
An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- HCA Healthc J Med
- v.1(2); 2020
- PMC10324782

Introduction to Research Statistical Analysis: An Overview of the Basics
Christian vandever.
1 HCA Healthcare Graduate Medical Education
Description
This article covers many statistical ideas essential to research statistical analysis. Sample size is explained through the concepts of statistical significance level and power. Variable types and definitions are included to clarify necessities for how the analysis will be interpreted. Categorical and quantitative variable types are defined, as well as response and predictor variables. Statistical tests described include t-tests, ANOVA and chi-square tests. Multiple regression is also explored for both logistic and linear regression. Finally, the most common statistics produced by these methods are explored.
Introduction
Statistical analysis is necessary for any research project seeking to make quantitative conclusions. The following is a primer for research-based statistical analysis. It is intended to be a high-level overview of appropriate statistical testing, while not diving too deep into any specific methodology. Some of the information is more applicable to retrospective projects, where analysis is performed on data that has already been collected, but most of it will be suitable to any type of research. This primer will help the reader understand research results in coordination with a statistician, not to perform the actual analysis. Analysis is commonly performed using statistical programming software such as R, SAS or SPSS. These allow for analysis to be replicated while minimizing the risk for an error. Resources are listed later for those working on analysis without a statistician.
After coming up with a hypothesis for a study, including any variables to be used, one of the first steps is to think about the patient population to apply the question. Results are only relevant to the population that the underlying data represents. Since it is impractical to include everyone with a certain condition, a subset of the population of interest should be taken. This subset should be large enough to have power, which means there is enough data to deliver significant results and accurately reflect the study’s population.
The first statistics of interest are related to significance level and power, alpha and beta. Alpha (α) is the significance level and probability of a type I error, the rejection of the null hypothesis when it is true. The null hypothesis is generally that there is no difference between the groups compared. A type I error is also known as a false positive. An example would be an analysis that finds one medication statistically better than another, when in reality there is no difference in efficacy between the two. Beta (β) is the probability of a type II error, the failure to reject the null hypothesis when it is actually false. A type II error is also known as a false negative. This occurs when the analysis finds there is no difference in two medications when in reality one works better than the other. Power is defined as 1-β and should be calculated prior to running any sort of statistical testing. Ideally, alpha should be as small as possible while power should be as large as possible. Power generally increases with a larger sample size, but so does cost and the effect of any bias in the study design. Additionally, as the sample size gets bigger, the chance for a statistically significant result goes up even though these results can be small differences that do not matter practically. Power calculators include the magnitude of the effect in order to combat the potential for exaggeration and only give significant results that have an actual impact. The calculators take inputs like the mean, effect size and desired power, and output the required minimum sample size for analysis. Effect size is calculated using statistical information on the variables of interest. If that information is not available, most tests have commonly used values for small, medium or large effect sizes.
When the desired patient population is decided, the next step is to define the variables previously chosen to be included. Variables come in different types that determine which statistical methods are appropriate and useful. One way variables can be split is into categorical and quantitative variables. ( Table 1 ) Categorical variables place patients into groups, such as gender, race and smoking status. Quantitative variables measure or count some quantity of interest. Common quantitative variables in research include age and weight. An important note is that there can often be a choice for whether to treat a variable as quantitative or categorical. For example, in a study looking at body mass index (BMI), BMI could be defined as a quantitative variable or as a categorical variable, with each patient’s BMI listed as a category (underweight, normal, overweight, and obese) rather than the discrete value. The decision whether a variable is quantitative or categorical will affect what conclusions can be made when interpreting results from statistical tests. Keep in mind that since quantitative variables are treated on a continuous scale it would be inappropriate to transform a variable like which medication was given into a quantitative variable with values 1, 2 and 3.
Categorical vs. Quantitative Variables
Both of these types of variables can also be split into response and predictor variables. ( Table 2 ) Predictor variables are explanatory, or independent, variables that help explain changes in a response variable. Conversely, response variables are outcome, or dependent, variables whose changes can be partially explained by the predictor variables.
