placeholders that can be easily edited in a couple of clicks to let you show photos of your most important listings.
- Data visualization components can be used to present real estate comps or the value of your listings for a specific time period.
- Interactive slides guide your readers through a captivating storyline, which is key in a highly-visual industry like real estate .
Medical case study
- Image and video placeholders are perfect for presenting your solution without relying on complex medical terminology.
- The ability to hide text under an accordion allows you to include research or clinical trial findings without overwhelming prospects with too much information.
- Clean interactive design stands out in a sea of old-school medical case studies, making your deck more memorable for prospective clients.
Dark mode case study
- The timeline slide is ideal for guiding readers through an attention-grabbing storyline or explaining complex processes.
- Dynamic layout with multiple image and video placeholders that can be replaced in a few clicks to best reflect the nature of your business.
- Testimonial slides that can easily be customized with quotes by your past customers to legitimize your solution in the eyes of prospects.
Grab a case study presentation template
Creating an effective case study presentation is not just about gathering data and organizing it in a document. You need to weave a narrative, create an impact, and most importantly, engage your reader.
So, why start from zero when interactive case study templates can take you halfway up?
Instead of wrestling with words and designs, pick a template that best suits your needs, and watch your data transform into an engaging and inspiring story.

Hi, I'm Dominika, Content Specialist at Storydoc. As a creative professional with experience in fashion, I'm here to show you how to amplify your brand message through the power of storytelling and eye-catching visuals.
Found this post useful?
Subscribe to our monthly newsletter.
Get notified as more awesome content goes live.
(No spam, no ads, opt-out whenever)
You've just joined an elite group of people that make the top performing 1% of sales and marketing collateral.

Create your best pitch deck to date.
Stop losing opportunities to ineffective presentations. Your new amazing deck is one click away!
We use essential cookies to make Venngage work. By clicking “Accept All Cookies”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts.
Manage Cookies
Cookies and similar technologies collect certain information about how you’re using our website. Some of them are essential, and without them you wouldn’t be able to use Venngage. But others are optional, and you get to choose whether we use them or not.
Strictly Necessary Cookies
These cookies are always on, as they’re essential for making Venngage work, and making it safe. Without these cookies, services you’ve asked for can’t be provided.
Show cookie providers
- Google Login
Functionality Cookies
These cookies help us provide enhanced functionality and personalisation, and remember your settings. They may be set by us or by third party providers.
Performance Cookies
These cookies help us analyze how many people are using Venngage, where they come from and how they're using it. If you opt out of these cookies, we can’t get feedback to make Venngage better for you and all our users.
- Google Analytics
Targeting Cookies
These cookies are set by our advertising partners to track your activity and show you relevant Venngage ads on other sites as you browse the internet.
- Google Tag Manager
- Infographics
- Daily Infographics
- Popular Templates
- Accessibility
- Graphic Design
- Graphs and Charts
- Data Visualization
- Human Resources
- Beginner Guides
Blog Graphic Design 15+ Professional Case Study Examples [Design Tips + Templates]
15+ Professional Case Study Examples [Design Tips + Templates]
Written by: Alice Corner Jan 12, 2023

Have you ever bought something — within the last 10 years or so — without reading its reviews or without a recommendation or prior experience of using it?
If the answer is no — or at least, rarely — you get my point.
Positive reviews matter for selling to regular customers, and for B2B or SaaS businesses, detailed case studies are important too.
Wondering how to craft a compelling case study ? No worries—I’ve got you covered with 15 marketing case study templates , helpful tips, and examples to ensure your case study converts effectively.
Click to jump ahead:
- What is a Case Study?
Business Case Study Examples
Simple case study examples.
- Marketing Case Study Examples
Sales Case Study Examples
- Case Study FAQs
What is a case study?
A case study is an in-depth, detailed analysis of a specific real-world situation. For example, a case study can be about an individual, group, event, organization, or phenomenon. The purpose of a case study is to understand its complexities and gain insights into a particular instance or situation.
In the context of a business, however, case studies take customer success stories and explore how they use your product to help them achieve their business goals.

As well as being valuable marketing tools , case studies are a good way to evaluate your product as it allows you to objectively examine how others are using it.
It’s also a good way to interview your customers about why they work with you.
Related: What is a Case Study? [+6 Types of Case Studies]
Marketing Case Study Template
A marketing case study showcases how your product or services helped potential clients achieve their business goals. You can also create case studies of internal, successful marketing projects. A marketing case study typically includes:
- Company background and history
- The challenge
- How you helped
- Specific actions taken
- Visuals or Data
- Client testimonials
Here’s an example of a marketing case study template:

Whether you’re a B2B or B2C company, business case studies can be a powerful resource to help with your sales, marketing, and even internal departmental awareness.
Business and business management case studies should encompass strategic insights alongside anecdotal and qualitative findings, like in the business case study examples below.
Conduct a B2B case study by researching the company holistically
When it comes to writing a case study, make sure you approach the company holistically and analyze everything from their social media to their sales.
Think about every avenue your product or service has been of use to your case study company, and ask them about the impact this has had on their wider company goals.

In business case study examples like the one above, we can see that the company has been thought about holistically simply by the use of icons.
By combining social media icons with icons that show in-person communication we know that this is a well-researched and thorough case study.
This case study report example could also be used within an annual or end-of-year report.
Highlight the key takeaway from your marketing case study
To create a compelling case study, identify the key takeaways from your research. Use catchy language to sum up this information in a sentence, and present this sentence at the top of your page.
This is “at a glance” information and it allows people to gain a top-level understanding of the content immediately.

You can use a large, bold, contrasting font to help this information stand out from the page and provide interest.
Learn how to choose fonts effectively with our Venngage guide and once you’ve done that.
Upload your fonts and brand colors to Venngage using the My Brand Kit tool and see them automatically applied to your designs.
The heading is the ideal place to put the most impactful information, as this is the first thing that people will read.
In this example, the stat of “Increase[d] lead quality by 90%” is used as the header. It makes customers want to read more to find out how exactly lead quality was increased by such a massive amount.

If you’re conducting an in-person interview, you could highlight a direct quote or insight provided by your interview subject.
Pick out a catchy sentence or phrase, or the key piece of information your interview subject provided and use that as a way to draw a potential customer in.
Use charts to visualize data in your business case studies
Charts are an excellent way to visualize data and to bring statistics and information to life. Charts make information easier to understand and to illustrate trends or patterns.
Making charts is even easier with Venngage.
In this consulting case study example, we can see that a chart has been used to demonstrate the difference in lead value within the Lead Elves case study.
Adding a chart here helps break up the information and add visual value to the case study.

Using charts in your case study can also be useful if you’re creating a project management case study.
You could use a Gantt chart or a project timeline to show how you have managed the project successfully.

Use direct quotes to build trust in your marketing case study
To add an extra layer of authenticity you can include a direct quote from your customer within your case study.
According to research from Nielsen , 92% of people will trust a recommendation from a peer and 70% trust recommendations even if they’re from somebody they don’t know.

So if you have a customer or client who can’t stop singing your praises, make sure you get a direct quote from them and include it in your case study.
You can either lift part of the conversation or interview, or you can specifically request a quote. Make sure to ask for permission before using the quote.

This design uses a bright contrasting speech bubble to show that it includes a direct quote, and helps the quote stand out from the rest of the text.
This will help draw the customer’s attention directly to the quote, in turn influencing them to use your product or service.
Less is often more, and this is especially true when it comes to creating designs. Whilst you want to create a professional-looking, well-written and design case study – there’s no need to overcomplicate things.
These simple case study examples show that smart clean designs and informative content can be an effective way to showcase your successes.
Use colors and fonts to create a professional-looking case study
Business case studies shouldn’t be boring. In fact, they should be beautifully and professionally designed.
This means the normal rules of design apply. Use fonts, colors, and icons to create an interesting and visually appealing case study.
In this case study example, we can see how multiple fonts have been used to help differentiate between the headers and content, as well as complementary colors and eye-catching icons.

Marketing case study examples
Marketing case studies are incredibly useful for showing your marketing successes. Every successful marketing campaign relies on influencing a consumer’s behavior, and a great case study can be a great way to spotlight your biggest wins.
In the marketing case study examples below, a variety of designs and techniques to create impactful and effective case studies.
Show off impressive results with a bold marketing case study
Case studies are meant to show off your successes, so make sure you feature your positive results prominently. Using bold and bright colors as well as contrasting shapes, large bold fonts, and simple icons is a great way to highlight your wins.
In well-written case study examples like the one below, the big wins are highlighted on the second page with a bright orange color and are highlighted in circles.
Making the important data stand out is especially important when attracting a prospective customer with marketing case studies.

Use a simple but clear layout in your case study
Using a simple layout in your case study can be incredibly effective, like in the example of a case study below.
Keeping a clean white background, and using slim lines to help separate the sections is an easy way to format your case study.
Making the information clear helps draw attention to the important results, and it helps improve the accessibility of the design .
Business case study examples like this would sit nicely within a larger report, with a consistent layout throughout.

Use visuals and icons to create an engaging and branded business case study
Nobody wants to read pages and pages of text — and that’s why Venngage wants to help you communicate your ideas visually.
Using icons, graphics, photos, or patterns helps create a much more engaging design.
With this Blue Cap case study icons, colors, and impactful pattern designs have been used to create an engaging design that catches your eye.

Use a monochromatic color palette to create a professional and clean case study
Let your research shine by using a monochromatic and minimalistic color palette.
By sticking to one color, and leaving lots of blank space you can ensure your design doesn’t distract a potential customer from your case study content.

In this case study on Polygon Media, the design is simple and professional, and the layout allows the prospective customer to follow the flow of information.
The gradient effect on the left-hand column helps break up the white background and adds an interesting visual effect.

Did you know you can generate an accessible color palette with Venngage? Try our free accessible color palette generator today and create a case study that delivers and looks pleasant to the eye:

Add long term goals in your case study
When creating a case study it’s a great idea to look at both the short term and the long term goals of the company to gain the best understanding possible of the insights they provide.
Short-term goals will be what the company or person hopes to achieve in the next few months, and long-term goals are what the company hopes to achieve in the next few years.
Check out this modern pattern design example of a case study below:

In this case study example, the short and long-term goals are clearly distinguished by light blue boxes and placed side by side so that they are easy to compare.

Use a strong introductory paragraph to outline the overall strategy and goals before outlining the specific short-term and long-term goals to help with clarity.
This strategy can also be handy when creating a consulting case study.
Use data to make concrete points about your sales and successes
When conducting any sort of research stats, facts, and figures are like gold dust (aka, really valuable).
Being able to quantify your findings is important to help understand the information fully. Saying sales increased 10% is much more effective than saying sales increased.
While sales dashboards generally tend it make it all about the numbers and charts, in sales case study examples, like this one, the key data and findings can be presented with icons. This contributes to the potential customer’s better understanding of the report.
They can clearly comprehend the information and it shows that the case study has been well researched.

Use emotive, persuasive, or action based language in your marketing case study
Create a compelling case study by using emotive, persuasive and action-based language when customizing your case study template.

In this well-written case study example, we can see that phrases such as “Results that Speak Volumes” and “Drive Sales” have been used.
Using persuasive language like you would in a blog post. It helps inspire potential customers to take action now.

Keep your potential customers in mind when creating a customer case study for marketing
82% of marketers use case studies in their marketing because it’s such an effective tool to help quickly gain customers’ trust and to showcase the potential of your product.
Why are case studies such an important tool in content marketing?
By writing a case study you’re telling potential customers that they can trust you because you’re showing them that other people do.
Not only that, but if you have a SaaS product, business case studies are a great way to show how other people are effectively using your product in their company.
In this case study, Network is demonstrating how their product has been used by Vortex Co. with great success; instantly showing other potential customers that their tool works and is worth using.

Related: 10+ Case Study Infographic Templates That Convert
Case studies are particularly effective as a sales technique.
A sales case study is like an extended customer testimonial, not only sharing opinions of your product – but showcasing the results you helped your customer achieve.
Make impactful statistics pop in your sales case study
Writing a case study doesn’t mean using text as the only medium for sharing results.
You should use icons to highlight areas of your research that are particularly interesting or relevant, like in this example of a case study:

Icons are a great way to help summarize information quickly and can act as visual cues to help draw the customer’s attention to certain areas of the page.
In some of the business case study examples above, icons are used to represent the impressive areas of growth and are presented in a way that grabs your attention.
Use high contrast shapes and colors to draw attention to key information in your sales case study
Help the key information stand out within your case study by using high contrast shapes and colors.
Use a complementary or contrasting color, or use a shape such as a rectangle or a circle for maximum impact.

This design has used dark blue rectangles to help separate the information and make it easier to read.
Coupled with icons and strong statistics, this information stands out on the page and is easily digestible and retainable for a potential customer.

Case Study Examples Summary
Once you have created your case study, it’s best practice to update your examples on a regular basis to include up-to-date statistics, data, and information.
You should update your business case study examples often if you are sharing them on your website .
It’s also important that your case study sits within your brand guidelines – find out how Venngage’s My Brand Kit tool can help you create consistently branded case study templates.
Case studies are important marketing tools – but they shouldn’t be the only tool in your toolbox. Content marketing is also a valuable way to earn consumer trust.
Case Study FAQ
Why should you write a case study.
Case studies are an effective marketing technique to engage potential customers and help build trust.
By producing case studies featuring your current clients or customers, you are showcasing how your tool or product can be used. You’re also showing that other people endorse your product.
In addition to being a good way to gather positive testimonials from existing customers , business case studies are good educational resources and can be shared amongst your company or team, and used as a reference for future projects.
How should you write a case study?
To create a great case study, you should think strategically. The first step, before starting your case study research, is to think about what you aim to learn or what you aim to prove.
You might be aiming to learn how a company makes sales or develops a new product. If this is the case, base your questions around this.
You can learn more about writing a case study from our extensive guide.
Related: How to Present a Case Study like a Pro (With Examples)
Some good questions you could ask would be:
- Why do you use our tool or service?
- How often do you use our tool or service?
- What does the process of using our product look like to you?
- If our product didn’t exist, what would you be doing instead?
- What is the number one benefit you’ve found from using our tool?
You might also enjoy:
- 12 Essential Consulting Templates For Marketing, Planning and Branding
- Best Marketing Strategies for Consultants and Freelancers in 2019 [Study + Infographic]
Discover popular designs

Infographic maker

Brochure maker

White paper online

Newsletter creator

Flyer maker
Timeline maker

Letterhead maker
Mind map maker

Ebook maker
- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Best Family Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Guided Meditations
- Verywell Mind Insights
- 2024 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support
What Is a Case Study?
Weighing the pros and cons of this method of research
Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
:max_bytes(150000):strip_icc():format(webp)/IMG_9791-89504ab694d54b66bbd72cb84ffb860e.jpg "how to show case study")
Cara Lustik is a fact-checker and copywriter.
:max_bytes(150000):strip_icc():format(webp)/Cara-Lustik-1000-77abe13cf6c14a34a58c2a0ffb7297da.jpg "how to show case study")
Verywell / Colleen Tighe
- Pros and Cons
What Types of Case Studies Are Out There?
Where do you find data for a case study, how do i write a psychology case study.
A case study is an in-depth study of one person, group, or event. In a case study, nearly every aspect of the subject's life and history is analyzed to seek patterns and causes of behavior. Case studies can be used in many different fields, including psychology, medicine, education, anthropology, political science, and social work.
The point of a case study is to learn as much as possible about an individual or group so that the information can be generalized to many others. Unfortunately, case studies tend to be highly subjective, and it is sometimes difficult to generalize results to a larger population.
While case studies focus on a single individual or group, they follow a format similar to other types of psychology writing. If you are writing a case study, we got you—here are some rules of APA format to reference.
At a Glance
A case study, or an in-depth study of a person, group, or event, can be a useful research tool when used wisely. In many cases, case studies are best used in situations where it would be difficult or impossible for you to conduct an experiment. They are helpful for looking at unique situations and allow researchers to gather a lot of˜ information about a specific individual or group of people. However, it's important to be cautious of any bias we draw from them as they are highly subjective.
What Are the Benefits and Limitations of Case Studies?
A case study can have its strengths and weaknesses. Researchers must consider these pros and cons before deciding if this type of study is appropriate for their needs.
One of the greatest advantages of a case study is that it allows researchers to investigate things that are often difficult or impossible to replicate in a lab. Some other benefits of a case study:
- Allows researchers to capture information on the 'how,' 'what,' and 'why,' of something that's implemented
- Gives researchers the chance to collect information on why one strategy might be chosen over another
- Permits researchers to develop hypotheses that can be explored in experimental research
On the other hand, a case study can have some drawbacks:
- It cannot necessarily be generalized to the larger population
- Cannot demonstrate cause and effect
- It may not be scientifically rigorous
- It can lead to bias
Researchers may choose to perform a case study if they want to explore a unique or recently discovered phenomenon. Through their insights, researchers develop additional ideas and study questions that might be explored in future studies.
It's important to remember that the insights from case studies cannot be used to determine cause-and-effect relationships between variables. However, case studies may be used to develop hypotheses that can then be addressed in experimental research.
Case Study Examples
There have been a number of notable case studies in the history of psychology. Much of Freud's work and theories were developed through individual case studies. Some great examples of case studies in psychology include:
- Anna O : Anna O. was a pseudonym of a woman named Bertha Pappenheim, a patient of a physician named Josef Breuer. While she was never a patient of Freud's, Freud and Breuer discussed her case extensively. The woman was experiencing symptoms of a condition that was then known as hysteria and found that talking about her problems helped relieve her symptoms. Her case played an important part in the development of talk therapy as an approach to mental health treatment.
- Phineas Gage : Phineas Gage was a railroad employee who experienced a terrible accident in which an explosion sent a metal rod through his skull, damaging important portions of his brain. Gage recovered from his accident but was left with serious changes in both personality and behavior.
- Genie : Genie was a young girl subjected to horrific abuse and isolation. The case study of Genie allowed researchers to study whether language learning was possible, even after missing critical periods for language development. Her case also served as an example of how scientific research may interfere with treatment and lead to further abuse of vulnerable individuals.
Such cases demonstrate how case research can be used to study things that researchers could not replicate in experimental settings. In Genie's case, her horrific abuse denied her the opportunity to learn a language at critical points in her development.
This is clearly not something researchers could ethically replicate, but conducting a case study on Genie allowed researchers to study phenomena that are otherwise impossible to reproduce.
There are a few different types of case studies that psychologists and other researchers might use:
- Collective case studies : These involve studying a group of individuals. Researchers might study a group of people in a certain setting or look at an entire community. For example, psychologists might explore how access to resources in a community has affected the collective mental well-being of those who live there.
- Descriptive case studies : These involve starting with a descriptive theory. The subjects are then observed, and the information gathered is compared to the pre-existing theory.
- Explanatory case studies : These are often used to do causal investigations. In other words, researchers are interested in looking at factors that may have caused certain things to occur.
- Exploratory case studies : These are sometimes used as a prelude to further, more in-depth research. This allows researchers to gather more information before developing their research questions and hypotheses .
- Instrumental case studies : These occur when the individual or group allows researchers to understand more than what is initially obvious to observers.
- Intrinsic case studies : This type of case study is when the researcher has a personal interest in the case. Jean Piaget's observations of his own children are good examples of how an intrinsic case study can contribute to the development of a psychological theory.
The three main case study types often used are intrinsic, instrumental, and collective. Intrinsic case studies are useful for learning about unique cases. Instrumental case studies help look at an individual to learn more about a broader issue. A collective case study can be useful for looking at several cases simultaneously.
The type of case study that psychology researchers use depends on the unique characteristics of the situation and the case itself.
There are a number of different sources and methods that researchers can use to gather information about an individual or group. Six major sources that have been identified by researchers are:
- Archival records : Census records, survey records, and name lists are examples of archival records.
- Direct observation : This strategy involves observing the subject, often in a natural setting . While an individual observer is sometimes used, it is more common to utilize a group of observers.
- Documents : Letters, newspaper articles, administrative records, etc., are the types of documents often used as sources.
- Interviews : Interviews are one of the most important methods for gathering information in case studies. An interview can involve structured survey questions or more open-ended questions.
- Participant observation : When the researcher serves as a participant in events and observes the actions and outcomes, it is called participant observation.
- Physical artifacts : Tools, objects, instruments, and other artifacts are often observed during a direct observation of the subject.
If you have been directed to write a case study for a psychology course, be sure to check with your instructor for any specific guidelines you need to follow. If you are writing your case study for a professional publication, check with the publisher for their specific guidelines for submitting a case study.
Here is a general outline of what should be included in a case study.
Section 1: A Case History
This section will have the following structure and content:
Background information : The first section of your paper will present your client's background. Include factors such as age, gender, work, health status, family mental health history, family and social relationships, drug and alcohol history, life difficulties, goals, and coping skills and weaknesses.
Description of the presenting problem : In the next section of your case study, you will describe the problem or symptoms that the client presented with.
Describe any physical, emotional, or sensory symptoms reported by the client. Thoughts, feelings, and perceptions related to the symptoms should also be noted. Any screening or diagnostic assessments that are used should also be described in detail and all scores reported.
Your diagnosis : Provide your diagnosis and give the appropriate Diagnostic and Statistical Manual code. Explain how you reached your diagnosis, how the client's symptoms fit the diagnostic criteria for the disorder(s), or any possible difficulties in reaching a diagnosis.
Section 2: Treatment Plan
This portion of the paper will address the chosen treatment for the condition. This might also include the theoretical basis for the chosen treatment or any other evidence that might exist to support why this approach was chosen.
- Cognitive behavioral approach : Explain how a cognitive behavioral therapist would approach treatment. Offer background information on cognitive behavioral therapy and describe the treatment sessions, client response, and outcome of this type of treatment. Make note of any difficulties or successes encountered by your client during treatment.
- Humanistic approach : Describe a humanistic approach that could be used to treat your client, such as client-centered therapy . Provide information on the type of treatment you chose, the client's reaction to the treatment, and the end result of this approach. Explain why the treatment was successful or unsuccessful.
- Psychoanalytic approach : Describe how a psychoanalytic therapist would view the client's problem. Provide some background on the psychoanalytic approach and cite relevant references. Explain how psychoanalytic therapy would be used to treat the client, how the client would respond to therapy, and the effectiveness of this treatment approach.
- Pharmacological approach : If treatment primarily involves the use of medications, explain which medications were used and why. Provide background on the effectiveness of these medications and how monotherapy may compare with an approach that combines medications with therapy or other treatments.
This section of a case study should also include information about the treatment goals, process, and outcomes.
When you are writing a case study, you should also include a section where you discuss the case study itself, including the strengths and limitiations of the study. You should note how the findings of your case study might support previous research.
In your discussion section, you should also describe some of the implications of your case study. What ideas or findings might require further exploration? How might researchers go about exploring some of these questions in additional studies?
Need More Tips?
Here are a few additional pointers to keep in mind when formatting your case study:
- Never refer to the subject of your case study as "the client." Instead, use their name or a pseudonym.
- Read examples of case studies to gain an idea about the style and format.
- Remember to use APA format when citing references .
Crowe S, Cresswell K, Robertson A, Huby G, Avery A, Sheikh A. The case study approach . BMC Med Res Methodol . 2011;11:100.
Crowe S, Cresswell K, Robertson A, Huby G, Avery A, Sheikh A. The case study approach . BMC Med Res Methodol . 2011 Jun 27;11:100. doi:10.1186/1471-2288-11-100
Gagnon, Yves-Chantal. The Case Study as Research Method: A Practical Handbook . Canada, Chicago Review Press Incorporated DBA Independent Pub Group, 2010.
Yin, Robert K. Case Study Research and Applications: Design and Methods . United States, SAGE Publications, 2017.
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
16 Important Ways to Use Case Studies in Your Marketing
Updated: September 08, 2020
Published: July 30, 2020
When you're thinking about investing in a product or service, what's the first thing you do?