Response vs. Predictor Variables
Choosing the correct statistical test depends on the types of variables defined and the question being answered. The appropriate test is determined by the variables being compared. Some common statistical tests include t-tests, ANOVA and chi-square tests.
T-tests compare whether there are differences in a quantitative variable between two values of a categorical variable. For example, a t-test could be useful to compare the length of stay for knee replacement surgery patients between those that took apixaban and those that took rivaroxaban. A t-test could examine whether there is a statistically significant difference in the length of stay between the two groups. The t-test will output a p-value, a number between zero and one, which represents the probability that the two groups could be as different as they are in the data, if they were actually the same. A value closer to zero suggests that the difference, in this case for length of stay, is more statistically significant than a number closer to one. Prior to collecting the data, set a significance level, the previously defined alpha. Alpha is typically set at 0.05, but is commonly reduced in order to limit the chance of a type I error, or false positive. Going back to the example above, if alpha is set at 0.05 and the analysis gives a p-value of 0.039, then a statistically significant difference in length of stay is observed between apixaban and rivaroxaban patients. If the analysis gives a p-value of 0.91, then there was no statistical evidence of a difference in length of stay between the two medications. Other statistical summaries or methods examine how big of a difference that might be. These other summaries are known as post-hoc analysis since they are performed after the original test to provide additional context to the results.
Analysis of variance, or ANOVA, tests can observe mean differences in a quantitative variable between values of a categorical variable, typically with three or more values to distinguish from a t-test. ANOVA could add patients given dabigatran to the previous population and evaluate whether the length of stay was significantly different across the three medications. If the p-value is lower than the designated significance level then the hypothesis that length of stay was the same across the three medications is rejected. Summaries and post-hoc tests also could be performed to look at the differences between length of stay and which individual medications may have observed statistically significant differences in length of stay from the other medications. A chi-square test examines the association between two categorical variables. An example would be to consider whether the rate of having a post-operative bleed is the same across patients provided with apixaban, rivaroxaban and dabigatran. A chi-square test can compute a p-value determining whether the bleeding rates were significantly different or not. Post-hoc tests could then give the bleeding rate for each medication, as well as a breakdown as to which specific medications may have a significantly different bleeding rate from each other.
A slightly more advanced way of examining a question can come through multiple regression. Regression allows more predictor variables to be analyzed and can act as a control when looking at associations between variables. Common control variables are age, sex and any comorbidities likely to affect the outcome variable that are not closely related to the other explanatory variables. Control variables can be especially important in reducing the effect of bias in a retrospective population. Since retrospective data was not built with the research question in mind, it is important to eliminate threats to the validity of the analysis. Testing that controls for confounding variables, such as regression, is often more valuable with retrospective data because it can ease these concerns. The two main types of regression are linear and logistic. Linear regression is used to predict differences in a quantitative, continuous response variable, such as length of stay. Logistic regression predicts differences in a dichotomous, categorical response variable, such as 90-day readmission. So whether the outcome variable is categorical or quantitative, regression can be appropriate. An example for each of these types could be found in two similar cases. For both examples define the predictor variables as age, gender and anticoagulant usage. In the first, use the predictor variables in a linear regression to evaluate their individual effects on length of stay, a quantitative variable. For the second, use the same predictor variables in a logistic regression to evaluate their individual effects on whether the patient had a 90-day readmission, a dichotomous categorical variable. Analysis can compute a p-value for each included predictor variable to determine whether they are significantly associated. The statistical tests in this article generate an associated test statistic which determines the probability the results could be acquired given that there is no association between the compared variables. These results often come with coefficients which can give the degree of the association and the degree to which one variable changes with another. Most tests, including all listed in this article, also have confidence intervals, which give a range for the correlation with a specified level of confidence. Even if these tests do not give statistically significant results, the results are still important. Not reporting statistically insignificant findings creates a bias in research. Ideas can be repeated enough times that eventually statistically significant results are reached, even though there is no true significance. In some cases with very large sample sizes, p-values will almost always be significant. In this case the effect size is critical as even the smallest, meaningless differences can be found to be statistically significant.