Usually, it’s one or both of the following: You'll likely ask your friends whether they've tried the product or service, and if they have, whether they would recommend it. You'll also probably do some online research to see what others are saying about said product or service. Nowadays, 90% of consumers used the internet to find a local business in the last year , and 82% of consumers read online reviews. This shows that the majority of people are looking to peers to make a purchasing decision. Most customers know that a little online research could spare them from a bad experience and poor investment of your budget.

What Is a Marketing Case Study?
A case study is the analysis of a particular instance (or "case") of something to demonstrate quantifiable results as a result of the application of something. In marketing, case studies are used as social proof — to provide buyers with the context to determine whether they're making a good choice.
A marketing case study aims to persuade that a process, product, or service can solve a problem. Why? Because it has done so in the past. By including the quantitative and qualitative outcomes of the study, it appeals to logic while painting a picture of what success looks like for the buyer. Both of which can be powerful motivators and objection removers.
Why Use Case Studies?
In essence, case studies are an invaluable asset when it comes to establishing proof that what you're offering is valuable and of good quality.
According to HubSpot's State of Marketing Report 2020 , 13% of marketers name case studies as one of the primary forms of media used within their content strategy. This makes them the fifth most popular type of content, outshined only by visual content, blogs, and ebooks.

Okay, so you know case studies work. The question is, how do they work? And how can you squeeze the most value out of them?
When to Use a Case Study
Here are the ways you can market your case studies to get the most out of them.
As a Marketing or Sales Asset
1. use a case study template to create pdfs for email or downloads . .
Do not underestimate the value of providing social proof at just the right time in order to add value and earn their business. Case studies are extremely effective in the consideration stage of the buyer's journey when they are actively comparing solutions and providers to solve a problem they're experiencing.
For this reason, case studies in an independent PDF format can be helpful in both marketing and sales. Marketers can use these PDFs as downloads in web content or email campaigns. Sales reps can utilize these assets in demonstrations, in a follow-up, or to overcome objections.

The easiest way to create PDF case studies is by using a case study template . Doing so can decrease the amount of time you spend creating and designing your case study without sacrificing aesthetics. In addition, you can ensure that all your case studies follow a similar branded format.
We've created a great case study template (and kit!) that's already locked and loaded for you to use. All you have to do is input your own text and change the fonts and colors to fit your brand. You can download it here .
On Your Website
2. have a dedicated case studies page..
You should have a webpage exclusively for housing your case studies. Whether you call this page "Case Studies, "Success Studies," or "Examples of Our Work," be sure it's easy for visitors to find.
Structure on that page is key: Initial challenges are clear for each case, as well as the goals, process, and results.
Get Inspired: Google’s Think With Google is an example of a really well structured case study page. The copy is engaging, as are the goals, approach, and results.

3. Put case studies on your home page.
Give website visitors every chance you can to stumble upon evidence of happy customers. Your home page is the perfect place to do this.
There are a number of ways you can include case studies on your homepage. Here are a few examples:
- Customer quotes/testimonials
- A call-to-action (CTA) to view specific case studies
- A slide-in CTA that links to a case study
- A CTA leading to your case studies page
Get Inspired: Theresumator.com incorporates testimonials onto their homepage to strengthen their value proposition.

Bonus Tip: Get personal.
Marketing gurus across the world agree that personalised marketing is the future . You can make your case studies more powerful if you find ways to make them “match” the website visitors that are important to you.
People react to familiarity -- for instance, presenting someone from London with a case study from New York may not resonate as well as if you displayed a case study from the U.K. Or you could choose to tailor case studies by industry or company size to the visitor. At HubSpot, we call this "smart content."
Get Inspired: To help explain smart content, have a look at the example below. Here, we wanted to test whether including testimonials on landing pages influenced conversion rates in the U.K. The landing page on the left is the default landing page shown to visitors from non-U.K. IP addresses. For the landing page on the right, we used smart content to show testimonials to visitors coming from U.K. IP addresses.

4. Implement slide-in CTAs.
Pop-ups have a reputation for being annoying, but there are ways to implement that that won't irk your website visitors. These CTAs don't have to be huge, glaring pop-ups -- instead, relevant but discreet slide-in CTAs can work really well.
For example, why not test out a slide-in CTA on one of your product pages, with a link to a case study that profiles a customer who's seen great results using that product?
Get Inspired: If you need some help on creating sliders for your website, check out this tutorial on creating slide-in CTAs .
5. Write blog posts about your case studies.
Once you publish a case study, the next logical step would be to write a blog post about it to expose your audience to it. The trick is to write about the case study in a way that identifies with your audience’s needs. So rather than titling your post “Company X: A Case Study," you might write about a specific hurdle, issue, or challenge the company overcame, and then use that company's case study to illustrate how the issues were addressed. It's important not to center the blog post around your company, product, or service -- instead, the customer’s challenges and how they were overcome should take centre stage.
For example, if we had a case study that showed how one customer generated twice as many leads as a result of our marketing automation tool, our blog post might be something along the lines of: "How to Double Lead Flow With Marketing Automation [Case Study]." The blog post would then comprise of a mix of stats, practical tips, as well as some illustrative examples from our case study.
Get Inspired: Check out this great example of a blog post from Moz , titled "How to Build Links to Your Blog – A Case Study."
6. Create videos from case studies.
Internet services are improving all the time, and as a result, people are consuming more and more video content. Prospects could be more likely to watch a video than they are to read a lengthy case study. If you have the budget, creating videos of your case studies is a really powerful way to communicate your value proposition.
Get Inspired: Check out one of our many video testimonials for some ideas on how to approach your own videos.
7. Use case studies on relevant landing pages.
Once you complete a case study, you'll have a bank of quotes and results you can pull from. Including quotes on product pages is especially interesting. If website visitors are reading your product pages, they are in a "consideration" mindset, meaning they are actively researching your products, perhaps with an intent to buy. Having customer quotes placed strategically on these pages is a great way to push them over the line and further down the funnel.
These quotes should be measured, results-based snippets, such as, “XX resulted in a 70% increase in blog subscribers in less an 6 months” rather than, “We are proud to be customers of XX, they really look after us."
Get Inspired: I really like the way HR Software company Workday incorporates video and testimonials into its solutions pages.

Off Your Website
8. post about case studies on social media..
Case studies make for perfect social sharing material. Here are a few examples of how you can leverage them on social:
- Share a link to a case study and tag the customer in the post. The trick here is to post your case studies in a way that attracts the right people to click through, rather than just a generic message like, “New Case Study ->> LINK." Make sure your status communicates clearly the challenge that was overcome or the goal that was achieved. It's also wise to include the main stats associated with the case study; for example, "2x lead flow," "125% increase in X," and so on.
- Update your cover image on Twitter/Facebook showing a happy customer. Our social media cover photo templates should help you with this!
- Add your case study to your list of publications on LinkedIn.
- Share your case studies in relevant LinkedIn Groups.
- Target your new case studies to relevant people on Facebook using dark posts. ( Learn about dark posts here. )
Get Inspired: MaRS Discovery District posts case studies on Twitter to push people towards a desired action.

9. Use case studies in your email marketing.
Case studies are particularly suited to email marketing when you have an industry-segmentable list. For example, if you have a case study from a client in the insurance industry, emailing your case study to your base of insurance-related contacts can be a really relevant addition to a lead nurturing campaign.
Case studies can also be very effective when used in product-specific lead nurture workflows in reactivating opportunities that have gone cold. They can be useful for re-engaging leads that have gone quiet and who were looking at specific areas of your product that the case study relates to.
Get Inspired: It's important that your lead nurture workflow content includes the appropriate content for where prospects are in the sales cycle. If you need help on how to do this, check out our post on how to map lead nurturing content to each stage in sales cycle .
Pro tip: When sending emails, don't forget about the impact a good email signature can make. Create your own using our free Email Signature Generator .
10. Incorporate case studies into your newsletters.
This idea is as good for your client relations as it is for gaining the attention of your prospects. Customers and clients love feeling as though they're part of a community. It’s human nature. Prospects warm to companies that look after their customers; companies whose customers are happy and proud to be part of something. Also, whether we are willing to admit it or not, people love to show off!
Get Inspired: Newsletters become stale over time. Give your newsletters a new lease of life with our guide on how to create newsletters that don't suck .
11. Equip your sales team with case studies.
Tailored content has become increasingly important to sales reps as they look to provide value on the sales call. It's estimated that consumers go through 70-90% of the buyer's journey before contacting a vendor. This means that the consumer is more knowledgeable than ever before. Sales reps no longer need to spend an entire call talking about the features and benefits. Sales has become more complex, and reps now need to be armed with content that addresses each stage of the buyer’s process. Case studies can be really useful when it comes to showing prospects how successful other people within a similar industry has benefited from your product or service.
Get Inspired: Case studies are just one type of content that helps your sales team sell. They don't always work by themselves, though. Check out our list of content types that help sales close more deals .
12. Sneak a case study into your email signature.
Include a link to a recent case study in your email signature. This is particularly useful for salespeople. Here's what my email signature looks like:

Get Inspired: Did you know that there are lots more ways you can use your email signature to support your marketing? Here are 10 clever suggestions for how you can do this.
13. Use case studies in training.
Having customer case studies is an invaluable asset to have when onboarding new employees. It aids developing their buy-in, belief in, and understanding of your offering.
Get Inspired: Have you completed our Inbound Certification course yet? During our classes, we use case studies to show how inbound marketing is applied in real life.
In Lead-Gen Content
14. include case studies in your lead gen efforts..
There are a number of offers you can create based off of your case studies, in the form of ebooks, templates, and more. For example you could put together an ebook titled “A step-by-step guide to reaching 10,000 blog subscribers in 3 months…just like XX did.” You could create a more in-depth version of the case study with access to detailed statistics as an offer. (And don’t forget, you can also u se quotes and statistics from case studies on the landing page promoting the ebook, which adds credibility and could increase your conversion rates.) Or, you could create a template based on your customer's approach to success.
Get Inspired: If you think you need to be an awesome designer put together beautiful ebooks, think again. Create ebooks easily using these customisable ebook templates .
You can also use case studies to frame webinars that document how to be successful with X. Using case studies in webinars is great middle-of-the-funnel content and can really help move your leads further down the funnel towards becoming sales qualified leads.
Get Inspired: Webinars are really effective as part of a lead nurturing workflow. Make sure your next webinar is spot on by following these simple webinar tips.
15. Create a bank of evergreen presentations.
It’s important to build up a bank of evergreen content that employees across your organisation can use during presentations or demos. Case studies are perfect for this.
Put together a few slides on the highlights of the case study to stir people’s interest, and then make them available to your sales and customer-facing teams. It's helpful if the marketer who created the presentation is the one who presents it to anyone who might use them in the future. This ensures they can explain the presentation clearly and answer any questions that might arise.
Get Inspired: What to create presentations people want to use? Here's a list of tools to make your presentations great.
16. Create SlideShares based on case studies.
Following on from a few short slides, you could also put together a more detailed presentation of the case study and upload it to SlideShare. After all, not only is SlideShare SEO-friendly (because Google indexes each presentation), but there is a huge pre-existing audience on SlideShare of over 60 million users you can tap into. SlideShare presentations are also easy to embed and share, and allow you to capture leads directly from the slides via a lead capture form.
Get Inspired: Want to generate more leads with SlideShare, but not sure how to get started? Check out this blog post .

Now that you understand the value of a marketing case study and the different ways that they can be used in your content marketing (and even sales) strategy, your next step is to think about what would convince your target audience to do business with you.
Have you recently accomplished something big for a client? Do you have a process or product with demonstrable results? What do your potential clients hope that you'll do for them?
The answers to those questions will help you craft compelling content for your case study. Then, all that's left is putting it into your audience's hands in formats they want to consume.

Editor's note: This post was originally published in January 2015 and has been updated for comprehensiveness.
Don't forget to share this post!
Related articles.

How to Write a Case Study: Bookmarkable Guide & Template

How to Market an Ebook: 21 Ways to Promote Your Content Offers
![7 Pieces of Content Your Audience Really Wants to See [New Data]](https://blog.hubspot.com/hubfs/most%20popular%20types%20of%20content.jpg "how to show case study")
7 Pieces of Content Your Audience Really Wants to See [New Data]
![How to Write a Listicle [+ Examples and Ideas]](https://blog.hubspot.com/hubfs/listicle-1.jpg "how to show case study")
How to Write a Listicle [+ Examples and Ideas]

28 Case Study Examples Every Marketer Should See
![What Is a White Paper? [FAQs]](https://blog.hubspot.com/hubfs/business%20whitepaper.jpg "how to show case study")
What Is a White Paper? [FAQs]

What is an Advertorial? 8 Examples to Help You Write One

How to Create Marketing Offers That Don't Fall Flat

20 Creative Ways To Repurpose Content

11 Ways to Make Your Blog Post Interactive
Showcase your company's success using these free case study templates.
Marketing software that helps you drive revenue, save time and resources, and measure and optimize your investments — all on one easy-to-use platform
Machine Learning and image analysis towards improved energy management in Industry 4.0: a practical case study on quality control
- Original Article
- Open access
- Published: 13 May 2024
- Volume 17 , article number 48 , ( 2024 )
Cite this article
You have full access to this open access article

- Mattia Casini 1 ,
- Paolo De Angelis 1 ,
- Marco Porrati 2 ,
- Paolo Vigo 1 ,
- Matteo Fasano 1 ,
- Eliodoro Chiavazzo 1 &
- Luca Bergamasco ORCID: orcid.org/0000-0001-6130-9544 1
155 Accesses
1 Altmetric
Explore all metrics
With the advent of Industry 4.0, Artificial Intelligence (AI) has created a favorable environment for the digitalization of manufacturing and processing, helping industries to automate and optimize operations. In this work, we focus on a practical case study of a brake caliper quality control operation, which is usually accomplished by human inspection and requires a dedicated handling system, with a slow production rate and thus inefficient energy usage. We report on a developed Machine Learning (ML) methodology, based on Deep Convolutional Neural Networks (D-CNNs), to automatically extract information from images, to automate the process. A complete workflow has been developed on the target industrial test case. In order to find the best compromise between accuracy and computational demand of the model, several D-CNNs architectures have been tested. The results show that, a judicious choice of the ML model with a proper training, allows a fast and accurate quality control; thus, the proposed workflow could be implemented for an ML-powered version of the considered problem. This would eventually enable a better management of the available resources, in terms of time consumption and energy usage.
Similar content being viewed by others

Towards Operation Excellence in Automobile Assembly Analysis Using Hybrid Image Processing

Deep Learning Based Algorithms for Welding Edge Points Detection

Artificial Intelligence: Prospect in Mechanical Engineering Field—A Review
Avoid common mistakes on your manuscript.
Introduction
An efficient use of energy resources in industry is key for a sustainable future (Bilgen, 2014 ; Ocampo-Martinez et al., 2019 ). The advent of Industry 4.0, and of Artificial Intelligence, have created a favorable context for the digitalisation of manufacturing processes. In this view, Machine Learning (ML) techniques have the potential for assisting industries in a better and smart usage of the available data, helping to automate and improve operations (Narciso & Martins, 2020 ; Mazzei & Ramjattan, 2022 ). For example, ML tools can be used to analyze sensor data from industrial equipment for predictive maintenance (Carvalho et al., 2019 ; Dalzochio et al., 2020 ), which allows identification of potential failures in advance, and thus to a better planning of maintenance operations with reduced downtime. Similarly, energy consumption optimization (Shen et al., 2020 ; Qin et al., 2020 ) can be achieved via ML-enabled analysis of available consumption data, with consequent adjustments of the operating parameters, schedules, or configurations to minimize energy consumption while maintaining an optimal production efficiency. Energy consumption forecast (Liu et al., 2019 ; Zhang et al., 2018 ) can also be improved, especially in industrial plants relying on renewable energy sources (Bologna et al., 2020 ; Ismail et al., 2021 ), by analysis of historical data on weather patterns and forecast, to optimize the usage of energy resources, avoid energy peaks, and leverage alternative energy sources or storage systems (Li & Zheng, 2016 ; Ribezzo et al., 2022 ; Fasano et al., 2019 ; Trezza et al., 2022 ; Mishra et al., 2023 ). Finally, ML tools can also serve for fault or anomaly detection (Angelopoulos et al., 2019 ; Md et al., 2022 ), which allows prompt corrective actions to optimize energy usage and prevent energy inefficiencies. Within this context, ML techniques for image analysis (Casini et al., 2024 ) are also gaining increasing interest (Chen et al., 2023 ), for their application to e.g. materials design and optimization (Choudhury, 2021 ), quality control (Badmos et al., 2020 ), process monitoring (Ho et al., 2021 ), or detection of machine failures by converting time series data from sensors to 2D images (Wen et al., 2017 ).
Incorporating digitalisation and ML techniques into Industry 4.0 has led to significant energy savings (Maggiore et al., 2021 ; Nota et al., 2020 ). Projects adopting these technologies can achieve an average of 15% to 25% improvement in energy efficiency in the processes where they were implemented (Arana-Landín et al., 2023 ). For instance, in predictive maintenance, ML can reduce energy consumption by optimizing the operation of machinery (Agrawal et al., 2023 ; Pan et al., 2024 ). In process optimization, ML algorithms can improve energy efficiency by 10-20% by analyzing and adjusting machine operations for optimal performance, thereby reducing unnecessary energy usage (Leong et al., 2020 ). Furthermore, the implementation of ML algorithms for optimal control can lead to energy savings of 30%, because these systems can make real-time adjustments to production lines, ensuring that machines operate at peak energy efficiency (Rahul & Chiddarwar, 2023 ).
In automotive manufacturing, ML-driven quality control can lead to energy savings by reducing the need for redoing parts or running inefficient production cycles (Vater et al., 2019 ). In high-volume production environments such as consumer electronics, novel computer-based vision models for automated detection and classification of damaged packages from intact packages can speed up operations and reduce waste (Shahin et al., 2023 ). In heavy industries like steel or chemical manufacturing, ML can optimize the energy consumption of large machinery. By predicting the optimal operating conditions and maintenance schedules, these systems can save energy costs (Mypati et al., 2023 ). Compressed air is one of the most energy-intensive processes in manufacturing. ML can optimize the performance of these systems, potentially leading to energy savings by continuously monitoring and adjusting the air compressors for peak efficiency, avoiding energy losses due to leaks or inefficient operation (Benedetti et al., 2019 ). ML can also contribute to reducing energy consumption and minimizing incorrectly produced parts in polymer processing enterprises (Willenbacher et al., 2021 ).
Here we focus on a practical industrial case study of brake caliper processing. In detail, we focus on the quality control operation, which is typically accomplished by human visual inspection and requires a dedicated handling system. This eventually implies a slower production rate, and inefficient energy usage. We thus propose the integration of an ML-based system to automatically perform the quality control operation, without the need for a dedicated handling system and thus reduced operation time. To this, we rely on ML tools able to analyze and extract information from images, that is, deep convolutional neural networks, D-CNNs (Alzubaidi et al., 2021 ; Chai et al., 2021 ).

Sample 3D model (GrabCAD ) of the considered brake caliper: (a) part without defects, and (b) part with three sample defects, namely a scratch, a partially missing letter in the logo, and a circular painting defect (shown by the yellow squares, from left to right respectively)
A complete workflow for the purpose has been developed and tested on a real industrial test case. This includes: a dedicated pre-processing of the brake caliper images, their labelling and analysis using two dedicated D-CNN architectures (one for background removal, and one for defect identification), post-processing and analysis of the neural network output. Several different D-CNN architectures have been tested, in order to find the best model in terms of accuracy and computational demand. The results show that, a judicious choice of the ML model with a proper training, allows to obtain fast and accurate recognition of possible defects. The best-performing models, indeed, reach over 98% accuracy on the target criteria for quality control, and take only few seconds to analyze each image. These results make the proposed workflow compliant with the typical industrial expectations; therefore, in perspective, it could be implemented for an ML-powered version of the considered industrial problem. This would eventually allow to achieve better performance of the manufacturing process and, ultimately, a better management of the available resources in terms of time consumption and energy expense.

Different neural network architectures: convolutional encoder (a) and encoder-decoder (b)
The industrial quality control process that we target is the visual inspection of manufactured components, to verify the absence of possible defects. Due to industrial confidentiality reasons, a representative open-source 3D geometry (GrabCAD ) of the considered parts, similar to the original one, is shown in Fig. 1 . For illustrative purposes, the clean geometry without defects (Fig. 1 (a)) is compared to the geometry with three possible sample defects, namely: a scratch on the surface of the brake caliper, a partially missing letter in the logo, and a circular painting defect (highlighted by the yellow squares, from left to right respectively, in Fig. 1 (b)). Note that, one or multiple defects may be present on the geometry, and that other types of defects may also be considered.
Within the industrial production line, this quality control is typically time consuming, and requires a dedicated handling system with the associated slow production rate and energy inefficiencies. Thus, we developed a methodology to achieve an ML-powered version of the control process. The method relies on data analysis and, in particular, on information extraction from images of the brake calipers via Deep Convolutional Neural Networks, D-CNNs (Alzubaidi et al., 2021 ). The designed workflow for defect recognition is implemented in the following two steps: 1) removal of the background from the image of the caliper, in order to reduce noise and irrelevant features in the image, ultimately rendering the algorithms more flexible with respect to the background environment; 2) analysis of the geometry of the caliper to identify the different possible defects. These two serial steps are accomplished via two different and dedicated neural networks, whose architecture is discussed in the next section.
Convolutional Neural Networks (CNNs) pertain to a particular class of deep neural networks for information extraction from images. The feature extraction is accomplished via convolution operations; thus, the algorithms receive an image as an input, analyze it across several (deep) neural layers to identify target features, and provide the obtained information as an output (Casini et al., 2024 ). Regarding this latter output, different formats can be retrieved based on the considered architecture of the neural network. For a numerical data output, such as that required to obtain a classification of the content of an image (Bhatt et al., 2021 ), e.g. correct or defective caliper in our case, a typical layout of the network involving a convolutional backbone, and a fully-connected network can be adopted (see Fig. 2 (a)). On the other hand, if the required output is still an image, a more complex architecture with a convolutional backbone (encoder) and a deconvolutional head (decoder) can be used (see Fig. 2 (b)).
As previously introduced, our workflow targets the analysis of the brake calipers in a two-step procedure: first, the removal of the background from the input image (e.g. Fig. 1 ); second, the geometry of the caliper is analyzed and the part is classified as acceptable or not depending on the absence or presence of any defect, respectively. Thus, in the first step of the procedure, a dedicated encoder-decoder network (Minaee et al., 2021 ) is adopted to classify the pixels in the input image as brake or background. The output of this model will then be a new version of the input image, where the background pixels are blacked. This helps the algorithms in the subsequent analysis to achieve a better performance, and to avoid bias due to possible different environments in the input image. In the second step of the workflow, a dedicated encoder architecture is adopted. Here, the previous background-filtered image is fed to the convolutional network, and the geometry of the caliper is analyzed to spot possible defects and thus classify the part as acceptable or not. In this work, both deep learning models are supervised , that is, the algorithms are trained with the help of human-labeled data (LeCun et al., 2015 ). Particularly, the first algorithm for background removal is fed with the original image as well as with a ground truth (i.e. a binary image, also called mask , consisting of black and white pixels) which instructs the algorithm to learn which pixels pertain to the brake and which to the background. This latter task is usually called semantic segmentation in Machine Learning and Deep Learning (Géron, 2022 ). Analogously, the second algorithm is fed with the original image (without the background) along with an associated mask, which serves the neural networks with proper instructions to identify possible defects on the target geometry. The required pre-processing of the input images, as well as their use for training and validation of the developed algorithms, are explained in the next sections.
Image pre-processing
Machine Learning approaches rely on data analysis; thus, the quality of the final results is well known to depend strongly on the amount and quality of the available data for training of the algorithms (Banko & Brill, 2001 ; Chen et al., 2021 ). In our case, the input images should be well-representative for the target analysis and include adequate variability of the possible features to allow the neural networks to produce the correct output. In this view, the original images should include, e.g., different possible backgrounds, a different viewing angle of the considered geometry and a different light exposure (as local light reflections may affect the color of the geometry and thus the analysis). The creation of such a proper dataset for specific cases is not always straightforward; in our case, for example, it would imply a systematic acquisition of a large set of images in many different conditions. This would require, in turn, disposing of all the possible target defects on the real parts, and of an automatic acquisition system, e.g., a robotic arm with an integrated camera. Given that, in our case, the initial dataset could not be generated on real parts, we have chosen to generate a well-balanced dataset of images in silico , that is, based on image renderings of the real geometry. The key idea was that, if the rendered geometry is sufficiently close to a real photograph, the algorithms may be instructed on artificially-generated images and then tested on a few real ones. This approach, if properly automatized, clearly allows to easily produce a large amount of images in all the different conditions required for the analysis.
In a first step, starting from the CAD file of the brake calipers, we worked manually using the open-source software Blender (Blender ), to modify the material properties and achieve a realistic rendering. After that, defects were generated by means of Boolean (subtraction) operations between the geometry of the brake caliper and ad-hoc geometries for each defect. Fine tuning on the generated defects has allowed for a realistic representation of the different defects. Once the results were satisfactory, we developed an automated Python code for the procedures, to generate the renderings in different conditions. The Python code allows to: load a given CAD geometry, change the material properties, set different viewing angles for the geometry, add different types of defects (with given size, rotation and location on the geometry of the brake caliper), add a custom background, change the lighting conditions, render the scene and save it as an image.
In order to make the dataset as varied as possible, we introduced three light sources into the rendering environment: a diffuse natural lighting to simulate daylight conditions, and two additional artificial lights. The intensity of each light source and the viewing angle were then made vary randomly, to mimic different daylight conditions and illuminations of the object. This procedure was designed to provide different situations akin to real use, and to make the model invariant to lighting conditions and camera position. Moreover, to provide additional flexibility to the model, the training dataset of images was virtually expanded using data augmentation (Mumuni & Mumuni, 2022 ), where saturation, brightness and contrast were made randomly vary during training operations. This procedure has allowed to consistently increase the number and variety of the images in the training dataset.
The developed automated pre-processing steps easily allows for batch generation of thousands of different images to be used for training of the neural networks. This possibility is key for proper training of the neural networks, as the variability of the input images allows the models to learn all the possible features and details that may change during real operating conditions.

Examples of the ground truth for the two target tasks: background removal (a) and defects recognition (b)
The first tests using such virtual database have shown that, although the generated images were very similar to real photographs, the models were not able to properly recognize the target features in the real images. Thus, in a tentative to get closer to a proper set of real images, we decided to adopt a hybrid dataset, where the virtually generated images were mixed with the available few real ones. However, given that some possible defects were missing in the real images, we also decided to manipulate the images to introduce virtual defects on real images. The obtained dataset finally included more than 4,000 images, where 90% was rendered, and 10% was obtained from real images. To avoid possible bias in the training dataset, defects were present in 50% of the cases in both the rendered and real image sets. Thus, in the overall dataset, the real original images with no defects were 5% of the total.
Along with the code for the rendering and manipulation of the images, dedicated Python routines were developed to generate the corresponding data labelling for the supervised training of the networks, namely the image masks. Particularly, two masks were generated for each input image: one for the background removal operation, and one for the defect identification. In both cases, the masks consist of a binary (i.e. black and white) image where all the pixels of a target feature (i.e. the geometry or defect) are assigned unitary values (white); whereas, all the remaining pixels are blacked (zero values). An example of these masks in relation to the geometry in Fig. 1 is shown in Fig. 3 .
All the generated images were then down-sampled, that is, their resolution was reduced to avoid unnecessary large computational times and (RAM) memory usage while maintaining the required level of detail for training of the neural networks. Finally, the input images and the related masks were split into a mosaic of smaller tiles, to achieve a suitable size for feeding the images to the neural networks with even more reduced requirements on the RAM memory. All the tiles were processed, and the whole image reconstructed at the end of the process to visualize the overall final results.

Confusion matrix for accuracy assessment of the neural networks models
Choice of the model
Within the scope of the present application, a wide range of possibly suitable models is available (Chen et al., 2021 ). In general, the choice of the best model for a given problem should be made on a case-by-case basis, considering an acceptable compromise between the achievable accuracy and computational complexity/cost. Too simple models can indeed be very fast in the response yet have a reduced accuracy. On the other hand, more complex models can generally provide more accurate results, although typically requiring larger amounts of data for training, and thus longer computational times and energy expense. Hence, testing has the crucial role to allow identification of the best trade-off between these two extreme cases. A benchmark for model accuracy can generally be defined in terms of a confusion matrix, where the model response is summarized into the following possibilities: True Positives (TP), True Negatives (TN), False Positives (FP) and False Negatives (FN). This concept can be summarized as shown in Fig. 4 . For the background removal, Positive (P) stands for pixels belonging to the brake caliper, while Negative (N) for background pixels. For the defect identification model, Positive (P) stands for non-defective geometry, whereas Negative (N) stands for defective geometries. With respect to these two cases, the True/False statements stand for correct or incorrect identification, respectively. The model accuracy can be therefore assessed as Géron ( 2022 )
Based on this metrics, the accuracy for different models can then be evaluated on a given dataset, where typically 80% of the data is used for training and the remaining 20% for validation. For the defect recognition stage, the following models were tested: VGG-16 (Simonyan & Zisserman, 2014 ), ResNet50, ResNet101, ResNet152 (He et al., 2016 ), Inception V1 (Szegedy et al., 2015 ), Inception V4 and InceptionResNet V2 (Szegedy et al., 2017 ). Details on the assessment procedure for the different models are provided in the Supplementary Information file. For the background removal stage, the DeepLabV3 \(+\) (Chen et al., 2018 ) model was chosen as the first option, and no additional models were tested as it directly provided satisfactory results in terms of accuracy and processing time. This gives preliminary indication that, from the point of view of the task complexity of the problem, the defect identification stage can be more demanding with respect to the background removal operation for the case study at hand. Besides the assessment of the accuracy according to, e.g., the metrics discussed above, additional information can be generally collected, such as too low accuracy (indicating insufficient amount of training data), possible bias of the models on the data (indicating a non-well balanced training dataset), or other specific issues related to missing representative data in the training dataset (Géron, 2022 ). This information helps both to correctly shape the training dataset, and to gather useful indications for the fine tuning of the model after its choice has been made.
Background removal
An initial bias of the model for background removal arose on the color of the original target geometry (red color). The model was indeed identifying possible red spots on the background as part of the target geometry as an unwanted output. To improve the model flexibility, and thus its accuracy on the identification of the background, the training dataset was expanded using data augmentation (Géron, 2022 ). This technique allows to artificially increase the size of the training dataset by applying various transformations to the available images, with the goal to improve the performance and generalization ability of the models. This approach typically involves applying geometric and/or color transformations to the original images; in our case, to account for different viewing angles of the geometry, different light exposures, and different color reflections and shadowing effects. These improvements of the training dataset proved to be effective on the performance for the background removal operation, with a validation accuracy finally ranging above 99% and model response time around 1-2 seconds. An example of the output of this operation for the geometry in Fig. 1 is shown in Fig. 5 .
While the results obtained were satisfactory for the original (red) color of the calipers, we decided to test the model ability to be applied on brake calipers of other colors as well. To this, the model was trained and tested on a grayscale version of the images of the calipers, which allows to completely remove any possible bias of the model on a specific color. In this case, the validation accuracy of the model was still obtained to range above 99%; thus, this approach was found to be particularly interesting to make the model suitable for background removal operation even on images including calipers of different colors.

Target geometry after background removal
Defect recognition
An overview of the performance of the tested models for the defect recognition operation on the original geometry of the caliper is reported in Table 1 (see also the Supplementary Information file for more details on the assessment of different models). The results report on the achieved validation accuracy ( \(A_v\) ) and on the number of parameters ( \(N_p\) ), with this latter being the total number of parameters that can be trained for each model (Géron, 2022 ) to determine the output. Here, this quantity is adopted as an indicator of the complexity of each model.

Accuracy (a) and loss function (b) curves for the Resnet101 model during training
As the results in Table 1 show, the VGG-16 model was quite unprecise for our dataset, eventually showing underfitting (Géron, 2022 ). Thus, we decided to opt for the Resnet and Inception families of models. Both these families of models have demonstrated to be suitable for handling our dataset, with slightly less accurate results being provided by the Resnet50 and InceptionV1. The best results were obtained using Resnet101 and InceptionV4, with very high final accuracy and fast processing time (in the order \(\sim \) 1 second). Finally, Resnet152 and InceptionResnetV2 models proved to be slightly too complex or slower for our case; they indeed provided excellent results but taking longer response times (in the order of \(\sim \) 3-5 seconds). The response time is indeed affected by the complexity ( \(N_p\) ) of the model itself, and by the hardware used. In our work, GPUs were used for training and testing all the models, and the hardware conditions were kept the same for all models.
Based on the results obtained, ResNet101 model was chosen as the best solution for our application, in terms of accuracy and reduced complexity. After fine-tuning operations, the accuracy that we obtained with this model reached nearly 99%, both in the validation and test datasets. This latter includes target real images, that the models have never seen before; thus, it can be used for testing of the ability of the models to generalize the information learnt during the training/validation phase.
The trend in the accuracy increase and loss function decrease during training of the Resnet101 model on the original geometry are shown in Fig. 6 (a) and (b), respectively. Particularly, the loss function quantifies the error between the predicted output during training of the model and the actual target values in the dataset. In our case, the loss function is computed using the cross-entropy function and the Adam optimiser (Géron, 2022 ). The error is expected to reduce during the training, which eventually leads to more accurate predictions of the model on previously-unseen data. The combination of accuracy and loss function trends, along with other control parameters, is typically used and monitored to evaluate the training process, and avoid e.g. under- or over-fitting problems (Géron, 2022 ). As Fig. 6 (a) shows, the accuracy experiences a sudden step increase during the very first training phase (epochs, that is, the number of times the complete database is repeatedly scrutinized by the model during its training (Géron, 2022 )). The accuracy then increases in a smooth fashion with the epochs, until an asymptotic value is reached both for training and validation accuracy. These trends in the two accuracy curves can generally be associated with a proper training; indeed, being the two curves close to each other may be interpreted as an absence of under-fitting problems. On the other hand, Fig. 6 (b) shows that the loss function curves are close to each other, with a monotonically-decreasing trend. This can be interpreted as an absence of over-fitting problems, and thus of proper training of the model.

Final results of the analysis on the defect identification: (a) considered input geometry, (b), (c) and (d) identification of a scratch on the surface, partially missing logo, and painting defect respectively (highlighted in the red frames)
Finally, an example output of the overall analysis is shown in Fig. 7 , where the considered input geometry is shown (a), along with the identification of the defects (b), (c) and (d) obtained from the developed protocol. Note that, here the different defects have been separated in several figures for illustrative purposes; however, the analysis yields the identification of defects on one single image. In this work, a binary classification was performed on the considered brake calipers, where the output of the models allows to discriminate between defective or non-defective components based on the presence or absence of any of the considered defects. Note that, fine tuning of this discrimination is ultimately with the user’s requirements. Indeed, the model output yields as the probability (from 0 to 100%) of the possible presence of defects; thus, the discrimination between a defective or non-defective part is ultimately with the user’s choice of the acceptance threshold for the considered part (50% in our case). Therefore, stricter or looser criteria can be readily adopted. Eventually, for particularly complex cases, multiple models may also be used concurrently for the same task, and the final output defined based on a cross-comparison of the results from different models. As a last remark on the proposed procedure, note that here we adopted a binary classification based on the presence or absence of any defect; however, further classification of the different defects could also be implemented, to distinguish among different types of defects (multi-class classification) on the brake calipers.
Energy saving
Illustrative scenarios.
Given that the proposed tools have not yet been implemented and tested within a real industrial production line, we analyze here three perspective scenarios to provide a practical example of the potential for energy savings in an industrial context. To this, we consider three scenarios, which compare traditional human-based control operations and a quality control system enhanced by the proposed Machine Learning (ML) tools. Specifically, here we analyze a generic brake caliper assembly line formed by 14 stations, as outlined in Table 1 in the work by Burduk and Górnicka ( 2017 ). This assembly line features a critical inspection station dedicated to defect detection, around which we construct three distinct scenarios to evaluate the efficacy of traditional human-based control operations versus a quality control system augmented by the proposed ML-based tools, namely:
First Scenario (S1): Human-Based Inspection. The traditional approach involves a human operator responsible for the inspection tasks.
Second Scenario (S2): Hybrid Inspection. This scenario introduces a hybrid inspection system where our proposed ML-based automatic detection tool assists the human inspector. The ML tool analyzes the brake calipers and alerts the human inspector only when it encounters difficulties in identifying defects, specifically when the probability of a defect being present or absent falls below a certain threshold. This collaborative approach aims to combine the precision of ML algorithms with the experience of human inspectors, and can be seen as a possible transition scenario between the human-based and a fully-automated quality control operation.
Third Scenario (S3): Fully Automated Inspection. In the final scenario, we conceive a completely automated defect inspection station powered exclusively by our ML-based detection system. This setup eliminates the need for human intervention, relying entirely on the capabilities of the ML tools to identify defects.
For simplicity, we assume that all the stations are aligned in series without buffers, minimizing unnecessary complications in our estimations. To quantify the beneficial effects of implementing ML-based quality control, we adopt the Overall Equipment Effectiveness (OEE) as the primary metric for the analysis. OEE is a comprehensive measure derived from the product of three critical factors, as outlined by Nota et al. ( 2020 ): Availability (the ratio of operating time with respect to planned production time); Performance (the ratio of actual output with respect to the theoretical maximum output); and Quality (the ratio of the good units with respect to the total units produced). In this section, we will discuss the details of how we calculate each of these factors for the various scenarios.
To calculate Availability ( A ), we consider an 8-hour work shift ( \(t_{shift}\) ) with 30 minutes of breaks ( \(t_{break}\) ) during which we assume production stop (except for the fully automated scenario), and 30 minutes of scheduled downtime ( \(t_{sched}\) ) required for machine cleaning and startup procedures. For unscheduled downtime ( \(t_{unsched}\) ), primarily due to machine breakdowns, we assume an average breakdown probability ( \(\rho _{down}\) ) of 5% for each machine, with an average repair time of one hour per incident ( \(t_{down}\) ). Based on these assumptions, since the Availability represents the ratio of run time ( \(t_{run}\) ) to production time ( \(t_{pt}\) ), it can be calculated using the following formula:
with the unscheduled downtime being computed as follows:
where N is the number of machines in the production line and \(1-\left( 1-\rho _{down}\right) ^{N}\) represents the probability that at least one machine breaks during the work shift. For the sake of simplicity, the \(t_{down}\) is assumed constant regardless of the number of failures.
Table 2 presents the numerical values used to calculate Availability in the three scenarios. In the second scenario, we can observe that integrating the automated station leads to a decrease in the first factor of the OEE analysis, which can be attributed to the additional station for automated quality-control (and the related potential failure). This ultimately increases the estimation of the unscheduled downtime. In the third scenario, the detrimental effect of the additional station compensates the beneficial effect of the automated quality control on reducing the need for pauses during operator breaks; thus, the Availability for the third scenario yields as substantially equivalent to the first one (baseline).
The second factor of OEE, Performance ( P ), assesses the operational efficiency of production equipment relative to its maximum designed speed ( \(t_{line}\) ). This evaluation includes accounting for reductions in cycle speed and minor stoppages, collectively termed as speed losses . These losses are challenging to measure in advance, as performance is typically measured using historical data from the production line. For this analysis, we are constrained to hypothesize a reasonable estimate of 60 seconds of time lost to speed losses ( \(t_{losses}\) ) for each work cycle. Although this assumption may appear strong, it will become evident later that, within the context of this analysis – particularly regarding the impact of automated inspection on energy savings – the Performance (like the Availability) is only marginally influenced by introducing an automated inspection station. To account for the effect of automated inspection on the assembly line speed, we keep the time required by the other 13 stations ( \(t^*_{line}\) ) constant while varying the time allocated for visual inspection ( \(t_{inspect}\) ). According to Burduk and Górnicka ( 2017 ), the total operation time of the production line, excluding inspection, is 1263 seconds, with manual visual inspection taking 38 seconds. For the fully automated third scenario, we assume an inspection time of 5 seconds, which encloses the photo collection, pre-processing, ML-analysis, and post-processing steps. In the second scenario, instead, we add an additional time to the pure automatic case to consider the cases when the confidence of the ML model falls below 90%. We assume this happens once in every 10 inspections, which is a conservative estimate, higher than that we observed during model testing. This results in adding 10% of the human inspection time to the fully automated time. Thus, when \(t_{losses}\) are known, Performance can be expressed as follows:
The calculated values for Performance are presented in Table 3 , and we can note that the modification in inspection time has a negligible impact on this factor since it does not affect the speed loss or, at least to our knowledge, there is no clear evidence to suggest that the introduction of a new inspection station would alter these losses. Moreover, given the specific linear layout of the considered production line, the inspection time change has only a marginal effect on enhancing the production speed. However, this approach could potentially bias our scenario towards always favouring automation. To evaluate this hypothesis, a sensitivity analysis which explores scenarios where the production line operates at a faster pace will be discussed in the next subsection.
The last factor, Quality ( Q ), quantifies the ratio of compliant products out of the total products manufactured, effectively filtering out items that fail to meet the quality standards due to defects. Given the objective of our automated algorithm, we anticipate this factor of the OEE to be significantly enhanced by implementing the ML-based automated inspection station. To estimate it, we assume a constant defect probability for the production line ( \(\rho _{def}\) ) at 5%. Consequently, the number of defective products ( \(N_{def}\) ) during the work shift is calculated as \(N_{unit} \cdot \rho _{def}\) , where \(N_{unit}\) represents the average number of units (brake calipers) assembled on the production line, defined as:
To quantify defective units identified, we consider the inspection accuracy ( \(\rho _{acc}\) ), where for human visual inspection, the typical accuracy is 80% (Sundaram & Zeid, 2023 ), and for the ML-based station, we use the accuracy of our best model, i.e., 99%. Additionally, we account for the probability of the station mistakenly identifying a caliper as with a defect even if it is defect-free, i.e., the false negative rate ( \(\rho _{FN}\) ), defined as
In the absence of any reasonable evidence to justify a bias on one mistake over others, we assume a uniform distribution for both human and automated inspections regarding error preference, i.e. we set \(\rho ^{H}_{FN} = \rho ^{ML}_{FN} = \rho _{FN} = 50\%\) . Thus, the number of final compliant goods ( \(N_{goods}\) ), i.e., the calipers that are identified as quality-compliant, can be calculated as:
where \(N_{detect}\) is the total number of detected defective units, comprising TN (true negatives, i.e. correctly identified defective calipers) and FN (false negatives, i.e. calipers mistakenly identified as defect-free). The Quality factor can then be computed as:
Table 4 summarizes the Quality factor calculation, showcasing the substantial improvement brought by the ML-based inspection station due to its higher accuracy compared to human operators.

Overall Equipment Effectiveness (OEE) analysis for three scenarios (S1: Human-Based Inspection, S2: Hybrid Inspection, S3: Fully Automated Inspection). The height of the bars represents the percentage of the three factors A : Availability, P : Performance, and Q : Quality, which can be interpreted from the left axis. The green bars indicate the OEE value, derived from the product of these three factors. The red line shows the recall rate, i.e. the probability that a defective product is rejected by the client, with values displayed on the right red axis
Finally, we can determine the Overall Equipment Effectiveness by multiplying the three factors previously computed. Additionally, we can estimate the recall rate ( \(\rho _{R}\) ), which reflects the rate at which a customer might reject products. This is derived from the difference between the total number of defective units, \(N_{def}\) , and the number of units correctly identified as defective, TN , indicating the potential for defective brake calipers that may bypass the inspection process. In Fig. 8 we summarize the outcomes of the three scenarios. It is crucial to note that the scenarios incorporating the automated defect detector, S2 and S3, significantly enhance the Overall Equipment Effectiveness, primarily through substantial improvements in the Quality factor. Among these, the fully automated inspection scenario, S3, emerges as a slightly superior option, thanks to its additional benefit in removing the breaks and increasing the speed of the line. However, given the different assumptions required for this OEE study, we shall interpret these results as illustrative, and considering them primarily as comparative with the baseline scenario only. To analyze the sensitivity of the outlined scenarios on the adopted assumptions, we investigate the influence of the line speed and human accuracy on the results in the next subsection.
Sensitivity analysis
The scenarios described previously are illustrative and based on several simplifying hypotheses. One of such hypotheses is that the production chain layout operates entirely in series, with each station awaiting the arrival of the workpiece from the preceding station, resulting in a relatively slow production rate (1263 seconds). This setup can be quite different from reality, where slower operations can be accelerated by installing additional machines in parallel to balance the workload and enhance productivity. Moreover, we utilized a literature value of 80% for the accuracy of the human visual inspector operator, as reported by Sundaram and Zeid ( 2023 ). However, this accuracy can vary significantly due to factors such as the experience of the inspector and the defect type.