These variables and tests are just some things to keep in mind before, during and after the analysis process in order to make sure that the statistical reports are supporting the questions being answered. The patient population, types of variables and statistical tests are all important things to consider in the process of statistical analysis. Any results are only as useful as the process used to obtain them. This primer can be used as a reference to help ensure appropriate statistical analysis.
Funding Statement
This research was supported (in whole or in part) by HCA Healthcare and/or an HCA Healthcare affiliated entity.
Conflicts of Interest
The author declares he has no conflicts of interest.
Christian Vandever is an employee of HCA Healthcare Graduate Medical Education, an organization affiliated with the journal’s publisher.
This research was supported (in whole or in part) by HCA Healthcare and/or an HCA Healthcare affiliated entity. The views expressed in this publication represent those of the author(s) and do not necessarily represent the official views of HCA Healthcare or any of its affiliated entities.
Quantitative Data Analysis: A Comprehensive Guide
By: Ofem Eteng | Published: May 18, 2022
Related Articles
A healthcare giant successfully introduces the most effective drug dosage through rigorous statistical modeling, saving countless lives. A marketing team predicts consumer trends with uncanny accuracy, tailoring campaigns for maximum impact.
Table of Contents
These trends and dosages are not just any numbers but are a result of meticulous quantitative data analysis. Quantitative data analysis offers a robust framework for understanding complex phenomena, evaluating hypotheses, and predicting future outcomes.
In this blog, we’ll walk through the concept of quantitative data analysis, the steps required, its advantages, and the methods and techniques that are used in this analysis. Read on!
What is Quantitative Data Analysis?
Quantitative data analysis is a systematic process of examining, interpreting, and drawing meaningful conclusions from numerical data. It involves the application of statistical methods, mathematical models, and computational techniques to understand patterns, relationships, and trends within datasets.
Quantitative data analysis methods typically work with algorithms, mathematical analysis tools, and software to gain insights from the data, answering questions such as how many, how often, and how much. Data for quantitative data analysis is usually collected from close-ended surveys, questionnaires, polls, etc. The data can also be obtained from sales figures, email click-through rates, number of website visitors, and percentage revenue increase.
Quantitative Data Analysis vs Qualitative Data Analysis
When we talk about data, we directly think about the pattern, the relationship, and the connection between the datasets – analyzing the data in short. Therefore when it comes to data analysis, there are broadly two types – Quantitative Data Analysis and Qualitative Data Analysis.
Quantitative data analysis revolves around numerical data and statistics, which are suitable for functions that can be counted or measured. In contrast, qualitative data analysis includes description and subjective information – for things that can be observed but not measured.
Let us differentiate between Quantitative Data Analysis and Quantitative Data Analysis for a better understanding.
Data Preparation Steps for Quantitative Data Analysis
Quantitative data has to be gathered and cleaned before proceeding to the stage of analyzing it. Below are the steps to prepare a data before quantitative research analysis:
- Step 1: Data Collection
Before beginning the analysis process, you need data. Data can be collected through rigorous quantitative research, which includes methods such as interviews, focus groups, surveys, and questionnaires.
- Step 2: Data Cleaning
Once the data is collected, begin the data cleaning process by scanning through the entire data for duplicates, errors, and omissions. Keep a close eye for outliers (data points that are significantly different from the majority of the dataset) because they can skew your analysis results if they are not removed.
This data-cleaning process ensures data accuracy, consistency and relevancy before analysis.
- Step 3: Data Analysis and Interpretation
Now that you have collected and cleaned your data, it is now time to carry out the quantitative analysis. There are two methods of quantitative data analysis, which we will discuss in the next section.