Effect of assembly time for stations (excluding visual inspection), \(t^*_{line}\) , and human inspection accuracy, \(\rho _{acc}\) , on the OEE analysis. (a) The subplot shows the difference between the scenario S2 (Hybrid Inspection) and the baseline scenario S1 (Human Inspection), while subplot (b) displays the difference between scenario S3 (Fully Automated Inspection) and the baseline. The maps indicate in red the values of \(t^*_{line}\) and \(\rho _{acc}\) where the integration of automated inspection stations can significantly improve OEE, and in blue where it may lower the score. The dashed lines denote the breakeven points, and the circled points pinpoint the values of the scenarios used in the “Illustrative scenario” Subsection.
A sensitivity analysis on these two factors was conducted to address these variations. The assembly time of the stations (excluding visual inspection), \(t^*_{line}\) , was varied from 60 s to 1500 s, and the human inspection accuracy, \(\rho _{acc}\) , ranged from 50% (akin to a random guesser) to 100% (representing an ideal visual inspector); meanwhile, the other variables were kept fixed.
The comparison of the OEE enhancement for the two scenarios employing ML-based inspection against the baseline scenario is displayed in the two maps in Fig. 9 . As the figure shows, due to the high accuracy and rapid response of the proposed automated inspection station, the area representing regions where the process may benefit energy savings in the assembly lines (indicated in red shades) is significantly larger than the areas where its introduction could degrade performance (indicated in blue shades). However, it can be also observed that the automated inspection could be superfluous or even detrimental in those scenarios where human accuracy and assembly speed are very high, indicating an already highly accurate workflow. In these cases, and particularly for very fast production lines, short times for quality control can be expected to be key (beyond accuracy) for the optimization.
Finally, it is important to remark that the blue region (areas below the dashed break-even lines) might expand if the accuracy of the neural networks for defect detection is lower when implemented in an real production line. This indicates the necessity for new rounds of active learning and an augment of the ratio of real images in the database, to eventually enhance the performance of the ML model.
Conclusions
Industrial quality control processes on manufactured parts are typically achieved by human visual inspection. This usually requires a dedicated handling system, and generally results in a slower production rate, with the associated non-optimal use of the energy resources. Based on a practical test case for quality control on brake caliper manufacturing, in this work we have reported on a developed workflow for integration of Machine Learning methods to automatize the process. The proposed approach relies on image analysis via Deep Convolutional Neural Networks. These models allow to efficiently extract information from images, thus possibly representing a valuable alternative to human inspection.
The proposed workflow relies on a two-step procedure on the images of the brake calipers: first, the background is removed from the image; second, the geometry is inspected to identify possible defects. These two steps are accomplished thanks to two dedicated neural network models, an encoder-decoder and an encoder network, respectively. Training of these neural networks typically requires a large number of representative images for the problem. Given that, one such database is not always readily available, we have presented and discussed an alternative methodology for the generation of the input database using 3D renderings. While integration of the database with real photographs was required for optimal results, this approach has allowed fast and flexible generation of a large base of representative images. The pre-processing steps required for data feeding to the neural networks and their training has been also discussed.
Several models have been tested and evaluated, and the best one for the considered case identified. The obtained accuracy for defect identification reaches \(\sim \) 99% of the tested cases. Moreover, the response of the models is fast (in the order of few seconds) on each image, which makes them compliant with the most typical industrial expectations.
In order to provide a practical example of possible energy savings when implementing the proposed ML-based methodology for quality control, we have analyzed three perspective industrial scenarios: a baseline scenario, where quality control tasks are performed by a human inspector; a hybrid scenario, where the proposed ML automatic detection tool assists the human inspector; a fully-automated scenario, where we envision a completely automated defect inspection. The results show that the proposed tools may help increasing the Overall Equipment Effectiveness up to \(\sim \) 10% with respect to the considered baseline scenario. However, a sensitivity analysis on the speed of the production line and on the accuracy of the human inspector has also shown that the automated inspection could be superfluous or even detrimental in those cases where human accuracy and assembly speed are very high. In these cases, reducing the time required for quality control can be expected to be the major controlling parameter (beyond accuracy) for optimization.
Overall the results show that, with a proper tuning, these models may represent a valuable resource for integration into production lines, with positive outcomes on the overall effectiveness, and thus ultimately leading to a better use of the energy resources. To this, while the practical implementation of the proposed tools can be expected to require contained investments (e.g. a portable camera, a dedicated workstation and an operator with proper training), in field tests on a real industrial line would be required to confirm the potential of the proposed technology.
Agrawal, R., Majumdar, A., Kumar, A., & Luthra, S. (2023). Integration of artificial intelligence in sustainable manufacturing: Current status and future opportunities. Operations Management Research, 1–22.
Alzubaidi, L., Zhang, J., Humaidi, A. J., Al-Dujaili, A., Duan, Y., Al-Shamma, O., Santamaría, J., Fadhel, M. A., Al-Amidie, M., & Farhan, L. (2021). Review of deep learning: Concepts, cnn architectures, challenges, applications, future directions. Journal of big Data, 8 , 1–74.
Article Google Scholar
Angelopoulos, A., Michailidis, E. T., Nomikos, N., Trakadas, P., Hatziefremidis, A., Voliotis, S., & Zahariadis, T. (2019). Tackling faults in the industry 4.0 era-a survey of machine—learning solutions and key aspects. Sensors, 20 (1), 109.
Arana-Landín, G., Uriarte-Gallastegi, N., Landeta-Manzano, B., & Laskurain-Iturbe, I. (2023). The contribution of lean management—industry 4.0 technologies to improving energy efficiency. Energies, 16 (5), 2124.
Badmos, O., Kopp, A., Bernthaler, T., & Schneider, G. (2020). Image-based defect detection in lithium-ion battery electrode using convolutional neural networks. Journal of Intelligent Manufacturing, 31 , 885–897. https://doi.org/10.1007/s10845-019-01484-x
Banko, M., & Brill, E. (2001). Scaling to very very large corpora for natural language disambiguation. In Proceedings of the 39th annual meeting of the association for computational linguistics (pp. 26–33).
Benedetti, M., Bonfà, F., Introna, V., Santolamazza, A., & Ubertini, S. (2019). Real time energy performance control for industrial compressed air systems: Methodology and applications. Energies, 12 (20), 3935.
Bhatt, D., Patel, C., Talsania, H., Patel, J., Vaghela, R., Pandya, S., Modi, K., & Ghayvat, H. (2021). Cnn variants for computer vision: History, architecture, application, challenges and future scope. Electronics, 10 (20), 2470.
Bilgen, S. (2014). Structure and environmental impact of global energy consumption. Renewable and Sustainable Energy Reviews, 38 , 890–902.
Blender. (2023). Open-source software. https://www.blender.org/ . Accessed 18 Apr 2023.
Bologna, A., Fasano, M., Bergamasco, L., Morciano, M., Bersani, F., Asinari, P., Meucci, L., & Chiavazzo, E. (2020). Techno-economic analysis of a solar thermal plant for large-scale water pasteurization. Applied Sciences, 10 (14), 4771.
Burduk, A., & Górnicka, D. (2017). Reduction of waste through reorganization of the component shipment logistics. Research in Logistics & Production, 7 (2), 77–90. https://doi.org/10.21008/j.2083-4950.2017.7.2.2
Carvalho, T. P., Soares, F. A., Vita, R., Francisco, R., d. P., Basto, J. P., & Alcalá, S. G. (2019). A systematic literature review of machine learning methods applied to predictive maintenance. Computers & Industrial Engineering, 137 , 106024.
Casini, M., De Angelis, P., Chiavazzo, E., & Bergamasco, L. (2024). Current trends on the use of deep learning methods for image analysis in energy applications. Energy and AI, 15 , 100330. https://doi.org/10.1016/j.egyai.2023.100330
Chai, J., Zeng, H., Li, A., & Ngai, E. W. (2021). Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Machine Learning with Applications, 6 , 100134.
Chen, L. C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H. (2018). Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV) (pp. 801–818).
Chen, L., Li, S., Bai, Q., Yang, J., Jiang, S., & Miao, Y. (2021). Review of image classification algorithms based on convolutional neural networks. Remote Sensing, 13 (22), 4712.
Chen, T., Sampath, V., May, M. C., Shan, S., Jorg, O. J., Aguilar Martín, J. J., Stamer, F., Fantoni, G., Tosello, G., & Calaon, M. (2023). Machine learning in manufacturing towards industry 4.0: From ‘for now’to ‘four-know’. Applied Sciences, 13 (3), 1903. https://doi.org/10.3390/app13031903
Choudhury, A. (2021). The role of machine learning algorithms in materials science: A state of art review on industry 4.0. Archives of Computational Methods in Engineering, 28 (5), 3361–3381. https://doi.org/10.1007/s11831-020-09503-4
Dalzochio, J., Kunst, R., Pignaton, E., Binotto, A., Sanyal, S., Favilla, J., & Barbosa, J. (2020). Machine learning and reasoning for predictive maintenance in industry 4.0: Current status and challenges. Computers in Industry, 123 , 103298.
Fasano, M., Bergamasco, L., Lombardo, A., Zanini, M., Chiavazzo, E., & Asinari, P. (2019). Water/ethanol and 13x zeolite pairs for long-term thermal energy storage at ambient pressure. Frontiers in Energy Research, 7 , 148.
Géron, A. (2022). Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow . O’Reilly Media, Inc.
GrabCAD. (2023). Brake caliper 3D model by Mitulkumar Sakariya from the GrabCAD free library (non-commercial public use). https://grabcad.com/library/brake-caliper-19 . Accessed 18 Apr 2023.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778).
Ho, S., Zhang, W., Young, W., Buchholz, M., Al Jufout, S., Dajani, K., Bian, L., & Mozumdar, M. (2021). Dlam: Deep learning based real-time porosity prediction for additive manufacturing using thermal images of the melt pool. IEEE Access, 9 , 115100–115114. https://doi.org/10.1109/ACCESS.2021.3105362
Ismail, M. I., Yunus, N. A., & Hashim, H. (2021). Integration of solar heating systems for low-temperature heat demand in food processing industry-a review. Renewable and Sustainable Energy Reviews, 147 , 111192.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521 (7553), 436–444.
Leong, W. D., Teng, S. Y., How, B. S., Ngan, S. L., Abd Rahman, A., Tan, C. P., Ponnambalam, S., & Lam, H. L. (2020). Enhancing the adaptability: Lean and green strategy towards the industry revolution 4.0. Journal of cleaner production, 273 , 122870.
Liu, Z., Wang, X., Zhang, Q., & Huang, C. (2019). Empirical mode decomposition based hybrid ensemble model for electrical energy consumption forecasting of the cement grinding process. Measurement, 138 , 314–324.
Li, G., & Zheng, X. (2016). Thermal energy storage system integration forms for a sustainable future. Renewable and Sustainable Energy Reviews, 62 , 736–757.
Maggiore, S., Realini, A., Zagano, C., & Bazzocchi, F. (2021). Energy efficiency in industry 4.0: Assessing the potential of industry 4.0 to achieve 2030 decarbonisation targets. International Journal of Energy Production and Management, 6 (4), 371–381.
Mazzei, D., & Ramjattan, R. (2022). Machine learning for industry 4.0: A systematic review using deep learning-based topic modelling. Sensors, 22 (22), 8641.
Md, A. Q., Jha, K., Haneef, S., Sivaraman, A. K., & Tee, K. F. (2022). A review on data-driven quality prediction in the production process with machine learning for industry 4.0. Processes, 10 (10), 1966. https://doi.org/10.3390/pr10101966
Minaee, S., Boykov, Y., Porikli, F., Plaza, A., Kehtarnavaz, N., & Terzopoulos, D. (2021). Image segmentation using deep learning: A survey. IEEE transactions on pattern analysis and machine intelligence, 44 (7), 3523–3542.
Google Scholar
Mishra, S., Srivastava, R., Muhammad, A., Amit, A., Chiavazzo, E., Fasano, M., & Asinari, P. (2023). The impact of physicochemical features of carbon electrodes on the capacitive performance of supercapacitors: a machine learning approach. Scientific Reports, 13 (1), 6494. https://doi.org/10.1038/s41598-023-33524-1
Mumuni, A., & Mumuni, F. (2022). Data augmentation: A comprehensive survey of modern approaches. Array, 16 , 100258. https://doi.org/10.1016/j.array.2022.100258
Mypati, O., Mukherjee, A., Mishra, D., Pal, S. K., Chakrabarti, P. P., & Pal, A. (2023). A critical review on applications of artificial intelligence in manufacturing. Artificial Intelligence Review, 56 (Suppl 1), 661–768.
Narciso, D. A., & Martins, F. (2020). Application of machine learning tools for energy efficiency in industry: A review. Energy Reports, 6 , 1181–1199.
Nota, G., Nota, F. D., Peluso, D., & Toro Lazo, A. (2020). Energy efficiency in industry 4.0: The case of batch production processes. Sustainability, 12 (16), 6631. https://doi.org/10.3390/su12166631
Ocampo-Martinez, C., et al. (2019). Energy efficiency in discrete-manufacturing systems: Insights, trends, and control strategies. Journal of Manufacturing Systems, 52 , 131–145.
Pan, Y., Hao, L., He, J., Ding, K., Yu, Q., & Wang, Y. (2024). Deep convolutional neural network based on self-distillation for tool wear recognition. Engineering Applications of Artificial Intelligence, 132 , 107851.
Qin, J., Liu, Y., Grosvenor, R., Lacan, F., & Jiang, Z. (2020). Deep learning-driven particle swarm optimisation for additive manufacturing energy optimisation. Journal of Cleaner Production, 245 , 118702.
Rahul, M., & Chiddarwar, S. S. (2023). Integrating virtual twin and deep neural networks for efficient and energy-aware robotic deburring in industry 4.0. International Journal of Precision Engineering and Manufacturing, 24 (9), 1517–1534.
Ribezzo, A., Falciani, G., Bergamasco, L., Fasano, M., & Chiavazzo, E. (2022). An overview on the use of additives and preparation procedure in phase change materials for thermal energy storage with a focus on long term applications. Journal of Energy Storage, 53 , 105140.
Shahin, M., Chen, F. F., Hosseinzadeh, A., Bouzary, H., & Shahin, A. (2023). Waste reduction via image classification algorithms: Beyond the human eye with an ai-based vision. International Journal of Production Research, 1–19.
Shen, F., Zhao, L., Du, W., Zhong, W., & Qian, F. (2020). Large-scale industrial energy systems optimization under uncertainty: A data-driven robust optimization approach. Applied Energy, 259 , 114199.
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 .
Sundaram, S., & Zeid, A. (2023). Artificial Intelligence-Based Smart Quality Inspection for Manufacturing. Micromachines, 14 (3), 570. https://doi.org/10.3390/mi14030570
Szegedy, C., Ioffe, S., Vanhoucke, V., & Alemi, A. (2017). Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI conference on artificial intelligence (vol. 31).
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1–9).
Trezza, G., Bergamasco, L., Fasano, M., & Chiavazzo, E. (2022). Minimal crystallographic descriptors of sorption properties in hypothetical mofs and role in sequential learning optimization. npj Computational Materials, 8 (1), 123. https://doi.org/10.1038/s41524-022-00806-7
Vater, J., Schamberger, P., Knoll, A., & Winkle, D. (2019). Fault classification and correction based on convolutional neural networks exemplified by laser welding of hairpin windings. In 2019 9th International Electric Drives Production Conference (EDPC) (pp. 1–8). IEEE.
Wen, L., Li, X., Gao, L., & Zhang, Y. (2017). A new convolutional neural network-based data-driven fault diagnosis method. IEEE Transactions on Industrial Electronics, 65 (7), 5990–5998. https://doi.org/10.1109/TIE.2017.2774777
Willenbacher, M., Scholten, J., & Wohlgemuth, V. (2021). Machine learning for optimization of energy and plastic consumption in the production of thermoplastic parts in sme. Sustainability, 13 (12), 6800.
Zhang, X. H., Zhu, Q. X., He, Y. L., & Xu, Y. (2018). Energy modeling using an effective latent variable based functional link learning machine. Energy, 162 , 883–891.
Download references
Acknowledgements
This work has been supported by GEFIT S.p.a.
Open access funding provided by Politecnico di Torino within the CRUI-CARE Agreement.
Author information
Authors and affiliations.
Department of Energy, Politecnico di Torino, Turin, Italy
Mattia Casini, Paolo De Angelis, Paolo Vigo, Matteo Fasano, Eliodoro Chiavazzo & Luca Bergamasco
R &D Department, GEFIT S.p.a., Alessandria, Italy
Marco Porrati
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Luca Bergamasco .
Ethics declarations
Conflict of interest statement.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary file 1 (pdf 354 KB)
Rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Casini, M., De Angelis, P., Porrati, M. et al. Machine Learning and image analysis towards improved energy management in Industry 4.0: a practical case study on quality control. Energy Efficiency 17 , 48 (2024). https://doi.org/10.1007/s12053-024-10228-7
Download citation
Received : 22 July 2023
Accepted : 28 April 2024
Published : 13 May 2024
DOI : https://doi.org/10.1007/s12053-024-10228-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Industry 4.0
- Energy management
- Artificial intelligence
- Machine learning
- Deep learning
- Convolutional neural networks
- Computer vision
- Find a journal
- Publish with us
- Track your research
Miniature poodle named Sage wins Westminster Kennel Club dog show
A miniature poodle named Sage has won the top prize at the Westminster Kennel Club dog show
NEW YORK -- For a last hurrah, it was a Sage decision.
A miniature poodle named Sage won the top prize Tuesday night at the Westminster Kennel Club dog show, in what veteran handler Kaz Hosaka said would be his final time at the United States' most prestigious canine event. After 45 years of competing and two best in show dogs, he plans to retire.
Sage notched the 11th triumph for poodles of various sizes at Westminster; only wire fox terriers have won more. The last miniature poodle to take the trophy was Spice, with Hosaka, in 2002.
“No words,” he said in the ring to describe his reaction to Sage’s win before supplying a few: “So happy — exciting.”
Striding briskly and proudly around the ring, the inky-black poodle “gave a great performance for me,” Hosaka added.
Sage bested six other finalists to take best in show. Second went to Mercedes, a German shepherd whose handler, Kent Boyles, also has shepherded a best in show winner before.
Others in the final round included Comet, a shih tzu who won the big American Kennel Club National Championship last year; Monty, a giant schnauzer who arrived at Westminster as the nation’s top-ranked dog and was a Westminster finalist last year; Louis, an Afghan hound; Micah, a black cocker spaniel; and Frankie, a colored bull terrier.
While Sage was going around the ring, a protester carrying a sign urging people to “boycott breeders” tried to climb in and was quickly intercepted by security personnel. Police and the animal rights group PETA said three demonstrators were arrested. Charges have not yet been decided.
In an event where all competitors are champions in dog showing's point system, winning can depend on subtleties and a standout turn at the USTA Billie Jean King National Tennis Center, home of the U.S. Open tennis tournament.
The final lineup was “excellent, glorious,” best in show judge Rosalind Kramer said.
To Monty’s handler and co-owner, Katie Bernardin, "just to be in the ring with everyone else is an honor.”
“We all love our dogs. We’re trying our best," she said in the ring after Monty's semifinal win. “A stallion” of a dog, he's solid, powerful and “very spirited," said Bernardin of Chaplin, Connecticut.
So spirited that while Bernardin was pregnant, she did obedience and other dog sports with Monty because he needed the stimulation.
Dogs first compete against others of their breed. Then the winner of each breed goes up against others in its “group.” The seven group winners meet in the final round.
The best in show winner gets a trophy and a place in dog-world history, but no cash prize.
Besides the winners, there were other dogs that were hits with the crowd. A lagotto Romagnolo named Harry earned a chuckle from the stadium audience by sitting up and begging for a treat from his handler, and a vizsla named Fletcher charmed spectators by jumping up on its handler after finishing a spin around the ring.
There were big cheers, too, for a playful great Pyrenees called Sebastian and a Doberman pinscher named Emilio.
Other dogs that vied in vain for a spot in the finals included Stache, a Sealyham terrier. He won the National Dog Show that was televised on Thanksgiving and took top prize at a big terrier show in Pennsylvania last fall.
Stache showcases a rare breed that’s considered vulnerable to extinction even in its native Britain.
“They’re a little-known treasure,” said Stache’s co-owner, co-breeder and handler, Margery Good of Cochranville, Pennsylvania, who has bred “Sealys” for half a century. Originally developed in Wales to hunt badgers and other burrowing game, the terriers with a “fall” of hair over their eyes are courageous but comedic — Good dubs them “silly hams.”
Westminster can feel like a study in canine contrasts. Just walking around, a visitor could see a Chihuahua peering out of a carrying bag at a stocky Neapolitan mastiff, a ring full of honey-colored golden retrievers beside a lineup of stark-black giant schnauzers, and handlers with dogs far larger than themselves.
Shane Jichetti was one of them. Ralphie, the 175-pound (34-kg) great Dane she co-owns, outweighs her by a lot. It takes considerable experience to show so big an animal, but “if you have a bond with your dog, and you just go with it, it works out,” she said.
Plus Ralphie, for all his size, is “so chill,” said Jichetti. Playful at home on New York's Staten Island, he's spot-on — just like his harlequin-pattern coat — when it's time to go in the ring.
“He's just an honest dog,” Jichetti said.
The Westminster show, which dates to 1877, centers on the traditional purebred judging that leads to the best in show prize. But over the last decade, the club has added agility and obedience events open to mixed-breed dogs.
And this year, the agility competition counted its first non-purebred winner, a border collie-papillon mix named Nimble.
And Kramer, the best in show judge, made a point of thanking "every dog, whether it’s a house dog or a show dog.
“Because you make our lives whole.”
Associated Press photographer Julia Nikhinson contributed.
Trending Reader Picks

Boat seized in fatal hit-and-run: FWC
- May 15, 7:23 PM

New portrait of King Charles draws mixed reactions
- May 16, 1:44 PM

Biden asserts privilege over Hur interview audio
- May 16, 11:24 PM

'The world's fault': Zelenskyy speaks out
- May 16, 5:57 AM

Teen graduates with doctoral degree
- May 14, 12:07 PM
ABC News Live
24/7 coverage of breaking news and live events
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 14 May 2024
A burden of proof study on alcohol consumption and ischemic heart disease
- Sinclair Carr ORCID: orcid.org/0000-0003-0421-3145 1 ,
- Dana Bryazka 1 ,
- Susan A. McLaughlin 1 ,
- Peng Zheng 1 , 2 ,
- Sarasvati Bahadursingh 3 ,
- Aleksandr Y. Aravkin 1 , 2 , 4 ,
- Simon I. Hay ORCID: orcid.org/0000-0002-0611-7272 1 , 2 ,
- Hilary R. Lawlor 1 ,
- Erin C. Mullany 1 ,
- Christopher J. L. Murray ORCID: orcid.org/0000-0002-4930-9450 1 , 2 ,
- Sneha I. Nicholson 1 ,
- Jürgen Rehm 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 ,
- Gregory A. Roth 1 , 2 , 13 ,
- Reed J. D. Sorensen 1 ,
- Sarah Lewington 3 &
- Emmanuela Gakidou ORCID: orcid.org/0000-0002-8992-591X 1 , 2
Nature Communications volume 15 , Article number: 4082 ( 2024 ) Cite this article
156 Accesses
1 Altmetric
Metrics details
- Cardiovascular diseases
- Epidemiology
- Risk factors
Cohort and case-control data have suggested an association between low to moderate alcohol consumption and decreased risk of ischemic heart disease (IHD), yet results from Mendelian randomization (MR) studies designed to reduce bias have shown either no or a harmful association. Here we conducted an updated systematic review and re-evaluated existing cohort, case-control, and MR data using the burden of proof meta-analytical framework. Cohort and case-control data show low to moderate alcohol consumption is associated with decreased IHD risk – specifically, intake is inversely related to IHD and myocardial infarction morbidity in both sexes and IHD mortality in males – while pooled MR data show no association, confirming that self-reported versus genetically predicted alcohol use data yield conflicting findings about the alcohol-IHD relationship. Our results highlight the need to advance MR methodologies and emulate randomized trials using large observational databases to obtain more definitive answers to this critical public health question.
Similar content being viewed by others

Alcohol consumption and risks of more than 200 diseases in Chinese men

Alcohol intake and the risk of chronic kidney disease: results from a systematic review and dose–response meta-analysis