However, if you have data from multiple sources, collecting and cleaning it can be a cumbersome task. This is where Hevo Data steps in. With Hevo, extracting, transforming, and loading data from source to destination becomes a seamless task, eliminating the need for manual coding. This not only saves valuable time but also enhances the overall efficiency of data analysis and visualization, empowering users to derive insights quickly and with precision
Hevo is the only real-time ELT No-code Data Pipeline platform that cost-effectively automates data pipelines that are flexible to your needs. With integration with 150+ Data Sources (40+ free sources), we help you not only export data from sources & load data to the destinations but also transform & enrich your data, & make it analysis-ready.
Start for free now!
Now that you are familiar with what quantitative data analysis is and how to prepare your data for analysis, the focus will shift to the purpose of this article, which is to describe the methods and techniques of quantitative data analysis.
Methods and Techniques of Quantitative Data Analysis
Quantitative data analysis employs two techniques to extract meaningful insights from datasets, broadly. The first method is descriptive statistics, which summarizes and portrays essential features of a dataset, such as mean, median, and standard deviation.
Inferential statistics, the second method, extrapolates insights and predictions from a sample dataset to make broader inferences about an entire population, such as hypothesis testing and regression analysis.
An in-depth explanation of both the methods is provided below:
- Descriptive Statistics
- Inferential Statistics
1) Descriptive Statistics
Descriptive statistics as the name implies is used to describe a dataset. It helps understand the details of your data by summarizing it and finding patterns from the specific data sample. They provide absolute numbers obtained from a sample but do not necessarily explain the rationale behind the numbers and are mostly used for analyzing single variables. The methods used in descriptive statistics include:
- Mean: This calculates the numerical average of a set of values.
- Median: This is used to get the midpoint of a set of values when the numbers are arranged in numerical order.
- Mode: This is used to find the most commonly occurring value in a dataset.
- Percentage: This is used to express how a value or group of respondents within the data relates to a larger group of respondents.
- Frequency: This indicates the number of times a value is found.
- Range: This shows the highest and lowest values in a dataset.
- Standard Deviation: This is used to indicate how dispersed a range of numbers is, meaning, it shows how close all the numbers are to the mean.
- Skewness: It indicates how symmetrical a range of numbers is, showing if they cluster into a smooth bell curve shape in the middle of the graph or if they skew towards the left or right.
2) Inferential Statistics
In quantitative analysis, the expectation is to turn raw numbers into meaningful insight using numerical values, and descriptive statistics is all about explaining details of a specific dataset using numbers, but it does not explain the motives behind the numbers; hence, a need for further analysis using inferential statistics.
Inferential statistics aim to make predictions or highlight possible outcomes from the analyzed data obtained from descriptive statistics. They are used to generalize results and make predictions between groups, show relationships that exist between multiple variables, and are used for hypothesis testing that predicts changes or differences.
There are various statistical analysis methods used within inferential statistics; a few are discussed below.
- Cross Tabulations: Cross tabulation or crosstab is used to show the relationship that exists between two variables and is often used to compare results by demographic groups. It uses a basic tabular form to draw inferences between different data sets and contains data that is mutually exclusive or has some connection with each other. Crosstabs help understand the nuances of a dataset and factors that may influence a data point.
- Regression Analysis: Regression analysis estimates the relationship between a set of variables. It shows the correlation between a dependent variable (the variable or outcome you want to measure or predict) and any number of independent variables (factors that may impact the dependent variable). Therefore, the purpose of the regression analysis is to estimate how one or more variables might affect a dependent variable to identify trends and patterns to make predictions and forecast possible future trends. There are many types of regression analysis, and the model you choose will be determined by the type of data you have for the dependent variable. The types of regression analysis include linear regression, non-linear regression, binary logistic regression, etc.
- Monte Carlo Simulation: Monte Carlo simulation, also known as the Monte Carlo method, is a computerized technique of generating models of possible outcomes and showing their probability distributions. It considers a range of possible outcomes and then tries to calculate how likely each outcome will occur. Data analysts use it to perform advanced risk analyses to help forecast future events and make decisions accordingly.
- Analysis of Variance (ANOVA): This is used to test the extent to which two or more groups differ from each other. It compares the mean of various groups and allows the analysis of multiple groups.
- Factor Analysis: A large number of variables can be reduced into a smaller number of factors using the factor analysis technique. It works on the principle that multiple separate observable variables correlate with each other because they are all associated with an underlying construct. It helps in reducing large datasets into smaller, more manageable samples.
- Cohort Analysis: Cohort analysis can be defined as a subset of behavioral analytics that operates from data taken from a given dataset. Rather than looking at all users as one unit, cohort analysis breaks down data into related groups for analysis, where these groups or cohorts usually have common characteristics or similarities within a defined period.
- MaxDiff Analysis: This is a quantitative data analysis method that is used to gauge customers’ preferences for purchase and what parameters rank higher than the others in the process.
- Cluster Analysis: Cluster analysis is a technique used to identify structures within a dataset. Cluster analysis aims to be able to sort different data points into groups that are internally similar and externally different; that is, data points within a cluster will look like each other and different from data points in other clusters.
- Time Series Analysis: This is a statistical analytic technique used to identify trends and cycles over time. It is simply the measurement of the same variables at different times, like weekly and monthly email sign-ups, to uncover trends, seasonality, and cyclic patterns. By doing this, the data analyst can forecast how variables of interest may fluctuate in the future.
- SWOT analysis: This is a quantitative data analysis method that assigns numerical values to indicate strengths, weaknesses, opportunities, and threats of an organization, product, or service to show a clearer picture of competition to foster better business strategies
How to Choose the Right Method for your Analysis?
Choosing between Descriptive Statistics or Inferential Statistics can be often confusing. You should consider the following factors before choosing the right method for your quantitative data analysis:
1. Type of Data
The first consideration in data analysis is understanding the type of data you have. Different statistical methods have specific requirements based on these data types, and using the wrong method can render results meaningless. The choice of statistical method should align with the nature and distribution of your data to ensure meaningful and accurate analysis.
2. Your Research Questions
When deciding on statistical methods, it’s crucial to align them with your specific research questions and hypotheses. The nature of your questions will influence whether descriptive statistics alone, which reveal sample attributes, are sufficient or if you need both descriptive and inferential statistics to understand group differences or relationships between variables and make population inferences.
Pros and Cons of Quantitative Data Analysis
1. Objectivity and Generalizability:
- Quantitative data analysis offers objective, numerical measurements, minimizing bias and personal interpretation.
- Results can often be generalized to larger populations, making them applicable to broader contexts.
Example: A study using quantitative data analysis to measure student test scores can objectively compare performance across different schools and demographics, leading to generalizable insights about educational strategies.
2. Precision and Efficiency:
- Statistical methods provide precise numerical results, allowing for accurate comparisons and prediction.
- Large datasets can be analyzed efficiently with the help of computer software, saving time and resources.
Example: A marketing team can use quantitative data analysis to precisely track click-through rates and conversion rates on different ad campaigns, quickly identifying the most effective strategies for maximizing customer engagement.
3. Identification of Patterns and Relationships:
- Statistical techniques reveal hidden patterns and relationships between variables that might not be apparent through observation alone.
- This can lead to new insights and understanding of complex phenomena.
Example: A medical researcher can use quantitative analysis to pinpoint correlations between lifestyle factors and disease risk, aiding in the development of prevention strategies.
1. Limited Scope:
- Quantitative analysis focuses on quantifiable aspects of a phenomenon , potentially overlooking important qualitative nuances, such as emotions, motivations, or cultural contexts.
Example: A survey measuring customer satisfaction with numerical ratings might miss key insights about the underlying reasons for their satisfaction or dissatisfaction, which could be better captured through open-ended feedback.
2. Oversimplification:
- Reducing complex phenomena to numerical data can lead to oversimplification and a loss of richness in understanding.
Example: Analyzing employee productivity solely through quantitative metrics like hours worked or tasks completed might not account for factors like creativity, collaboration, or problem-solving skills, which are crucial for overall performance.
3. Potential for Misinterpretation:
- Statistical results can be misinterpreted if not analyzed carefully and with appropriate expertise.
- The choice of statistical methods and assumptions can significantly influence results.