Association of change in alcohol consumption with cardiovascular disease and mortality among initial nondrinkers
Introduction.
It is well known that alcohol consumption increases the risk of morbidity and mortality due to many health conditions 1 , 2 , with even low levels of consumption increasing the risk for some cancers 3 , 4 . In contrast, a large body of research has suggested that low to moderate alcohol intake – compared to no consumption – is associated with a decreased risk of ischemic heart disease (IHD). This has led to substantial epidemiologic and public health interest in the alcohol-IHD relationship 5 , particularly given the high prevalence of alcohol consumption 6 and the global burden of IHD 7 .
Extensive evidence from experimental studies that vary short-term alcohol exposure suggests that average levels of alcohol intake positively affect biomarkers such as apolipoprotein A1, adiponectin, and fibrinogen levels that lower the risk of IHD 8 . In contrast, heavy episodic drinking (HED) may have an adverse effect on IHD by affecting blood lipids, promoting coagulation and thus thrombosis risk, and increasing blood pressure 9 . With effects likely to vary materially by patterns of drinking, alcohol consumption must be considered a multidimensional factor impacting IHD outcomes.
A recent meta-analysis of the alcohol-IHD relationship using individual participant data from 83 observational studies 4 found, among current drinkers, that – relative to drinking less than 50 g/week – any consumption above this level was associated with a lower risk of myocardial infarction (MI) incidence and consumption between >50 and <100 g/week was associated with lower risk of MI mortality. When evaluating other subtypes of IHD excluding MI, the researchers found that consumption between >100 and <250 g/week was associated with a decreased risk of IHD incidence, whereas consumption greater than 350 g/week was associated with an increased risk of IHD mortality. Roerecke and Rehm further observed that low to moderate drinking was not associated with reduced IHD risk when accompanied by occasional HED 10 .
The cohort studies and case-control studies (hereafter referred to as ‘conventional observational studies’) used in these meta-analyses are known to be subject to various types of bias when used to estimate causal relationships 11 . First, neglecting to separate lifetime abstainers from former drinkers, some of whom may have quit due to developing preclinical symptoms (sometimes labeled ‘sick quitters’ 12 , 13 ), and to account for drinkers who reduce their intake as a result of such symptoms may introduce reverse causation bias 13 . That is, the risk of IHD in, for example, individuals with low to moderate alcohol consumption may be lower when compared to IHD risk in sick quitters, not necessarily because intake at this level causes a reduction in risk but because sick quitters are at higher risk of IHD. Second, estimates can be biased because of measurement error in alcohol exposure resulting from inaccurate reporting, random fluctuation in consumption over time (random error), or intentional misreporting of consumption due, for example, to social desirability effects 14 (systematic error). Third, residual confounding may bias estimates if confounders of the alcohol-IHD relationship, such as diet or physical activity, have not been measured accurately (e.g., only via a self-report questionnaire) or accounted for. Fourth, because alcohol intake is a time-varying exposure, time-varying confounding affected by prior exposure must be accounted for 15 . To date, only one study that used a marginal structural model to appropriately adjust for time-varying confounding found no association between alcohol consumption and MI risk 16 . Lastly, if exposure to a risk factor, such as alcohol consumption, did not happen at random – even if all known confounders of the relationship between alcohol and IHD were perfectly measured and accounted for – the potential for unmeasured confounders persists and may bias estimates 11 .
In recent years, the analytic method of Mendelian randomization (MR) has been widely adopted to quantify the causal effects of risk factors on health outcomes 17 , 18 , 19 . MR uses single nucleotide polymorphisms (SNPs) as instrumental variables (IVs) for the exposure of interest. A valid IV should fulfill the following three assumptions: it must be associated with the risk factor (relevance assumption); there must be no common causes of the IV and the outcome (independence assumption); and the IV must affect the outcome only through the exposure (exclusion restriction or ‘no horizontal pleiotropy’ assumption) 20 , 21 . If all three assumptions are fulfilled, estimates derived from MR are presumed to represent causal effects 22 . Several MR studies have quantified the association between alcohol consumption and cardiovascular disease 23 , including IHD, using genes known to impact alcohol metabolism (e.g., ADH1B/C and ALDH2 24 ) or SNP combinations from genome-wide association studies 25 . In contrast to the inverse associations found in conventional observational studies, MR studies have found either no association or a harmful relationship between alcohol consumption and IHD 26 , 27 , 28 , 29 , 30 , 31 .
To advance the knowledge base underlying our understanding of this major health issue – critical given the worldwide ubiquity of alcohol use and of IHD – there is a need to systematically review and critically re-evaluate all available evidence on the relationship between alcohol consumption and IHD risk from both conventional observational and MR studies.
The burden of proof approach, developed by Zheng et al. 32 , is a six-step meta-analysis framework that provides conservative estimates and interpretations of risk-outcome relationships. The approach systematically tests and adjusts for common sources of bias defined according to the Grading of Recommendations Assessment, Development, and Evaluation (GRADE) criteria: representativeness of the study population, exposure assessment, outcome ascertainment, reverse causation, control for confounding, and selection bias. The key statistical tool to implement the approach is MR-BRT (meta-regression—Bayesian, regularized, trimmed 33 ), a flexible meta-regression tool that does not impose a log-linear relationship between the risk and outcome, but instead uses a spline ensemble to model non-linear relationships. MR-BRT also algorithmically detects and trims outliers in the input data, takes into account different reference and alternative exposure intervals in the data, and incorporates unexplained between-study heterogeneity in the uncertainty surrounding the mean relative risk (RR) curve (henceforth ‘risk curve’). For those risk-outcome relationships that meet the condition of statistical significance using conventionally estimated uncertainty intervals (i.e., without incorporating unexplained between-study heterogeneity), the burden of proof risk function (BPRF) is derived by calculating the 5th (if harmful) or 95th (if protective) quantile risk curve – inclusive of between-study heterogeneity – closest to the log RR of 0. The resulting BPRF is a conservative interpretation of the risk-outcome relationship based on all available evidence. The BPRF represents the smallest level of excess risk for a harmful risk factor or reduced risk for a protective risk factor that is consistent with the data, accounting for between-study heterogeneity. To quantify the strength of the evidence for the alcohol-IHD relationship, the BPRF can be summarized in a single metric, the risk-outcome score (ROS). The ROS is defined as the signed value of the average log RR of the BPRF across the 15th to 85th percentiles of alcohol consumption levels observed across available studies. The larger a positive ROS value, the stronger the alcohol-IHD association. For ease of interpretation, the ROS is converted into a star rating from one to five. A one-star rating (ROS < 0) indicates a weak alcohol-IHD relationship, and a five-star rating (ROS > 0.62) indicates a large effect size and strong evidence. Publication and reporting bias are evaluated with Egger’s regression and by visual inspection with funnel plots 34 . Further conceptual and technical details of the burden of proof approach are described in detail elsewhere 32 .
Using the burden of proof approach, we systematically re-evaluate all available eligible evidence from cohort, case-control, and MR studies published between 1970 and 2021 to conservatively quantify the dose-response relationship between alcohol consumption and IHD risk, calculated relative to risk at zero alcohol intake (i.e., current non-drinking, including lifetime abstinence or former use). We pool the evidence from all conventional observational studies combined, as well as individually for all three study designs, to estimate mean IHD risk curves. Based on patterns of results established by previous meta-analyses 4 , 35 , we also use data from conventional observational studies to estimate risk curves by IHD endpoint (morbidity or mortality) and further by sex, in addition to estimating risk curves for MI overall and by endpoint. We follow PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) guidelines 36 through all stages of this study (Supplementary Information section 1 , Fig. S1 and Tables S1 and S2 ) and comply with GATHER (Guidelines on Accurate and Transparent Health Estimates Reporting) recommendations 37 (Supplementary Information section 2 , Table S3 ). The main findings and research implications of this work are summarized in Table 1 .
We updated the systematic review on the dose-response relationship between alcohol consumption and IHD previously conducted for the Global Burden of Diseases, Injuries, and Risk Factors Study (GBD) 2020 1 . Of 4826 records identified in our updated systematic review (4769 from databases/registers and 57 by citation search and known literature), 11 were eligible based on our inclusion criteria and were included. In total, combined with the results of the previous systematic reviews 1 , 38 , information from 95 cohort studies 26 , 27 , 29 , 39 , 40 , 41 , 42 , 43 , 44 , 45 , 46 , 47 , 48 , 49 , 50 , 51 , 52 , 53 , 54 , 55 , 56 , 57 , 58 , 59 , 60 , 61 , 62 , 63 , 64 , 65 , 66 , 67 , 68 , 69 , 70 , 71 , 72 , 73 , 74 , 75 , 76 , 77 , 78 , 79 , 80 , 81 , 82 , 83 , 84 , 85 , 86 , 87 , 88 , 89 , 90 , 91 , 92 , 93 , 94 , 95 , 96 , 97 , 98 , 99 , 100 , 101 , 102 , 103 , 104 , 105 , 106 , 107 , 108 , 109 , 110 , 111 , 112 , 113 , 114 , 115 , 116 , 117 , 118 , 119 , 120 , 121 , 122 , 123 , 124 , 125 , 126 , 127 , 128 , 129 , 130 , 27 case-control studies 131 , 132 , 133 , 134 , 135 , 136 , 137 , 138 , 139 , 140 , 141 , 142 , 143 , 144 , 145 , 146 , 147 , 148 , 149 , 150 , 151 , 152 , 153 , 154 , 155 , 156 , 157 , and five MR studies 26 , 27 , 28 , 29 , 31 was included in our meta-analysis (see Supplementary Information section 1 , Fig. S1 , for the PRISMA diagram). Details on the extracted effect sizes, the design of each included study, underlying data sources, number of participants, duration of follow-up, number of cases and controls, and bias covariates that were evaluated and potentially adjusted for can be found in the Supplementary Information Sections 4 , 5 , and 6 .
Table 2 summarizes key metrics of each risk curve modeled, including estimates of mean RR and 95% UI (inclusive of between-study heterogeneity) at select alcohol exposure levels, the exposure level and RR and 95% UI at the nadir (i.e., lowest RR), the 85th percentile of exposure observed in the data and its corresponding RR and 95% UI, the BPRF averaged at the 15th and 85th percentile of exposure, the average excess risk or risk reduction according to the exposure-averaged BPRF, the ROS, the associated star rating, the potential presence of publication or reporting bias, and the number of studies included.
We found large variation in the association between alcohol consumption and IHD by study design. When we pooled the results of cohort and case-control studies, we observed an inverse association between alcohol at average consumption levels and IHD risk; that is, drinking average levels of alcohol was associated with a reduced IHD risk relative to drinking no alcohol. In contrast, we did not find a statistically significant association between alcohol consumption and IHD risk when pooling results from MR studies. When we subset the conventional observational studies to those reporting on IHD by endpoint, we found no association between alcohol consumption and IHD morbidity or mortality due to large unexplained heterogeneity between studies. When we further subset those studies that reported effect size estimates by sex, we found that average alcohol consumption levels were inversely associated with IHD morbidity in males and in females, and with IHD mortality in males but not in females. When we analyzed only the studies that reported on MI, we found significant inverse associations between average consumption levels and MI overall and with MI morbidity. Visualizations of the risk curves for morbidity and mortality of IHD and MI are provided in Supplementary Information Section 9 (Figs. S2a –c, S3a –c, and S4a–c ). Among all modeled risk curves for which a BPRF was calculated, the ROS ranged from −0.40 for MI mortality to 0.20 for MI morbidity. In the Supplementary Information, we also provide details on the RR and 95% UIs with and without between-study heterogeneity associated with each 10 g/day increase in consumption for each risk curve (Table S10 ), the parameter specifications of the model (Tables S11 and S12 ), and each risk curve from the main analysis estimated without trimming 10% of the data (Fig. S5a–l and Table S13 ).
Risk curve derived from conventional observational study data
The mean risk curve and 95% UI were first estimated by combining all evidence from eligible cohort and case-control studies that quantified the association between alcohol consumption and IHD risk. In total, information from 95 cohort studies and 27 case-control studies combining data from 7,059,652 participants were included. In total, 243,357 IHD events were recorded. Thirty-seven studies quantified the association between alcohol consumption and IHD morbidity only, and 44 studies evaluated only IHD mortality. The estimated alcohol-IHD association was adjusted for sex and age in all but one study. Seventy-five studies adjusted the effect sizes for sex, age, smoking, and at least four other covariates. We adjusted our risk curve for whether the study sample was under or over 50 years of age, whether the study outcome was consistent with the definition of IHD (according to the International Classification of Diseases [ICD]−9: 410-414; and ICD-10: I20-I25) or related to specified subtypes of IHD, whether the outcome was ascertained by self-report only or by at least one other measurement method, whether the study accounted for risk for reverse causation, whether the reference group was non-drinkers (including lifetime abstainers and former drinkers), and whether effect sizes were adjusted (1) for sex, age, smoking, and at least four other variables, (2) for apolipoprotein A1, and (3) for cholesterol, as these bias covariates were identified as significant by our algorithm.
Pooling all data from cohort and case-control studies, we found that alcohol consumption was inversely associated with IHD risk (Fig. 1 ). The risk curve was J-shaped – without crossing the null RR of 1 at high exposure levels – with a nadir of 0.69 (95% UI: 0.48–1.01) at 23 g/day. This means that compared to individuals who do not drink alcohol, the risk of IHD significantly decreases with increasing consumption up to 23 g/day, followed by a risk reduction that becomes less pronounced. The average BPRF calculated between 0 and 45 g/day of alcohol intake (the 15th and 85th percentiles of the exposure range observed in the data) was 0.96. Thus, when between-study heterogeneity is accounted for, a conservative interpretation of the evidence suggests drinking alcohol across the average intake range is associated with an average decrease in the risk of IHD of at least 4% compared to drinking no alcohol. This corresponds to a ROS of 0.04 and a star rating of two, which suggests that the association – on the basis of the available evidence – is weak. Although we algorithmically identified and trimmed 10% of the data to remove outliers, Egger’s regression and visual inspection of the funnel plot still indicated potential publication or reporting bias.

The panels show the log(relative risk) function, the relative risk function, and a modified funnel plot showing the residuals (relative to 0) on the x-axis and the estimated standard error that includes the reported standard error and between-study heterogeneity on the y-axis. RR relative risk, UI uncertainty interval. Source data are provided as a Source Data file.
Risk curve derived from case-control study data
Next, we estimated the mean risk curve and 95% UI for the relationship between alcohol consumption and IHD by subsetting the data to case-control studies only. We included a total of 27 case-control studies (including one nested case-control study) with data from 60,914 participants involving 16,892 IHD cases from Europe ( n = 15), North America ( n = 6), Asia ( n = 4), and Oceania ( n = 2). Effect sizes were adjusted for sex and age in most studies ( n = 25). Seventeen of these studies further adjusted for smoking and at least four other covariates. The majority of case-control studies accounted for the risk of reverse causation ( n = 25). We did not adjust our risk curve for bias covariates, as our algorithm did not identify any as significant.
Evaluating only data from case-control studies, we observed a J-shaped relationship between alcohol consumption and IHD risk, with a nadir of 0.65 (0.50–0.85) at 23 g/day (Fig. 2 ). The inverse association between alcohol consumption and IHD risk reversed at an intake level of 61 g/day. In other words, alcohol consumption between >0 and 60 g/day was associated with a lower risk compared to no consumption, while consumption at higher levels was associated with increased IHD risk. However, the curve above this level is flat, implying that the association between alcohol and increased IHD risk is the same between 61 and 100 g/day, relative to not drinking any alcohol. The BPRF averaged across the exposure range between the 15th and 85th percentiles, or 0–45 g/day, was 0.87, which translates to a 13% average reduction in IHD risk across the average range of consumption. This corresponds to a ROS of 0.14 and a three-star rating. After trimming 10% of the data, no potential publication or reporting bias was found.

The panels show the log(relative risk) function, the relative risk function, and a modified funnel plot showing the residuals (relative to 0) on the x-axis and the estimated standard deviation that includes the reported standard deviation and between-study heterogeneity on the y-axis. RR relative risk, UI uncertainty interval. Source data are provided as a Source Data file.
Risk curve derived from cohort study data
We also estimated the mean risk curve and 95% UI for the relationship between alcohol consumption and IHD using only data from cohort studies. In total, 95 cohort studies – of which one was a retrospective cohort study – with data from 6,998,738 participants were included. Overall, 226,465 IHD events were recorded. Most data were from Europe ( n = 43) and North America ( n = 33), while a small number of studies were conducted in Asia ( n = 14), Oceania ( n = 3), and South America ( n = 2). The majority of studies adjusted effect sizes for sex and age ( n = 76). Fifty-seven of these studies also adjusted for smoking and at least four other covariates. Out of all cohort studies included, 88 accounted for the risk of reverse causation. We adjusted our risk curve for whether the study outcome was consistent with the definition of IHD or related to specified subtypes of IHD, and whether effect sizes were adjusted for apolipoprotein A1, as these bias covariates were identified as significant by our algorithm.
When only data from cohort studies were evaluated, we found a J-shaped relationship between alcohol consumption and IHD risk that did not cross the null RR of 1 at high exposure levels, with a nadir of 0.69 (0.47–1.01) at 23 g/day (Fig. 3 ). The shape of the risk curve was almost identical to the curve estimated with all conventional observational studies (i.e., cohort and case-control studies combined). When we calculated the average BPRF of 0.95 between the 15th and 85th percentiles of observed alcohol exposure (0–50 g/day), we found that alcohol consumption across the average intake range was associated with an average reduction in IHD risk of at least 5%. This corresponds to a ROS of 0.05 and a two-star rating. We identified potential publication or reporting bias after 10% of the data were trimmed.

Risk curve derived from Mendelian randomization study data
Lastly, we pooled evidence on the relationship between genetically predicted alcohol consumption and IHD risk from MR studies. Four MR studies were considered eligible for inclusion in our main analysis, with data from 559,708 participants from China ( n = 2), the Republic of Korea ( n = 1), and the United Kingdom ( n = 1). Overall, 22,134 IHD events were recorded. Three studies used the rs671 ALDH2 genotype found in Asian populations, one study additionally used the rs1229984 ADH1B variant, and one study used the rs1229984 ADH1B Arg47His variant and a combination of 25 SNPs as IVs. All studies used the two-stage least squares (2SLS) method to estimate the association, and one study additionally applied the inverse-variance-weighted (IVW) method and multivariable MR (MVMR). For the study that used multiple methods to estimate effect sizes, we used the 2SLS estimates for our main analysis. Further details on the included studies are provided in Supplementary Information section 4 (Table S6 ). Due to limited input data, we elected not to trim 10% of the observations. We adjusted our risk curve for whether the endpoint of the study outcome was mortality and whether the associations were adjusted for sex and/or age, as these bias covariates were identified as significant by our algorithm.
We did not find any significant association between genetically predicted alcohol consumption and IHD risk using data from MR studies (Fig. 4 ). No potential publication or reporting bias was detected.

As sensitivity analyses, we modeled risk curves with effect sizes estimated from data generated by Lankester et al. 28 using IVW and MVMR methods. We also used effect sizes from Biddinger et al. 31 , obtained using non-linear MR with the residual method, instead of those from Lankester et al. 28 in our main model (both were estimated with UK Biobank data) to estimate a risk curve. Again, we did not find a significant association between genetically predicted alcohol consumption and IHD risk (see Supplementary Information Section 10 , Fig. S6a–c and Table S14 ). To test for consistency with the risk curve we estimated using all included cohort studies, we also pooled the conventionally estimated effect sizes provided in the four MR studies. We did not observe an association between alcohol consumption and IHD risk due to large unexplained heterogeneity between studies (see Supplementary Information Section 10 , Fig. S7, and Table S14 ). Lastly, we pooled cohort studies that included data from China, the Republic of Korea, and the United Kingdom to account for potential geographic influences. Again, we did not find a significant association between alcohol consumption and IHD risk (see Supplementary Information Section 10 , Fig. S8, and Table S14 ).
Conventional observational and MR studies published to date provide conflicting estimates of the relationship between alcohol consumption and IHD. We conducted an updated systematic review and conservatively re-evaluated existing evidence on the alcohol-IHD relationship using the burden of proof approach. We synthesized evidence from cohort and case-control studies combined and separately and from MR studies to assess the dose-response relationship between alcohol consumption and IHD risk and to compare results across different study designs. It is anticipated that the present synthesis of evidence will be incorporated into upcoming iterations of GBD.
Our estimate of the association between genetically predicted alcohol consumption and IHD runs counter to our estimates from the self-report data and those of other previous meta-analyses 4 , 35 , 158 that pooled conventional observational studies. Based on the conservative burden of proof interpretation of the data, our results suggested an inverse association between alcohol and IHD when all conventional observational studies were pooled (alcohol intake was associated with a reduction in IHD risk by an average of at least 4% across average consumption levels; two-star rating). In evaluating only cohort studies, we again found an inverse association between alcohol consumption and IHD (alcohol intake was associated with a reduction in IHD risk by an average of at least 5% at average consumption levels; two-star rating). In contrast, when we pooled only case-control studies, we estimated that average levels of alcohol consumption were associated with at least a 13% average decrease in IHD risk (three-star rating), but the inverse association reversed when consumption exceeded 60 g/day, suggesting that alcohol above this level is associated with a slight increase in IHD risk. Our analysis of the available evidence from MR studies showed no association between genetically predicted alcohol consumption and IHD.
Various potential biases and differences in study designs may have contributed to the conflicting findings. In our introduction, we summarized important sources of bias in conventional observational studies of the association between alcohol consumption and IHD. Of greatest concern are residual and unmeasured confounding and reverse causation, the effects of which are difficult to eliminate in conventional observational studies. By using SNPs within an IV approach to predict exposure, MR – in theory – eliminates these sources of bias and allows for more robust estimates of causal effects. Bias may still occur, however, when using MR to estimate the association between alcohol and IHD 159 , 160 . There is always the risk of horizontal pleiotropy in MR – that is, the genetic variant may affect the outcome via pathways other than exposure 161 . The IV assumption of exclusion restriction is, for example, violated if only a single measurement of alcohol consumption is used in MR 162 ; because alcohol consumption varies over the life course, the gene directly impacts IHD through intake at time points other than that used in the MR analysis. To date, MR studies have not succeeded in separately capturing the multidimensional effects of alcohol intake on IHD risk (i.e., effects of average alcohol consumption measured through frequency-quantity, in addition to the effects of HED) 159 because the genes used to date only target average alcohol consumption that encompasses intake both at average consumption levels and HED. In other words, the instruments used are not able to separate out the individual effects of these two different dimensions of alcohol consumption on IHD risk using MR. Moreover, reverse causation may occur through cross-generational effects 160 , 163 , as the same genetic variants predispose both the individual and at least one of his or her parents to (increased) alcohol consumption. In this situation, IHD risk could be associated with the parents’ genetically predicted alcohol consumption and not with the individual’s own consumption. None of the MR studies included accounted for cross-generational effects, which possibly introduced bias in the effect estimates. It is important to note that bias by ancestry might also occur in conventional observational studies 164 . In summary, estimates of the alcohol-IHD association are prone to bias in all three study designs, limiting inferences of causation.
The large difference in the number of available MR versus conventional observational studies, the substantially divergent results derived from the different study types, and the rapidly developing field of MR clearly argue for further investigation of MR as a means to quantify the association between alcohol consumption and IHD risk. Future studies should investigate non-linearity in the relationship using non-linear MR methods. The residual method, commonly applied in non-linear MR studies such as Biddinger et al. 31 , assumes a constant, linear relationship between the genetic IV and the exposure in the study population; a strong assumption that may result in biased estimates and inflated type I error rates if the relationship varies by population strata 165 . However, by log-transforming the exposure, the relationships between the genetic IV and the exposure as expressed on a logarithmic scale may be more homogeneous across strata, possibly reducing the bias effect of violating the assumption of a constant, linear relationship. Alternatively, or in conjunction, the recently developed doubly ranked method, which obviates the need for this assumption, could be used 166 . Since methodology for non-linear MR is an active field of study 167 , potential limitations of currently available methods should be acknowledged and latest guidelines be followed 168 . Future MR studies should further (i) employ sensitivity analyses such as the MR weighted median method 169 to relax the exclusion restriction assumption that may be violated, as well as applying other methods such as the MR-Egger intercept test; (ii) use methods such as g-estimation of structural mean models 162 to adequately account for temporal variation in alcohol consumption in MR, and (iii) attempt to disaggregate the effects of alcohol on IHD by dimension in MR, potentially through the use of MVMR 164 . General recommendations to overcome common MR limitations are described in greater detail elsewhere 159 , 163 , 170 , 171 and should be carefully considered. With respect to prospective cohort studies used to assess the alcohol-IHD relationship, they should, at a minimum: (i) adjust the association between alcohol consumption and IHD for all potential confounders identified, for example, using a causal directed acyclic graph, and (ii) account for reverse causation introduced by sick quitters and by drinkers who changed their consumption. If possible, they should also (iii) use alcohol biomarkers as objective measures of alcohol consumption instead of or in addition to self-reported consumption to reduce bias through measurement error, (iv) investigate the association between IHD and HED, in addition to average alcohol consumption, and (v) when multiple measures of alcohol consumption and potential confounders are available over time, use g-methods to reduce bias through confounding as fully as possible within the limitations of the study design. However, some bias – due, for instance, to unmeasured confounding in conventional observational and to horizontal pleiotropy in MR studies – is likely inevitable, and the interpretation of estimates should be appropriately cautious, in accordance with the methods used in the study.
With the introduction of the Moderate Alcohol and Cardiovascular Health Trial (MACH15) 172 , randomized controlled trials (RCTs) have been revisited as a way to study the long-term effects of low to moderate alcohol consumption on cardiovascular disease, including IHD. In 2018, soon after the initiation of MACH15, the National Institutes of Health terminated funding 173 , reportedly due to concerns about study design and irregularities in the development of funding opportunities 174 . Although MACH15 was terminated, its initiation represented a previously rarely considered step toward investigating the alcohol-IHD relationship using an RCT 175 . However, while the insights from an RCT are likely to be invaluable, the implementation is fraught with potential issues. Due to the growing number of studies suggesting increased disease risk, including cancer 3 , 4 , associated with alcohol use even at very low levels 176 , the use of RCTs to study alcohol consumption is ethically questionable 177 . A less charged approach could include the emulation of target trials 178 using existing observational data (e.g., from large-scale prospective cohort studies such as the UK Biobank 179 , Atherosclerosis Risk in Communities Study 180 , or the Framingham Heart Study 181 ) in lieu of real trials to gather evidence on the potential cardiovascular effects of alcohol. Trials like MACH15 can be emulated, following the proposed trial protocols as closely as the observational dataset used for the analysis allows. Safety and ethical concerns, such as those related to eligibility criteria, initiation/increase in consumption, and limited follow-up duration, will be eliminated because the data will have already been collected. This framework allows for hypothetical trials investigating ethically challenging or even untenable questions, such as the long-term effects of heavy (episodic) drinking on IHD risk, to be emulated and inferences to broader populations drawn.
There are several limitations that must be considered when interpreting our findings. First, record screening for our systematic review was not conducted in a double-blinded fashion. Second, we did not have sufficient evidence to estimate and examine potential differential associations of alcohol consumption with IHD risk by beverage type or with MI endpoints by sex. Third, despite using a flexible meta-regression tool that overcame several limitations common to meta-analyses, the results of our meta-analysis were only as good as the quality of the studies included. We were able, however, to address the issue of varying quality of input data by adjusting for bias covariates that corresponded to core study characteristics in our analyses. Fourth, because we were only able to include one-sample MR studies that captured genetically predicted alcohol consumption, statistical power may be lower than would have been possible with the inclusion of two-sample MR studies, and studies that directly estimated gene-IHD associations were not considered 23 . Finally, we were not able to account for participants’ HED status when pooling effect size estimates from conventional observational studies. Given established differences in IHD risk for drinkers with and without HED 35 and the fact that more than one in three drinkers reports HED 6 , we would expect that the decreased average risk we found at moderate levels of alcohol consumption would be attenuated (i.e., approach the IHD risk of non-drinkers) if the presence of HED was taken into account.
Using the burden of proof approach 32 , we conservatively re-evaluated the dose-response relationship between alcohol consumption and IHD risk based on existing cohort, case-control, and MR data. Consistent with previous meta-analyses, we found that alcohol at average consumption levels was inversely associated with IHD when we pooled conventional observational studies. This finding was supported when aggregating: (i) all studies, (ii) only cohort studies, (iii) only case-control studies, (iv) studies examining IHD morbidity in females and males, (v) studies examining IHD mortality in males, and (vi) studies examining MI morbidity. In contrast, we found no association between genetically predicted alcohol consumption and IHD risk based on data from MR studies. Our confirmation of the conflicting results derived from self-reported versus genetically predicted alcohol use data highlights the need to advance methodologies that will provide more definitive answers to this critical public health question. Given the limitations of randomized trials, we advocate using advanced MR techniques and emulating target trials using observational data to generate more conclusive evidence on the long-term effects of alcohol consumption on IHD risk.
This study was approved by the University of Washington IRB Committee (study #9060).
The burden of proof approach is a six-step framework for conducting meta-analysis 32 : (1) data from published studies that quantified the dose-response relationship between alcohol consumption and ischemic heart disease (IHD) risk were systematically identified and obtained; (2) the shape of the mean relative risk (RR) curve (henceforth ‘risk curve’) and associated uncertainty was estimated using a quadratic spline and algorithmic trimming of outliers; (3) the risk curve was tested and adjusted for biases due to study attributes; (4) unexplained between-study heterogeneity was quantified, adjusting for within-study correlation and number of studies included; (5) the evidence for small-study effects was evaluated to identify potential risks of publication or reporting bias; and (6) the burden of proof risk function (BPRF) – a conservative interpretation of the average risk across the exposure range found in the data – was estimated relative to IHD risk at zero alcohol intake. The BPRF was converted to a risk-outcome score (ROS) that was mapped to a star rating from one to five to provide an intuitive interpretation of the magnitude and direction of the dose-response relationship between alcohol consumption and IHD risk.
We calculated the mean RR and 95% uncertainty intervals (UIs) for IHD associated with levels of alcohol consumption separately with all evidence available from conventional observational studies and from Mendelian randomization (MR) studies. For the risk curves that met the condition of statistical significance when the conventional 95% UI that does not include unexplained between-study heterogeneity was evaluated, we calculated the BPRF, ROS, and star rating. Based on input data from conventional observational studies, we also estimated these metrics by study design (cohort studies, case-control studies), and by IHD endpoint (morbidity, mortality) for both sexes (females, males) and sex-specific. For sex-stratified analyses, we only considered studies that reported effect sizes for both females and males to allow direct comparison of IHD risk across different exposure levels; however, we did not collect information about the method each study used to determine sex. We also estimated risk curves for myocardial infarction (MI), overall and by endpoint, using data from conventional observational studies. As a comparison, we also estimated each risk curve without trimming 10% of the input data. We did not consider MI as an outcome or disaggregate findings by sex or endpoint for MR studies due to insufficient data.
With respect to MR studies, several statistical methods are typically used to estimate the associations between genetically predicted exposure and health outcomes (e.g., two-stage least squares [2SLS], inverse-variance-weighted [IVW], multivariable Mendelian randomization [MVMR]). For our main analysis synthesizing evidence from MR studies, we included the reported effect sizes estimated using 2SLS if a study applied multiple methods because this method was common to all included studies. In sensitivity analyses, we used the effect sizes obtained by other MR methods (i.e., IVW, MVMR, and non-linear MR) and estimated the mean risk curve and uncertainty. We also pooled conventionally estimated effect sizes from MR studies to allow comparison with the risk curve estimated with cohort studies. Due to limited input data from MR studies, we elected not to trim 10% of the observations. Furthermore, we estimated the risk curve from cohort studies with data from countries that corresponded to those included in MR studies (China, the Republic of Korea, and the United Kingdom). Due to a lack of data, we were unable to estimate a risk curve from case-control studies in these geographic regions.
Conducting the systematic review
In step one of the burden of proof approach, data for the dose-response relationship between alcohol consumption and IHD risk were systematically identified, reviewed, and extracted. We updated a previously published systematic review 1 in PubMed that identified all studies evaluating the dose-response relationship between alcohol consumption and risk of IHD morbidity or mortality from January 1, 1970, to December 31, 2019. In our update, we additionally considered all studies up to and including December 31, 2021, for eligibility. We searched articles in PubMed on March 21, 2022, with the following search string: (alcoholic beverage[MeSH Terms] OR drinking behavior[MeSH Terms] OR “alcohol”[Title/Abstract]) AND (Coronary Artery Disease[Mesh] OR Myocardial Ischemia[Mesh] OR atherosclerosis[Mesh] OR Coronary Artery Disease[TiAb] OR Myocardial Ischemia[TiAb] OR cardiac ischemia[TiAb] OR silent ischemia[TiAb] OR atherosclerosis Outdent [TiAb] OR Ischemic heart disease[TiAb] OR Ischemic heart disease[TiAb] OR coronary heart disease[TiAb] OR myocardial infarction[TiAb] OR heart attack[TiAb] OR heart infarction[TiAb]) AND (Risk[MeSH Terms] OR Odds Ratio[MeSH Terms] OR “risk”[Title/Abstract] OR “odds ratio”[Title/Abstract] OR “cross-product ratio”[Title/Abstract] OR “hazards ratio”[Title/Abstract] OR “hazard ratio”[Title/Abstract]) AND (“1970/01/01”[PDat]: “2021/12/31”[PDat]) AND (English[LA]) NOT (animals[MeSH Terms] NOT Humans[MeSH Terms]). Studies were eligible for inclusion if they met all of the following criteria: were published between January 1, 1970, and December 31, 2021; were a cohort study, case-control study, or MR study; described an association between alcohol consumption and IHD and reported an effect size estimate (relative risk, hazard ratio, odds ratio); and used a continuous dose as exposure of alcohol consumption. Studies were excluded if they met any of the following criteria: were an aggregate study (meta-analysis or pooled cohort); utilized a study design not designated for inclusion in this analysis: not a cohort study, case-control study, or MR study; were a duplicate study: the underlying sample of the study had also been analyzed elsewhere (we always considered the analysis with the longest follow-up for cohort studies or the most recently published analysis for MR studies); did not report on the exposure of interest: reported on combined exposure of alcohol and drug use or reported alcohol consumption in a non-continuous way; reported an outcome that was not IHD or a composite outcome that included but was not limited to IHD, or outcomes lacked specificity, such as cardiovascular disease or all-cause mortality; were not in English; and were animal studies. All screenings of titles and abstracts of identified records, as well as full texts of potentially eligible studies, and extraction of included studies, were done by a single reviewer (SC or HL) independently. If eligible, studies were extracted for study characteristics, exposure, outcome, adjusted confounders, and effect sizes and their uncertainty. While the previous systematic review only considered cohort and case-control studies, our update also included MR studies. We chose to consider only ‘one-sample’ MR studies, i.e., those in which genes, risk factors, and outcomes were measured in the same participants, and not ‘two-sample’ MR studies in which two different samples were used for the MR analysis so that we could fully capture study-specific information. We re-screened previously identified records for MR studies to consider all published MR studies in the defined time period. We also identified and included in our sensitivity analysis an MR study published in 2022 31 which used a non-linear MR method to estimate the association between genetically predicted alcohol consumption and IHD. When eligible studies reported both MR and conventionally estimated effect sizes (i.e., for the association between self-reported alcohol consumption and IHD risk), we extracted both. If studies used the same underlying sample and investigated the same outcome in the same strata, we included the study that had the longest follow-up. This did not apply when the same samples were used in conventional observational and MR studies, because they were treated separately when estimating the risk curve of alcohol consumption and IHD. Continuous exposure of alcohol consumption was defined as a frequency-quantity measure 182 and converted to g/day. IHD was defined according to the International Classification of Diseases (ICD)−9, 410-414, and ICD-10, I20-I25.
The raw data were extracted with a standardized extraction sheet (see Supplementary Information Section 3 , Table S4 ). For conventional observational studies, when multiple effect sizes were estimated from differently adjusted regression models, we used those estimated with the model reported to be fully adjusted or the one with the most covariates. In the majority of studies, alcohol consumption was categorized based on the exposure range available in the data. If the lower end of a categorical exposure range (e.g., <10 g/day) of an effect size was not specified in the input data, we assumed that this was 0 g/day. If the upper end was not specified (e.g., >20 g/day), it was calculated by multiplying the lower end of the categorical exposure range by 1.5. When the association between alcohol and IHD risk was reported as a linear slope, the average consumption level in the sample was multiplied by the logarithm of the effect size to effectively render it categorical. From the MR study which employed non-linear MR 31 , five effect sizes and their uncertainty were extracted at equal intervals across the reported range of alcohol exposure using WebPlotDigitizer. To account for the fact that these effect sizes were derived from the same non-linear risk curve, we adjusted the extracted standard errors by multiplying them by the square root of five (i.e., the number of extracted effect sizes). Details on data sources are provided in Supplementary Information Section 4 .
Estimating the shape of the risk-outcome relationship
In step two, the shape of the dose-response relationship (i.e., ‘signal’) between alcohol consumption and IHD risk was estimated relative to risk at zero alcohol intake. The meta-regression tool MR-BRT (meta-regression—Bayesian, regularized, trimmed), developed by Zheng et al. 33 , was used for modeling. To allow for non-linearity, thus relaxing the common assumption of a log-linear relationship, a quadratic spline with two interior knots was used for estimating the risk curve 33 . We used the following three risk measures from included studies: RRs, odds ratios (ORs), and hazard ratios (HRs). ORs were treated as equivalent to RRs and HRs based on the rare outcome assumption. To counteract the potential influence of knot placement on the shape of the risk curve when using splines, an ensemble model approach was applied. Fifty component models with random knot placements across the exposure domain were computed. These were combined into an ensemble by weighting each model based on model fit and variation (i.e., smoothness of fit to the data). To prevent bias from outliers, a robust likelihood-based approach was applied to trim 10% of the observations. Technical details on estimating the risk curve, use of splines, the trimming procedure, the ensemble model approach, and uncertainty estimation are described elsewhere 32 , 33 . Details on the model specifications for each risk curve are provided in Supplementary Information section 8 . We first estimated each risk curve without trimming input data to visualize the shape of the curve, which informed knot placement and whether to set a left and/or right linear tail when data were sparse at low or high exposure levels (see Supplementary Information Section 10 , Fig. S5a–l ).
Testing and adjusting for biases across study designs and characteristics
In step three, the risk curve was tested and adjusted for systematic biases due to study attributes. According to the Grading of Recommendations Assessment, Development, and Evaluation (GRADE) criteria 183 , the following six bias sources were quantified: representativeness of the study population, exposure assessment, outcome ascertainment, reverse causation, control for confounding, and selection bias. Representativeness was quantified by whether the study sample came from a location that was representative of the underlying geography. Exposure assessment was quantified by whether alcohol consumption was recorded once or more than once in conventional observational studies, or with only one or multiple SNPs in MR studies. Outcome ascertainment was quantified by whether IHD was ascertained by self-report only or by at least one other measurement method. Reverse causation was quantified by whether increased IHD risk among participants who reduced or stopped drinking was accounted for (e.g., by separating former drinkers from lifetime abstainers). Control for confounding factors was quantified by which and how many covariates the effect sizes were adjusted for (i.e., through stratification, matching, weighting, or standardization). Because the most adjusted effect sizes in each study were extracted in the systematic review process and thus may have been adjusted for mediators, we additionally quantified a bias covariate for each of the following potential mediators of the alcohol-IHD relationship: body mass index, blood pressure, cholesterol (excluding high-density lipoprotein cholesterol), fibrinogen, apolipoprotein A1, and adiponectin. Selection bias was quantified by whether study participants were selected and included based on pre-existing disease states. We also quantified and considered as possible bias covariates whether the reference group was non-drinkers, including lifetime abstainers and former drinkers; whether the sample was under or over 50 years of age; whether IHD morbidity, mortality, or both endpoints were used; whether the outcome mapped to IHD or referred only to subtypes of IHD; whether the outcome mapped to MI; and what study design (cohort or case-control) was used when conventional observational studies were pooled. Details on quantified bias covariates for all included studies are provided in Supplementary Information section 5 (Tables S7 and S8 ). Using a Lasso approach 184 , the bias covariates were first ranked. They were then included sequentially, based on their ranking, as effect modifiers of the ‘signal’ obtained in step two in a linear meta-regression. Significant bias covariates were included in modeling the final risk curve. Technical details of the Lasso procedure are described elsewhere 32 .
Quantifying between-study heterogeneity, accounting for heterogeneity, uncertainty, and small number of studies
In step four, the between-study heterogeneity was quantified, accounting for heterogeneity, uncertainty, and small number of studies. In a final linear mixed-effects model, the log RRs were regressed against the ‘signal’ and selected bias covariates, with a random intercept to account for within-study correlation and a study-specific random slope with respect to the ‘signal’ to account for between-study heterogeneity. A Fisher information matrix was used to estimate the uncertainty associated with between-study heterogeneity 185 because heterogeneity is easily underestimated or may be zero when only a small number of studies are available. We estimated the mean risk curve with a 95% UI that incorporated between-study heterogeneity, and we additionally estimated a 95% UI without between-study heterogeneity as done in conventional meta-regressions (see Supplementary Information Section 7 , Table S10 ). The 95% UI incorporating between-study heterogeneity was calculated from the posterior uncertainty of the fixed effects (i.e., the ‘signal’ and selected bias covariates) and the 95% quantile of the between-study heterogeneity. The estimate of between-study heterogeneity and the estimate of the uncertainty of the between-study heterogeneity were used to determine the 95% quantile of the between-study heterogeneity. Technical details of quantifying uncertainty of between-study heterogeneity are described elsewhere 32 .
Evaluating potential for publication or reporting bias
In step five, the potential for publication or reporting bias was evaluated. The trimming algorithm used in step two helps protect against these biases, so risk curves found to have publication or reporting bias using the following methods were derived from data that still had bias even after trimming. Publication or reporting bias was evaluated using Egger’s regression 34 and visual inspection using funnel plots. Egger’s regression tested for a significant correlation between residuals of the RR estimates and their standard errors. Funnel plots showed the residuals of the risk curve against their standard errors. We reported publication or reporting bias when identified.
Estimating the burden of proof risk function
In step six, the BPRF was calculated for risk-outcome relationships that were statistically significant when evaluating the conventional 95% UI without between-study heterogeneity. The BPRF is either the 5th (if harmful) or the 95th (if protective) quantile curve inclusive of between-study heterogeneity that is closest to the RR line at 1 (i.e., null); it indicates a conservative estimate of a harmful or protective association at each exposure level, based on the available evidence. The mean risk curve, 95% UIs (with and without between-study heterogeneity), and BPRF (where applicable) are visualized along with included effect sizes using the midpoint of each alternative exposure range (trimmed data points are marked with a red x), with alcohol consumption in g/day on the x-axis and (log)RR on the y-axis.
We calculated the ROS as the average log RR of the BPRF between the 15th and 85th percentiles of alcohol exposure observed in the study data. The ROS summarizes the association of the exposure with the health outcome in a single measure. A higher, positive ROS indicates a larger association, while a negative ROS indicates a weak association. The ROS is identical for protective and harmful risks since it is based on the magnitude of the log RR. For example, a mean log BPRF between the 15th and 85th percentiles of exposure of −0.6 (protective association) and a mean log BPRF of 0.6 (harmful association) would both correspond to a ROS of 0.6. The ROS was then translated into a star rating, representing a conservative interpretation of all available evidence. A star rating of 1 (ROS: <0) indicates weak evidence of an association, a star rating of 2 (ROS: 0–0.14) indicates a >0–15% increased or >0–13% decreased risk, a star rating of 3 (ROS: >0.14–0.41) indicates a >15–50% increased or >13–34% decreased risk, a star rating of 4 (ROS: >0.41–0.62) indicates a >50–85% increased or >34–46% decreased risk, and a star rating of 5 (ROS: >0.62) indicates a >85% increased or >46% decreased risk.
Statistics & reproducibility
The statistical analyses conducted in this study are described above in detail. No statistical method was used to predetermine the sample size. When analyzing data from cohort and case-control studies, we excluded 10% of observations using a trimming algorithm; when analyzing data from MR studies, we did not exclude any observations. As all data used in this meta-analysis were from observational studies, no experiments were conducted, and no randomization or blinding took place.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The findings from this study were produced using data extracted from published literature. The relevant studies were identified through a systematic literature review and can all be accessed online as referenced in the current paper 26 , 27 , 28 , 29 , 31 , 39 , 40 , 41 , 42 , 43 , 44 , 45 , 46 , 47 , 48 , 49 , 50 , 51 , 52 , 53 , 54 , 55 , 56 , 57 , 58 , 59 , 60 , 61 , 62 , 63 , 64 , 65 , 66 , 67 , 68 , 69 , 70 , 71 , 72 , 73 , 74 , 75 , 76 , 77 , 78 , 79 , 80 , 81 , 82 , 83 , 84 , 85 , 86 , 87 , 88 , 89 , 90 , 91 , 92 , 93 , 94 , 95 , 96 , 97 , 98 , 99 , 100 , 101 , 102 , 103 , 104 , 105 , 106 , 107 , 108 , 109 , 110 , 111 , 112 , 113 , 114 , 115 , 116 , 117 , 118 , 119 , 120 , 121 , 122 , 123 , 124 , 125 , 126 , 127 , 128 , 129 , 130 , 131 , 132 , 133 , 134 , 135 , 136 , 137 , 138 , 139 , 140 , 141 , 142 , 143 , 144 , 145 , 146 , 147 , 148 , 149 , 150 , 151 , 152 , 153 , 154 , 155 , 156 , 157 . Further details on the relevant studies can be found on the GHDx website ( https://ghdx.healthdata.org/record/ihme-data/gbd-alcohol-ihd-bop-risk-outcome-scores ). Study characteristics of all relevant studies included in the analyses are also provided in Supplementary Information Section 4 (Tables S5 and S6 ). The template of the data collection form is provided in Supplementary Information section 3 (Table S4 ). The source data includes processed data from these studies that underlie our estimates. Source data are provided with this paper.
Code availability
Analyses were carried out using R version 4.0.5 and Python version 3.10.9. All code used for these analyses is publicly available online ( https://github.com/ihmeuw-msca/burden-of-proof ).
Bryazka, D. et al. Population-level risks of alcohol consumption by amount, geography, age, sex, and year: a systematic analysis for the Global Burden of Disease Study 2020. Lancet 400 , 185–235 (2022).
Article Google Scholar
World Health Organization. Global Status Report on Alcohol and Health 2018 . (World Health Organization, Geneva, Switzerland, 2019).
Bagnardi, V. et al. Alcohol consumption and site-specific cancer risk: a comprehensive dose–response meta-analysis. Br. J. Cancer 112 , 580–593 (2015).
Article CAS PubMed Google Scholar
Wood, A. M. et al. Risk thresholds for alcohol consumption: combined analysis of individual-participant data for 599 912 current drinkers in 83 prospective studies. Lancet 391 , 1513–1523 (2018).
Article PubMed PubMed Central Google Scholar
Goel, S., Sharma, A. & Garg, A. Effect of alcohol consumption on cardiovascular health. Curr. Cardiol. Rep. 20 , 19 (2018).
Article PubMed Google Scholar
Manthey, J. et al. Global alcohol exposure between 1990 and 2017 and forecasts until 2030: a modelling study. Lancet 393 , 2493–2502 (2019).
Vos, T. et al. Global burden of 369 diseases and injuries in 204 countries and territories, 1990–2019: a systematic analysis for the Global Burden of Disease Study 2019. Lancet 396 , 1204–1222 (2020).
Brien, S. E., Ronksley, P. E., Turner, B. J., Mukamal, K. J. & Ghali, W. A. Effect of alcohol consumption on biological markers associated with risk of coronary heart disease: systematic review and meta-analysis of interventional studies. BMJ 342 , d636 (2011).
Rehm, J. et al. The relationship between different dimensions of alcohol use and the burden of disease—an update. Addiction 112 , 968–1001 (2017).
Roerecke, M. & Rehm, J. Irregular heavy drinking occasions and risk of ischemic heart disease: a systematic review and meta-analysis. Am. J. Epidemiol. 171 , 633–644 (2010).