This blog discusses the steps, methods, and techniques of quantitative data analysis. It also gives insights into the methods of data collection, the type of data one should work with, and the pros and cons of such analysis.
Gain a better understanding of data analysis with these essential reads:
- Data Analysis and Modeling: 4 Critical Differences
- Exploratory Data Analysis Simplified 101
- 25 Best Data Analysis Tools in 2024
Carrying out successful data analysis requires prepping the data and making it analysis-ready. That is where Hevo steps in.
Want to give Hevo a try? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite first hand. You may also have a look at the amazing Hevo price , which will assist you in selecting the best plan for your requirements.
Share your experience of understanding Quantitative Data Analysis in the comment section below! We would love to hear your thoughts.

Ofem is a freelance writer specializing in data-related topics, who has expertise in translating complex concepts. With a focus on data science, analytics, and emerging technologies.
No-code Data Pipeline for your Data Warehouse
- Data Analysis
- Data Warehouse
- Quantitative Data Analysis
Continue Reading

Skand Agrawal
Working With AWS Lambda Java Functions: 6 Easy Steps

Harsh Varshney
MariaDB Foreign Key: A Comprehensive Guide 101

Manisha Sharma
Enterprise Data Repository: Types, Benefits, & Best Practices
I want to read this e-book.
The Importance of Data Analysis in Research
Studying data is amongst the everyday chores of researchers. It’s not a big deal for them to go through hundreds of pages per day to extract useful information from it. However, recent times have seen a massive jump in the amount of data available. While it’s certainly good news for researchers to get their hands on more data that could result in better studies, it’s also no less than a headache.
Thankfully, the rising trend of data science in the past years has also meant a sharp rise in data analysis techniques . These tools and techniques save a lot of time in hefty processes a researcher has to go through and allow them to finish the work of days in minutes!
As a famous saying goes,
“Information is the oil of the 21st century , and analytics is the combustion engine.”
– Peter Sondergaard , senior vice president, Gartner Research.
So, if you’re also a researcher or just curious about the most important data analysis techniques in research, this article is for you. Make sure you give it a thorough read, as I’ll be dropping some very important points throughout the article.
What is the Importance of Data Analysis in Research?
Data analysis is important in research because it makes studying data a lot simpler and more accurate. It helps the researchers straightforwardly interpret the data so that researchers don’t leave anything out that could help them derive insights from it.
Data analysis is a way to study and analyze huge amounts of data. Research often includes going through heaps of data, which is getting more and more for the researchers to handle with every passing minute.
Hence, data analysis knowledge is a huge edge for researchers in the current era, making them very efficient and productive.
What is Data Analysis?
Once the data is cleaned , transformed , and ready to use, it can do wonders. Not only does it contain a variety of useful information, studying the data collectively results in uncovering very minor patterns and details that would otherwise have been ignored.
So, you can see why it has such a huge role to play in research. Research is all about studying patterns and trends, followed by making a hypothesis and proving them. All this is supported by appropriate data.
Further in the article, we’ll see some of the most important types of data analysis that you should be aware of as a researcher so you can put them to use.
The Role of Data Analytics at The Senior Management Level

From small and medium-sized businesses to Fortune 500 conglomerates, the success of a modern business is now increasingly tied to how the company implements its data infrastructure and data-based decision-making. According
The Decision-Making Model Explained (In Plain Terms)

Any form of the systematic decision-making process is better enhanced with data. But making sense of big data or even small data analysis when venturing into a decision-making process might
13 Reasons Why Data Is Important in Decision Making

Data is important in decision making process, and that is the new golden rule in the business world. Businesses are always trying to find the balance of cutting costs while
Types of Data Analysis: Qualitative Vs Quantitative
Looking at it from a broader perspective, data analysis boils down to two major types. Namely, qualitative data analysis and quantitative data analysis. While the latter deals with the numerical data, comprising of numbers, the former comes in the non-text form. It can be anything such as summaries, images, symbols, and so on.
Both types have different methods to deal with them and we’ll be taking a look at both of them so you can use whatever suits your requirements.