Hernan, M. A. & Robin, J. M. Causal Inference: What If . (CRC Press, 2023).
Marmot, M. Alcohol and coronary heart disease. Int. J. Epidemiol. 13 , 160–167 (1984).
Shaper, A. G., Wannamethee, G. & Walker, M. Alcohol and mortality in British men: explaining the U-shaped curve. Lancet 332 , 1267–1273 (1988).
Davis, C. G., Thake, J. & Vilhena, N. Social desirability biases in self-reported alcohol consumption and harms. Addict. Behav. 35 , 302–311 (2010).
Mansournia, M. A., Etminan, M., Danaei, G., Kaufman, J. S. & Collins, G. Handling time varying confounding in observational research. BMJ 359 , j4587 (2017).
Ilomäki, J. et al. Relationship between alcohol consumption and myocardial infarction among ageing men using a marginal structural model. Eur. J. Public Health 22 , 825–830 (2012).
Lawlor, D. A., Harbord, R. M., Sterne, J. A. C., Timpson, N. & Davey Smith, G. Mendelian randomization: using genes as instruments for making causal inferences in epidemiology. Stat. Med. 27 , 1133–1163 (2008).
Article MathSciNet PubMed Google Scholar
Burgess, S., Timpson, N. J., Ebrahim, S. & Davey Smith, G. Mendelian randomization: where are we now and where are we going? Int. J. Epidemiol. 44 , 379–388 (2015).
Sleiman, P. M. & Grant, S. F. Mendelian randomization in the era of genomewide association studies. Clin. Chem. 56 , 723–728 (2010).
Davies, N. M., Holmes, M. V. & Davey Smith, G. Reading Mendelian randomisation studies: a guide, glossary, and checklist for clinicians. BMJ 362 , k601 (2018).
de Leeuw, C., Savage, J., Bucur, I. G., Heskes, T. & Posthuma, D. Understanding the assumptions underlying Mendelian randomization. Eur. J. Hum. Genet. 30 , 653–660 (2022).
Sheehan, N. A., Didelez, V., Burton, P. R. & Tobin, M. D. Mendelian randomisation and causal inference in observational epidemiology. PLoS Med. 5 , e177 (2008).
Van de Luitgaarden, I. A. et al. Alcohol consumption in relation to cardiovascular diseases and mortality: a systematic review of Mendelian randomization studies. Eur. J. Epidemiol. 1–15 (2021).
Edenberg, H. J. The genetics of alcohol metabolism: role of alcohol dehydrogenase and aldehyde dehydrogenase variants. Alcohol Res. Health 30 , 5–13 (2007).
PubMed PubMed Central Google Scholar
Gelernter, J. et al. Genome-wide association study of maximum habitual alcohol intake in >140,000 U.S. European and African American veterans yields novel risk loci. Biol. Psychiatry 86 , 365–376 (2019).
Article CAS PubMed PubMed Central Google Scholar
Millwood, I. Y. et al. Conventional and genetic evidence on alcohol and vascular disease aetiology: a prospective study of 500 000 men and women in China. Lancet 393 , 1831–1842 (2019).
Au Yeung, S. L. et al. Moderate alcohol use and cardiovascular disease from Mendelian randomization. PLoS ONE 8 , e68054 (2013).
Article ADS PubMed PubMed Central Google Scholar
Lankester, J., Zanetti, D., Ingelsson, E. & Assimes, T. L. Alcohol use and cardiometabolic risk in the UK Biobank: a Mendelian randomization study. PLoS ONE 16 , e0255801 (2021).
Cho, Y. et al. Alcohol intake and cardiovascular risk factors: a Mendelian randomisation study. Sci. Rep. 5 , 18422 (2015).
Article ADS CAS PubMed PubMed Central Google Scholar
Holmes, M. V. et al. Association between alcohol and cardiovascular disease: Mendelian randomisation analysis based on individual participant data. BMJ 349 , g4164 (2014).
Biddinger, K. J. et al. Association of habitual alcohol intake with risk of cardiovascular disease. JAMA Netw. Open 5 , e223849–e223849 (2022).
Zheng, P. et al. The Burden of Proof studies: assessing the evidence of risk. Nat. Med. 28 , 2038–2044 (2022).
Zheng, P., Barber, R., Sorensen, R. J., Murray, C. J. & Aravkin, A. Y. Trimmed constrained mixed effects models: formulations and algorithms. J. Comput. Graph. Stat. 30 , 544–556 (2021).
Article MathSciNet Google Scholar
Egger, M., Smith, G. D., Schneider, M. & Minder, C. Bias in meta-analysis detected by a simple, graphical test. BMJ 315 , 629–634 (1997).
Roerecke, M. & Rehm, J. Alcohol consumption, drinking patterns, and ischemic heart disease: a narrative review of meta-analyses and a systematic review and meta-analysis of the impact of heavy drinking occasions on risk for moderate drinkers. BMC Med. 12 , 182 (2014).
Page, M. J. et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. Syst. Rev. 10 , 89 (2021).
Stevens, G. A. et al. Guidelines for accurate and transparent health estimates reporting: the GATHER statement. PLoS Med. 13 , e1002056 (2016).
Griswold, M. G. et al. Alcohol use and burden for 195 countries and territories, 1990–2016: a systematic analysis for the Global Burden of Disease Study 2016. Lancet 392 , 1015–1035 (2018).
Albert, C. M. et al. Moderate alcohol consumption and the risk of sudden cardiac death among US male physicians. Circulation 100 , 944–950 (1999).
Arriola, L. et al. Alcohol intake and the risk of coronary heart disease in the Spanish EPIC cohort study. Heart 96 , 124–130 (2010).
Bazzano, L. A. et al. Alcohol consumption and risk of coronary heart disease among Chinese men. Int. J. Cardiol. 135 , 78–85 (2009).
Bell, S. et al. Association between clinically recorded alcohol consumption and initial presentation of 12 cardiovascular diseases: population based cohort study using linked health records. BMJ 356 , j909 (2017).
Bergmann, M. M. et al. The association of pattern of lifetime alcohol use and cause of death in the European prospective investigation into cancer and nutrition (EPIC) study. Int. J. Epidemiol. 42 , 1772–1790 (2013).
Beulens, J. W. J. et al. Alcohol consumption and risk for coronary heart disease among men with hypertension. Ann. Intern. Med. 146 , 10–19 (2007).
Bobak, M. et al. Alcohol, drinking pattern and all-cause, cardiovascular and alcohol-related mortality in Eastern Europe. Eur. J. Epidemiol. 31 , 21–30 (2016).
Boffetta, P. & Garfinkel, L. Alcohol drinking and mortality among men enrolled in an American Cancer Society prospective study. Epidemiology 1 , 342–348 (1990).
Britton, A. & Marmot, M. Different measures of alcohol consumption and risk of coronary heart disease and all-cause mortality: 11-year follow-up of the Whitehall II Cohort Study. Addiction 99 , 109–116 (2004).
Camargo, C. A. et al. Moderate alcohol consumption and risk for angina pectoris or myocardial infarction in U.S. male physicians. Ann. Intern. Med. 126 , 372–375 (1997).
Chang, J. Y., Choi, S. & Park, S. M. Association of change in alcohol consumption with cardiovascular disease and mortality among initial nondrinkers. Sci. Rep. 10 , 13419 (2020).
Chiuve, S. E. et al. Light-to-moderate alcohol consumption and risk of sudden cardiac death in women. Heart Rhythm 7 , 1374–1380 (2010).
Colditz, G. A. et al. Moderate alcohol and decreased cardiovascular mortality in an elderly cohort. Am. Heart J. 109 , 886–889 (1985).
Dai, J., Mukamal, K. J., Krasnow, R. E., Swan, G. E. & Reed, T. Higher usual alcohol consumption was associated with a lower 41-y mortality risk from coronary artery disease in men independent of genetic and common environmental factors: the prospective NHLBI Twin Study. Am. J. Clin. Nutr. 102 , 31–39 (2015).
Dam, M. K. et al. Five year change in alcohol intake and risk of breast cancer and coronary heart disease among postmenopausal women: prospective cohort study. BMJ 353 , i2314 (2016).
Degerud, E. et al. Associations of binge drinking with the risks of ischemic heart disease and stroke: a study of pooled Norwegian Health Surveys. Am. J. Epidemiol. 190 , 1592–1603 (2021).
de Labry, L. O. et al. Alcohol consumption and mortality in an American male population: recovering the U-shaped curve–findings from the normative Aging Study. J. Stud. Alcohol 53 , 25–32 (1992).
Doll, R., Peto, R., Boreham, J. & Sutherland, I. Mortality in relation to alcohol consumption: a prospective study among male British doctors. Int. J. Epidemiol. 34 , 199–204 (2005).
Dyer, A. R. et al. Alcohol consumption and 17-year mortality in the Chicago Western Electric Company study. Prev. Med. 9 , 78–90 (1980).
Ebbert, J. O., Janney, C. A., Sellers, T. A., Folsom, A. R. & Cerhan, J. R. The association of alcohol consumption with coronary heart disease mortality and cancer incidence varies by smoking history. J. Gen. Intern. Med. 20 , 14–20 (2005).
Ebrahim, S. et al. Alcohol dehydrogenase type 1 C (ADH1C) variants, alcohol consumption traits, HDL-cholesterol and risk of coronary heart disease in women and men: British Women’s Heart and Health Study and Caerphilly cohorts. Atherosclerosis 196 , 871–878 (2008).
Friedman, L. A. & Kimball, A. W. Coronary heart disease mortality and alcohol consumption in Framingham. Am. J. Epidemiol. 124 , 481–489 (1986).
Fuchs, F. D. et al. Association between alcoholic beverage consumption and incidence of coronary heart disease in whites and blacks: the Atherosclerosis Risk in Communities Study. Am. J. Epidemiol. 160 , 466–474 (2004).
Garfinkel, L., Boffetta, P. & Stellman, S. D. Alcohol and breast cancer: a cohort study. Prev. Med. 17 , 686–693 (1988).
Gémes, K. et al. Alcohol consumption is associated with a lower incidence of acute myocardial infarction: results from a large prospective population-based study in Norway. J. Intern. Med. 279 , 365–375 (2016).
Gigleux, I. et al. Moderate alcohol consumption is more cardioprotective in men with the metabolic syndrome. J. Nutr. 136 , 3027–3032 (2006).
Goldberg, R. J., Burchfiel, C. M., Reed, D. M., Wergowske, G. & Chiu, D. A prospective study of the health effects of alcohol consumption in middle-aged and elderly men. The Honolulu Heart Program. Circulation 89 , 651–659 (1994).
Goldberg, R. J. et al. Lifestyle and biologic factors associated with atherosclerotic disease in middle-aged men. 20-year findings from the Honolulu Heart Program. Arch. Intern. Med. 155 , 686–694 (1995).
Gordon, T. & Doyle, J. T. Drinking and coronary heart disease: the Albany Study. Am. Heart J. 110 , 331–334 (1985).
Gun, R. T., Pratt, N., Ryan, P., Gordon, I. & Roder, D. Tobacco and alcohol-related mortality in men: estimates from the Australian cohort of petroleum industry workers. Aust. N.Z. J. Public Health 30 , 318–324 (2006).
Harriss, L. R. et al. Alcohol consumption and cardiovascular mortality accounting for possible misclassification of intake: 11-year follow-up of the Melbourne Collaborative Cohort Study. Addiction 102 , 1574–1585 (2007).
Hart, C. L. & Smith, G. D. Alcohol consumption and mortality and hospital admissions in men from the Midspan collaborative cohort study. Addiction 103 , 1979–1986 (2008).
Henderson, S. O. et al. Established risk factors account for most of the racial differences in cardiovascular disease mortality. PLoS ONE 2 , e377 (2007).
Hippe, M. et al. Familial predisposition and susceptibility to the effect of other risk factors for myocardial infarction. J. Epidemiol. Community Health 53 , 269–276 (1999).
Ikehara, S. et al. Alcohol consumption and mortality from stroke and coronary heart disease among Japanese men and women: the Japan collaborative cohort study. Stroke 39 , 2936–2942 (2008).
Ikehara, S. et al. Alcohol consumption, social support, and risk of stroke and coronary heart disease among Japanese men: the JPHC Study. Alcohol. Clin. Exp. Res. 33 , 1025–1032 (2009).
Iso, H. et al. Alcohol intake and the risk of cardiovascular disease in middle-aged Japanese men. Stroke 26 , 767–773 (1995).
Jakovljević, B., Stojanov, V., Paunović, K., Belojević, G. & Milić, N. Alcohol consumption and mortality in Serbia: twenty-year follow-up study. Croat. Med. J. 45 , 764–768 (2004).
PubMed Google Scholar
Keil, U., Chambless, L. E., Döring, A., Filipiak, B. & Stieber, J. The relation of alcohol intake to coronary heart disease and all-cause mortality in a beer-drinking population. Epidemiology 8 , 150–156 (1997).
Key, T. J. et al. Mortality in British vegetarians: results from the European Prospective Investigation into Cancer and Nutrition (EPIC-Oxford). Am. J. Clin. Nutr. 89 , 1613S–1619S (2009).
Kitamura, A. et al. Alcohol intake and premature coronary heart disease in urban Japanese men. Am. J. Epidemiol. 147 , 59–65 (1998).
Kivelä, S. L. et al. Alcohol consumption and mortality in aging or aged Finnish men. J. Clin. Epidemiol. 42 , 61–68 (1989).
Klatsky, A. L. et al. Alcohol drinking and risk of hospitalization for heart failure with and without associated coronary artery disease. Am. J. Cardiol. 96 , 346–351 (2005).
Kono, S., Ikeda, M., Tokudome, S., Nishizumi, M. & Kuratsune, M. Alcohol and mortality: a cohort study of male Japanese physicians. Int. J. Epidemiol. 15 , 527–532 (1986).
Kunutsor, S. K. et al. Self-reported alcohol consumption, carbohydrate deficient transferrin and risk of cardiovascular disease: the PREVEND prospective cohort study. Clin. Chim. Acta 520 , 1–7 (2021).
Kurl, S., Jae, S. Y., Voutilainen, A. & Laukkanen, J. A. The combined effect of blood pressure and C-reactive protein with the risk of mortality from coronary heart and cardiovascular diseases. Nutr. Metab. Cardiovasc. Dis. 31 , 2051–2057 (2021).
Larsson, S. C., Wallin, A. & Wolk, A. Contrasting association between alcohol consumption and risk of myocardial infarction and heart failure: two prospective cohorts. Int. J. Cardiol. 231 , 207–210 (2017).
Lazarus, N. B., Kaplan, G. A., Cohen, R. D. & Leu, D. J. Change in alcohol consumption and risk of death from all causes and from ischaemic heart disease. BMJ 303 , 553–556 (1991).
Lee, D.-H., Folsom, A. R. & Jacobs, D. R. Dietary iron intake and Type 2 diabetes incidence in postmenopausal women: the Iowa Women’s Health Study. Diabetologia 47 , 185–194 (2004).
Liao, Y., McGee, D. L., Cao, G. & Cooper, R. S. Alcohol intake and mortality: findings from the National Health Interview Surveys (1988 and 1990). Am. J. Epidemiol. 151 , 651–659 (2000).
Licaj, I. et al. Alcohol consumption over time and mortality in the Swedish Women’s Lifestyle and Health cohort. BMJ Open 6 , e012862 (2016).
Lindschou Hansen, J. et al. Alcohol intake and risk of acute coronary syndrome and mortality in men and women with and without hypertension. Eur. J. Epidemiol. 26 , 439–447 (2011).
Makelä, P., Paljärvi, T. & Poikolainen, K. Heavy and nonheavy drinking occasions, all-cause and cardiovascular mortality and hospitalizations: a follow-up study in a population with a low consumption level. J. Stud. Alcohol 66 , 722–728 (2005).
Malyutina, S. et al. Relation between heavy and binge drinking and all-cause and cardiovascular mortality in Novosibirsk, Russia: a prospective cohort study. Lancet 360 , 1448–1454 (2002).
Maraldi, C. et al. Impact of inflammation on the relationship among alcohol consumption, mortality, and cardiac events: the health, aging, and body composition study. Arch. Intern. Med. 166 , 1490–1497 (2006).
Marques-Vidal, P. et al. Alcohol consumption and cardiovascular disease: differential effects in France and Northern Ireland. The PRIME study. Eur. J. Cardiovasc. Prev. Rehabil. 11 , 336–343 (2004).
Meisinger, C., Döring, A., Schneider, A., Löwel, H. & KORA Study Group. Serum gamma-glutamyltransferase is a predictor of incident coronary events in apparently healthy men from the general population. Atherosclerosis 189 , 297–302 (2006).
Merry, A. H. H. et al. Smoking, alcohol consumption, physical activity, and family history and the risks of acute myocardial infarction and unstable angina pectoris: a prospective cohort study. BMC Cardiovasc. Disord. 11 , 13 (2011).
Miller, G. J., Beckles, G. L., Maude, G. H. & Carson, D. C. Alcohol consumption: protection against coronary heart disease and risks to health. Int. J. Epidemiol. 19 , 923–930 (1990).
Mukamal, K. J., Chiuve, S. E. & Rimm, E. B. Alcohol consumption and risk for coronary heart disease in men with healthy lifestyles. Arch. Intern. Med. 166 , 2145–2150 (2006).
Ng, R., Sutradhar, R., Yao, Z., Wodchis, W. P. & Rosella, L. C. Smoking, drinking, diet and physical activity-modifiable lifestyle risk factors and their associations with age to first chronic disease. Int. J. Epidemiol. 49 , 113–130 (2020).
Onat, A. et al. Moderate and heavy alcohol consumption among Turks: long-term impact on mortality and cardiometabolic risk. Arch. Turkish Soc. Cardiol. 37 , 83–90 (2009).
Google Scholar
Pedersen, J. Ø., Heitmann, B. L., Schnohr, P. & Grønbaek, M. The combined influence of leisure-time physical activity and weekly alcohol intake on fatal ischaemic heart disease and all-cause mortality. Eur. Heart J. 29 , 204–212 (2008).
Reddiess, P. et al. Alcohol consumption and risk of cardiovascular outcomes and bleeding in patients with established atrial fibrillation. Can. Med. Assoc. J. 193 , E117–E123 (2021).
Article CAS Google Scholar
Rehm, J. T., Bondy, S. J., Sempos, C. T. & Vuong, C. V. Alcohol consumption and coronary heart disease morbidity and mortality. Am. J. Epidemiol. 146 , 495–501 (1997).
Renaud, S. C., Guéguen, R., Schenker, J. & d’Houtaud, A. Alcohol and mortality in middle-aged men from eastern France. Epidemiology 9 , 184–188 (1998).
Ricci, C. et al. Alcohol intake in relation to non-fatal and fatal coronary heart disease and stroke: EPIC-CVD case-cohort study. BMJ 361 , k934 (2018).
Rimm, E. B. et al. Prospective study of alcohol consumption and risk of coronary disease in men. Lancet 338 , 464–468 (1991).
Roerecke, M. et al. Heavy drinking occasions in relation to ischaemic heart disease mortality– an 11-22 year follow-up of the 1984 and 1995 US National Alcohol Surveys. Int. J. Epidemiol. 40 , 1401–1410 (2011).
Romelsjö, A., Allebeck, P., Andréasson, S. & Leifman, A. Alcohol, mortality and cardiovascular events in a 35 year follow-up of a nationwide representative cohort of 50,000 Swedish conscripts up to age 55. Alcohol Alcohol. 47 , 322–327 (2012).
Rostron, B. Alcohol consumption and mortality risks in the USA. Alcohol Alcohol. 47 , 334–339 (2012).
Ruidavets, J.-B. et al. Patterns of alcohol consumption and ischaemic heart disease in culturally divergent countries: the Prospective Epidemiological Study of Myocardial Infarction (PRIME). BMJ 341 , c6077 (2010).
Schooling, C. M. et al. Moderate alcohol use and mortality from ischaemic heart disease: a prospective study in older Chinese people. PLoS ONE 3 , e2370 (2008).
Schutte, R., Smith, L. & Wannamethee, G. Alcohol - The myth of cardiovascular protection. Clin. Nutr. 41 , 348–355 (2022).
Sempos, C., Rehm, J., Crespo, C. & Trevisan, M. No protective effect of alcohol consumption on coronary heart disease (CHD) in African Americans: average volume of drinking over the life course and CHD morbidity and mortality in a U.S. national cohort. Contemp. Drug Probl. 29 , 805–820 (2002).
Shaper, A. G., Wannamethee, G. & Walker, M. Alcohol and coronary heart disease: a perspective from the British Regional Heart Study. Int. J. Epidemiol. 23 , 482–494 (1994).
Simons, L. A., McCallum, J., Friedlander, Y. & Simons, J. Alcohol intake and survival in the elderly: a 77 month follow-up in the Dubbo study. Aust. N.Z. J. Med. 26 , 662–670 (1996).
Skov-Ettrup, L. S., Eliasen, M., Ekholm, O., Grønbæk, M. & Tolstrup, J. S. Binge drinking, drinking frequency, and risk of ischaemic heart disease: a population-based cohort study. Scand. J. Public Health 39 , 880–887 (2011).
Snow, W. M., Murray, R., Ekuma, O., Tyas, S. L. & Barnes, G. E. Alcohol use and cardiovascular health outcomes: a comparison across age and gender in the Winnipeg Health and Drinking Survey Cohort. Age Ageing 38 , 206–212 (2009).
Song, R. J. et al. Alcohol consumption and risk of coronary artery disease (from the Million Veteran Program). Am. J. Cardiol. 121 , 1162–1168 (2018).
Streppel, M. T., Ocké, M. C., Boshuizen, H. C., Kok, F. J. & Kromhout, D. Long-term wine consumption is related to cardiovascular mortality and life expectancy independently of moderate alcohol intake: the Zutphen Study. J. Epidemiol. Community Health 63 , 534–540 (2009).
Suhonen, O., Aromaa, A., Reunanen, A. & Knekt, P. Alcohol consumption and sudden coronary death in middle-aged Finnish men. Acta Med. Scand. 221 , 335–341 (1987).
Thun, M. J. et al. Alcohol consumption and mortality among middle-aged and elderly U.S. adults. N. Engl. J. Med. 337 , 1705–1714 (1997).
Tolstrup, J. et al. Prospective study of alcohol drinking patterns and coronary heart disease in women and men. BMJ 332 , 1244–1248 (2006).
Wannamethee, G. & Shaper, A. G. Alcohol and sudden cardiac death. Br. Heart J. 68 , 443–448 (1992).
Wannamethee, S. G. & Shaper, A. G. Type of alcoholic drink and risk of major coronary heart disease events and all-cause mortality. Am. J. Public Health 89 , 685–690 (1999).
Wilkins, K. Moderate alcohol consumption and heart disease. Health Rep. 14 , 9–24 (2002).
Yang, L. et al. Alcohol drinking and overall and cause-specific mortality in China: nationally representative prospective study of 220,000 men with 15 years of follow-up. Int. J. Epidemiol. 41 , 1101–1113 (2012).
Yi, S. W., Yoo, S. H., Sull, J. W. & Ohrr, H. Association between alcohol drinking and cardiovascular disease mortality and all-cause mortality: Kangwha Cohort Study. J. Prev. Med. Public Health 37 , 120–126 (2004).
Younis, J., Cooper, J. A., Miller, G. J., Humphries, S. E. & Talmud, P. J. Genetic variation in alcohol dehydrogenase 1C and the beneficial effect of alcohol intake on coronary heart disease risk in the Second Northwick Park Heart Study. Atherosclerosis 180 , 225–232 (2005).
Yusuf, S. et al. Modifiable risk factors, cardiovascular disease, and mortality in 155 722 individuals from 21 high-income, middle-income, and low-income countries (PURE): a prospective cohort study. Lancet 395 , 795–808 (2020).
Zhang, Y. et al. Association of drinking pattern with risk of coronary heart disease incidence in the middle-aged and older Chinese men: results from the Dongfeng-Tongji cohort. PLoS ONE 12 , e0178070 (2017).
Augustin, L. S. A. et al. Alcohol consumption and acute myocardial infarction: a benefit of alcohol consumed with meals? Epidemiology 15 , 767–769 (2004).
Bianchi, C., Negri, E., La Vecchia, C. & Franceschi, S. Alcohol consumption and the risk of acute myocardial infarction in women. J. Epidemiol. Community Health 47 , 308–311 (1993).
Brenner, H. et al. Coronary heart disease risk reduction in a predominantly beer-drinking population. Epidemiology 12 , 390–395 (2001).
Dorn, J. M. et al. Alcohol drinking pattern and non-fatal myocardial infarction in women. Addiction 102 , 730–739 (2007).
Fan, A. Z., Ruan, W. J. & Chou, S. P. Re-examining the relationship between alcohol consumption and coronary heart disease with a new lens. Prev. Med. 118 , 336–343 (2019).
Fumeron, F. et al. Alcohol intake modulates the effect of a polymorphism of the cholesteryl ester transfer protein gene on plasma high density lipoprotein and the risk of myocardial infarction. J. Clin. Investig. 96 , 1664–1671 (1995).
Gaziano, J. M. et al. Moderate alcohol intake, increased levels of high-density lipoprotein and its subfractions, and decreased risk of myocardial infarction. N. Engl. J. Med. 329 , 1829–1834 (1993).
Genchev, G. D., Georgieva, L. M., Weijenberg, M. P. & Powles, J. W. Does alcohol protect against ischaemic heart disease in Bulgaria? A case-control study of non-fatal myocardial infarction in Sofia. Cent. Eur. J. Public Health 9 , 83–86 (2001).
CAS PubMed Google Scholar
Hammar, N., Romelsjö, A. & Alfredsson, L. Alcohol consumption, drinking pattern and acute myocardial infarction. A case referent study based on the Swedish Twin Register. J. Intern. Med. 241 , 125–131 (1997).
Hines, L. M. et al. Genetic variation in alcohol dehydrogenase and the beneficial effect of moderate alcohol consumption on myocardial infarction. N. Engl. J. Med. 344 , 549–555 (2001).
Ilic, M., Grujicic Sipetic, S., Ristic, B. & Ilic, I. Myocardial infarction and alcohol consumption: a case-control study. PLoS ONE 13 , e0198129 (2018).
Jackson, R., Scragg, R. & Beaglehole, R. Alcohol consumption and risk of coronary heart disease. BMJ 303 , 211–216 (1991).
Kabagambe, E. K., Baylin, A., Ruiz-Narvaez, E., Rimm, E. B. & Campos, H. Alcohol intake, drinking patterns, and risk of nonfatal acute myocardial infarction in Costa Rica. Am. J. Clin. Nutr. 82 , 1336–1345 (2005).
Kalandidi, A. et al. A case-control study of coronary heart disease in Athens, Greece. Int. J. Epidemiol. 21 , 1074–1080 (1992).
Kaufman, D. W., Rosenberg, L., Helmrich, S. P. & Shapiro, S. Alcoholic beverages and myocardial infarction in young men. Am. J. Epidemiol. 121 , 548–554 (1985).
Kawanishi, M., Nakamoto, A., Konemori, G., Horiuchi, I. & Kajiyama, G. Coronary sclerosis risk factors in males with special reference to lipoproteins and apoproteins: establishing an index. Hiroshima J. Med. Sci. 39 , 61–64 (1990).
Kono, S. et al. Alcohol intake and nonfatal acute myocardial infarction in Japan. Am. J. Cardiol. 68 , 1011–1014 (1991).
Mehlig, K. et al. CETP TaqIB genotype modifies the association between alcohol and coronary heart disease: the INTERGENE case-control study. Alcohol 48 , 695–700 (2014).
Miyake, Y. Risk factors for non-fatal acute myocardial infarction in middle-aged and older Japanese. Fukuoka Heart Study Group. Jpn. Circ. J. 64 , 103–109 (2000).
Oliveira, A., Barros, H., Azevedo, A., Bastos, J. & Lopes, C. Impact of risk factors for non-fatal acute myocardial infarction. Eur. J. Epidemiol. 24 , 425–432 (2009).
Oliveira, A., Barros, H. & Lopes, C. Gender heterogeneity in the association between lifestyles and non-fatal acute myocardial infarction. Public Health Nutr. 12 , 1799–1806 (2009).
Romelsjö, A. et al. Abstention, alcohol use and risk of myocardial infarction in men and women taking account of social support and working conditions: the SHEEP case-control study. Addiction 98 , 1453–1462 (2003).
Schröder, H. et al. Myocardial infarction and alcohol consumption: a population-based case-control study. Nutr. Metab. Cardiovasc. Dis. 17 , 609–615 (2007).
Scragg, R., Stewart, A., Jackson, R. & Beaglehole, R. Alcohol and exercise in myocardial infarction and sudden coronary death in men and women. Am. J. Epidemiol. 126 , 77–85 (1987).
Tavani, A., Bertuzzi, M., Gallus, S., Negri, E. & La Vecchia, C. Risk factors for non-fatal acute myocardial infarction in Italian women. Prev. Med. 39 , 128–134 (2004).
Tavani, A. et al. Intake of specific flavonoids and risk of acute myocardial infarction in Italy. Public Health Nutr. 9 , 369–374 (2006).
Zhou, X., Li, C., Xu, W., Hong, X. & Chen, J. Relation of alcohol consumption to angiographically proved coronary artery disease in chinese men. Am. J. Cardiol. 106 , 1101–1103 (2010).
Yang, Y. et al. Alcohol consumption and risk of coronary artery disease: a dose-response meta-analysis of prospective studies. Nutrition 32 , 637–644 (2016).
Zheng, J. et al. Recent developments in Mendelian randomization studies. Curr. Epidemiol. Rep. 4 , 330–345 (2017).
Mukamal, K. J., Stampfer, M. J. & Rimm, E. B. Genetic instrumental variable analysis: time to call Mendelian randomization what it is. The example of alcohol and cardiovascular disease. Eur. J. Epidemiol. 35 , 93–97 (2020).
Verbanck, M., Chen, C.-Y., Neale, B. & Do, R. Detection of widespread horizontal pleiotropy in causal relationships inferred from Mendelian randomization between complex traits and diseases. Nat. Genet. 50 , 693–698 (2018).
Shi, J. et al. Mendelian randomization with repeated measures of a time-varying exposure: an application of structural mean models. Epidemiology 33 , 84–94 (2022).
Burgess, S., Swanson, S. A. & Labrecque, J. A. Are Mendelian randomization investigations immune from bias due to reverse causation? Eur. J. Epidemiol. 36 , 253–257 (2021).
Davey Smith, G., Holmes, M. V., Davies, N. M. & Ebrahim, S. Mendel’s laws, Mendelian randomization and causal inference in observational data: substantive and nomenclatural issues. Eur. J. Epidemiol. 35 , 99–111 (2020).
Burgess, S. Violation of the constant genetic effect assumption can result in biased estimates for non-linear mendelian randomization. Hum. Hered. 88 , 79–90 (2023).
Tian, H., Mason, A. M., Liu, C. & Burgess, S. Relaxing parametric assumptions for non-linear Mendelian randomization using a doubly-ranked stratification method. PLoS Genet. 19 , e1010823 (2023).
Levin, M. G. & Burgess, S. Mendelian randomization as a tool for cardiovascular research: a review. JAMA Cardiol. 9 , 79–89 (2024).
Burgess, S. et al. Guidelines for performing Mendelian randomization investigations: update for summer 2023. Wellcome Open Res. 4 , 186 (2019).
Bowden, J., Davey Smith, G., Haycock, P. C. & Burgess, S. Consistent estimation in Mendelian randomization with some invalid instruments using a weighted median estimator. Genet. Epidemiol. 40 , 304–314 (2016).
Holmes, M. V., Ala-Korpela, M. & Smith, G. D. Mendelian randomization in cardiometabolic disease: challenges in evaluating causality. Nat. Rev. Cardiol. 14 , 577–590 (2017).
Labrecque, J. A. & Swanson, S. A. Interpretation and potential biases of Mendelian randomization estimates with time-varying exposures. Am. J. Epidemiol. 188 , 231–238 (2019).
Spiegelman, D. et al. The Moderate Alcohol and Cardiovascular Health Trial (MACH15): design and methods for a randomized trial of moderate alcohol consumption and cardiometabolic risk. Eur. J. Prev. Cardiol. 27 , 1967–1982 (2020).
DeJong, W. The Moderate Alcohol and Cardiovascular Health Trial: public health advocates should support good science, not undermine it. Eur. J. Prev. Cardiol. 28 , e22–e24 (2021).
National Institutes of Health. NIH to End Funding for Moderate Alcohol and Cardiovascular Health Trial https://www.nih.gov/news-events/news-releases/nih-end-funding-moderate-alcohol-cardiovascular-health-trial (2018).
Miller, L. M., Anderson, C. A. M. & Ix, J. H. Editorial: from MACH15 to MACH0 – a missed opportunity to understand the health effects of moderate alcohol intake. Eur. J. Prev. Cardiol. 28 , e23–e24 (2021).
Anderson, B. O. et al. Health and cancer risks associated with low levels of alcohol consumption. Lancet Public Health 8 , e6–e7 (2023).
Au Yeung, S. L. & Lam, T. H. Unite for a framework convention for alcohol control. Lancet 393 , 1778–1779 (2019).
Hernán, M. A. & Robins, J. M. Using big data to emulate a target trial when a randomized trial is not available. Am. J. Epidemiol. 183 , 758–764 (2016).
Sudlow, C. et al. UK biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS Med. 12 , e1001779 (2015).
The ARIC Investigators. The Atherosclerosis Risk in Communit (ARIC) study: design and objectives. Am. J. Epidemiol. 129 , 687–702 (1989).
Mahmood, S. S., Levy, D., Vasan, R. S. & Wang, T. J. The Framingham Heart Study and the epidemiology of cardiovascular disease: a historical perspective. Lancet 383 , 999–1008 (2014).
Gmel, G. & Rehm, J. Measuring alcohol consumption. Contemp. Drug Probl. 31 , 467–540 (2004).
Guyatt, G. H. et al. GRADE: an emerging consensus on rating quality of evidence and strength of recommendations. BMJ 336 , 924–926 (2008).
Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 58 , 267–288 (1996).
Biggerstaff, B. J. & Tweedie, R. L. Incorporating variability in estimates of heterogeneity in the random effects model in meta‐analysis. Stat. Med. 16 , 753–768 (1997).
Download references
Acknowledgements
Research reported in this publication was supported by the Bill & Melinda Gates Foundation [OPP1152504]. S.L. has received grants or contracts from the UK Medical Research Council [MR/T017708/1], CDC Foundation [project number 996], World Health Organization [APW No 2021/1194512], and is affiliated with the NIHR Oxford Biomedical Research Centre. The University of Oxford’s Clinical Trial Service Unit and Epidemiological Studies Unit (CTSU) is supported by core grants from the Medical Research Council [Clinical Trial Service Unit A310] and the British Heart Foundation [CH/1996001/9454]. The CTSU receives research grants from industry that are governed by University of Oxford contracts that protect its independence and has a staff policy of not taking personal payments from industry. The content is solely the responsibility of the authors and does not necessarily represent the official views of the funders. The funders of the study had no role in study design, data collection, data analysis, data interpretation, writing of the final report, or the decision to publish.
Author information
Authors and affiliations.
Institute for Health Metrics and Evaluation, University of Washington, Seattle, WA, USA
Sinclair Carr, Dana Bryazka, Susan A. McLaughlin, Peng Zheng, Aleksandr Y. Aravkin, Simon I. Hay, Hilary R. Lawlor, Erin C. Mullany, Christopher J. L. Murray, Sneha I. Nicholson, Gregory A. Roth, Reed J. D. Sorensen & Emmanuela Gakidou
Department of Health Metrics Sciences, School of Medicine, University of Washington, Seattle, WA, USA
Peng Zheng, Aleksandr Y. Aravkin, Simon I. Hay, Christopher J. L. Murray, Gregory A. Roth & Emmanuela Gakidou
Clinical Trial Service Unit & Epidemiological Studies Unit, Nuffield Department of Population Health, University of Oxford, Oxford, Oxfordshire, UK
Sarasvati Bahadursingh & Sarah Lewington
Department of Applied Mathematics, University of Washington, Seattle, WA, USA
Aleksandr Y. Aravkin
Institute for Mental Health Policy Research, Centre for Addiction and Mental Health, Toronto, ON, Canada
Jürgen Rehm
Campbell Family Mental Health Research Institute, Centre for Addiction and Mental Health, Toronto, ON, Canada
Dalla Lana School of Public Health, University of Toronto, Toronto, ON, Canada
Department of Psychiatry, University of Toronto, Toronto, ON, Canada
Faculty of Medicine, Institute of Medical Science (IMS), University of Toronto, Toronto, ON, Canada
World Health Organization / Pan American Health Organization Collaborating Centre, Centre for Addiction and Mental Health, Toronto, ON, Canada
Center for Interdisciplinary Addiction Research (ZIS), Department of Psychiatry and Psychotherapy, University Medical Center Hamburg-Eppendorf (UKE), Hamburg, Germany
Institute of Clinical Psychology and Psychotherapy, Technische Universität Dresden, Dresden, Germany
Division of Cardiology, Department of Medicine, University of Washington, Seattle, WA, USA
Gregory A. Roth
You can also search for this author in PubMed Google Scholar
Contributions
S.C., S.A.M., S.I.H., and E.C.M. managed the estimation or publications process. S.C. wrote the first draft of the manuscript. S.C. had primary responsibility for applying analytical methods to produce estimates. S.C. and H.R.L. had primary responsibility for seeking, cataloging, extracting, or cleaning data; designing or coding figures and tables. S.C., D.B., S.B., E.C.M., S.I.N., J.R., and R.J.D.S. provided data or critical feedback on data sources. S.C., D.B., P.Z., A.Y.A., S.I.N., and R.J.D.S. developed methods or computational machinery. S.C., D.B., P.Z., S.B., S.I.H., E.C.M., C.J.L.M., S.I.N., J.R., R.J.D.S., S.L., and E.G. provided critical feedback on methods or results. S.C., D.B., S.A.M., S.B., S.I.H., C.J.L.M., J.R., G.A.R., S.L., and E.G. drafted the work or revised it critically for important intellectual content. S.C., S.I.H., E.C.M., and E.G. managed the overall research enterprise.
Corresponding author
Correspondence to Sinclair Carr .
Ethics declarations
Competing interests.
G.A.R. has received support for this manuscript from the Bill and Melinda Gates Foundation [OPP1152504]. S.L. has received grants or contracts from the UK Medical Research Council [MR/T017708/1], CDC Foundation [project number 996], World Health Organization [APW No 2021/1194512], and is affiliated with the NIHR Oxford Biomedical Research Centre. The University of Oxford’s Clinical Trial Service Unit and Epidemiological Studies Unit (CTSU) is supported by core grants from the Medical Research Council [Clinical Trial Service Unit A310] and the British Heart Foundation [CH/1996001/9454]. The CTSU receives research grants from industry that are governed by University of Oxford contracts that protect its independence and has a staff policy of not taking personal payments from industry. All other authors declare no competing interests.
Peer review
Peer review information.
Nature Communications thanks Shiu Lun Au Yeung, and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary information, peer review file, reporting summary, source data, source data, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Carr, S., Bryazka, D., McLaughlin, S.A. et al. A burden of proof study on alcohol consumption and ischemic heart disease. Nat Commun 15 , 4082 (2024). https://doi.org/10.1038/s41467-024-47632-7
Download citation
Received : 14 June 2023
Accepted : 08 April 2024
Published : 14 May 2024
DOI : https://doi.org/10.1038/s41467-024-47632-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

IMAGES
VIDEO
COMMENTS
Case study examples. While templates are helpful, seeing a case study in action can also be a great way to learn. Here are some examples of how Adobe customers have experienced success. Juniper Networks. One example is the Adobe and Juniper Networks case study, which puts the reader in the customer's shoes.
Case study examples. Case studies are proven marketing strategies in a wide variety of B2B industries. Here are just a few examples of a case study: Amazon Web Services, Inc. provides companies with cloud computing platforms and APIs on a metered, pay-as-you-go basis. This case study example illustrates the benefits Thomson Reuters experienced ...
2. Determine the case study's objective. All business case studies are designed to demonstrate the value of your services, but they can focus on several different client objectives. Your first step when writing a case study is to determine the objective or goal of the subject you're featuring.
To save you time and effort, I have curated a list of 5 versatile case study presentation templates, each designed for specific needs and audiences. Here are some best case study presentation examples that showcase effective strategies for engaging your audience and conveying complex information clearly. 1. Lab report case study template.
A case study is a detailed analysis of a specific topic in a real-world context. It can pertain to a person, place, event, group, or phenomenon, among others. The purpose is to derive generalizations about the topic, as well as other insights. Case studies find application in academic, business, political, or scientific research.
A case study protocol outlines the procedures and general rules to be followed during the case study. This includes the data collection methods to be used, the sources of data, and the procedures for analysis. Having a detailed case study protocol ensures consistency and reliability in the study.
The above information should nicely fit in several paragraphs or 2-3 case study template slides. 2. Explain the Solution. The bulk of your case study copy and presentation slides should focus on the provided solution (s). This is the time to speak at length about how the subject went from before to the glorious after.
The five case studies listed below are well-written, well-designed, and incorporate a time-tested structure. 1. Lane Terralever and Pinnacle at Promontory. This case study example from Lane Terralever incorporates images to support the content and effectively uses subheadings to make the piece scannable. 2.
Revised on November 20, 2023. A case study is a detailed study of a specific subject, such as a person, group, place, event, organization, or phenomenon. Case studies are commonly used in social, educational, clinical, and business research. A case study research design usually involves qualitative methods, but quantitative methods are ...
Marketers use case studies to tell a story about a customer's journey or how a product or service solves a specific issue. Case studies can be used in all levels of business and in many industries. A thorough case study often uses metrics, such as key performance indicators, to show growth and success that supports the product or service.
Case studies tend to focus on qualitative data using methods such as interviews, observations, and analysis of primary and secondary sources (e.g., newspaper articles, photographs, official records). Sometimes a case study will also collect quantitative data. Example: Mixed methods case study. For a case study of a wind farm development in a ...
The purpose of a paper in the social sciences designed around a case study is to thoroughly investigate a subject of analysis in order to reveal a new understanding about the research problem and, in so doing, contributing new knowledge to what is already known from previous studies. In applied social sciences disciplines [e.g., education, social work, public administration, etc.], case ...
4 best format types for a business case study presentation: Problem-solution case study. Before-and-after case study. Success story case study. Interview style case study. Each style has unique strengths, so pick one that aligns best with your story and audience. For a deeper dive into these formats, check out our detailed blog post on case ...
1. Make it as easy as possible for the client. Just like when asking for reviews, it's important to make the process as clear and easy as possible for the client. When you reach out, ask if you can use their story of achievement as a case study for your business. Make the details as clear as possible, including:
A case study's outcome is typically to share the story of a company's growth or highlight the increase of metrics the company tracks to understand success. The case study includes an analysis of a campaign or project that goes through a few steps from identifying the problem to how you implemented the solution. How to Write a Case Study
15 Real-Life Case Study Examples. Now that you understand what a case study is, let's look at real-life case study examples. In this section, we'll explore SaaS, marketing, sales, product and business case study examples with solutions. Take note of how these companies structured their case studies and included the key elements.
Although case studies have been discussed extensively in the literature, little has been written about the specific steps one may use to conduct case study research effectively (Gagnon, 2010; Hancock & Algozzine, 2016).Baskarada (2014) also emphasized the need to have a succinct guideline that can be practically followed as it is actually tough to execute a case study well in practice.
In the marketing case study examples below, a variety of designs and techniques to create impactful and effective case studies. Show off impressive results with a bold marketing case study. Case studies are meant to show off your successes, so make sure you feature your positive results prominently. Using bold and bright colors as well as ...
A case study is an in-depth study of one person, group, or event. In a case study, nearly every aspect of the subject's life and history is analyzed to seek patterns and causes of behavior. Case studies can be used in many different fields, including psychology, medicine, education, anthropology, political science, and social work.
Add your case study to your list of publications on LinkedIn. Share your case studies in relevant LinkedIn Groups. Target your new case studies to relevant people on Facebook using dark posts. (Learn about dark posts here.) Get Inspired: MaRS Discovery District posts case studies on Twitter to push people towards a desired action. 9.
Identify the key problems and issues in the case study. Formulate and include a thesis statement, summarizing the outcome of your analysis in 1-2 sentences. Background. Set the scene: background information, relevant facts, and the most important issues. Demonstrate that you have researched the problems in this case study. Evaluation of the Case
Case studies can help others (e.g., students, other organizations, employees) learn about • new concepts, • best practices, and • situations they might face. Writing a case study also allows you to critically examine your organizational practices. Examples The following pages provide examples of different types of case study formats. ...
Case studies can help lawyers, policymakers, and ethical professionals to develop critical thinking skills, analyze complex cases, and make informed decisions. Purpose of Case Study. The purpose of a case study is to provide a detailed analysis of a specific phenomenon, issue, or problem in its real-life context. A case study is a qualitative ...
With the advent of Industry 4.0, Artificial Intelligence (AI) has created a favorable environment for the digitalization of manufacturing and processing, helping industries to automate and optimize operations. In this work, we focus on a practical case study of a brake caliper quality control operation, which is usually accomplished by human inspection and requires a dedicated handling system ...
NEW YORK -- For a last hurrah, it was a Sage decision. A miniature poodle named Sage won the top prize Tuesday night at the Westminster Kennel Club dog show, in what veteran handler Kaz Hosaka ...
In each instance, the threat actor on the phone to a targeted user pulls their initial malicious payload from one of the above domains. Malicious payloads are typically contained within an archive file named s.zip—we observed this filename in Case Study 2 below. The contents of these archive files have changed throughout the attack campaign:
A case study in what happens when franchising goes wrong Laser Clinics first opened in Australia in 2008 as a franchise network set up by former actuary Babak Moini and legal IT expert Alistair ...
Risk curve derived from case-control study data. Next, we estimated the mean risk curve and 95% UI for the relationship between alcohol consumption and IHD by subsetting the data to case-control ...
Ozempic's maker, Novo Nordisk, said it intends to study the phenomenon, although cutting the drinking isn't the study's main goal. The company plans to start assessing the effects of ...
We showcase the effectiveness of the proposed approach by rigorously comparing its capabilities to those of an ARIMA model, utilizing one underperforming PBHM as a case study. Additionally, we test whether the LSTM benefits from the PBHM's results or if a similar accuracy can be reached by employing a standalone LSTM.