Qualitative Data Analysis
As mentioned before, qualitative data comprises non-text-based data, and it can be either in the form of text or images. So, how do we analyze such data? Before we start, here are a few common tips first that you should always use before applying any techniques.
Now, let’s move ahead and see where the qualitative data analysis techniques come in. Even though there are a lot of professional ways to achieve this, here are some of them that you’ll need to know as a beginner.
Narrative Analysis
If your research is based upon collecting some answers from people in interviews or other scenarios, this might be one of the best analysis techniques for you. The narrative analysis helps to analyze the narratives of various people, which is available in textual form. The stories, experiences, and other answers from respondents are used to power the analysis.
The important thing to note here is that the data has to be available in the form of text only. Narrative analysis cannot be performed on other data types such as images.
Content Analysis
Content analysis is amongst the most used methods in analyzing quantitative data. This method doesn’t put a restriction on the form of data. You can use any kind of data here, whether it’s in the form of images, text, or even real-life items.
Here, an important application is when you know the questions you need to know the answers to. Upon getting the answers, you can perform this method to perform analysis to them, followed by extracting insights from it to be used in your research. It’s a full-fledged method and a lot of analytical studies are based solely on this.
Grounded Theory
Grounded theory is used when the researchers want to know the reason behind the occurrence of a certain event. They may have to go through a lot of different use cases and comparing them to each other while following this approach. It’s an iterative approach and the explanations keep on being modified or re-created till the researchers end up on a suitable conclusion that satisfies their specific conditions.
So, make sure you employ this method if you need to have certain qualitative data at hand and you need to know the reason why something happened, based on that data.
Discourse Analysis
Discourse analysis is quite similar to narrative analysis in the sense that it also uses interactions with people for the analysis purpose. The only difference is that the focal point here is different. Instead of analyzing the narrative, the researchers focus on the context in which the conversation is happening.
The complete background of the person being questioned, including his everyday environment, is used to perform the research.
Quantitative Analysis
Quantitative analysis involves any kind of analysis that’s being done on numbers. From the most basic analysis techniques to the most advanced ones, quantitative analysis techniques comprise a huge range of techniques. No matter what level of research you need to do, if it’s based on numerical data, you’ll always have efficient analysis methods to use.
There are two broad ways here; Descriptive statistics and inferential analysis .
However, before applying the analysis methods on numerical data, there are a few pre-processing steps that need to be done. These steps are used to make the data ‘ready’ for applying the analysis methods.
Make sure you don’t miss these steps, or you will end up drawing biased conclusions from the data analysis. IF you want to know why data is the key in data analysis and problem-solving, feel free to check out this article here . Now, about the steps for PRE-PROCESSING THE QUANTITATIVE DATA .
Descriptive Statistics
Descriptive statistics is the most basic step that researchers can use to draw conclusions from data. It helps to find patterns and helps the data ‘speak’. Let’s see some of the most common data analysis techniques used to perform descriptive statistics .
Mean is nothing but the average of the total data available at hand. The formula is simple and tells what average value to expect throughout the data.
The median is the middle value available in the data. It lets the researchers estimate where the mid-point of the data is. It’s important to note that the data needs to be sorted to find the median from it.
The mode is simply the most frequently occurring data in the dataset. For example, if you’re studying the ages of students in a particular class, the model will be the age of most students in the class.
- Standard Deviation
Numerical data is always spread over a wide range and finding out how much the data is spread is quite important. Standard deviation is what lets us achieve this. It tells us how much an average data point is far from the average.
Related Article: The Best Programming Language for Statistics
Inferential Analysis
Inferential statistics point towards the techniques used to predict future occurrences of data. These methods help draw relationships between data and once it’s done, predicting future data becomes possible.
- Correlation
Correlation s the measure of the relationship between two numerical variables. It measures the degree of their relation, whether it is causal or not.
For example, the age and height of a person are highly correlated. If the age of a person increases, height is also likely to increase. This is called a positive correlation.
A negative correlation means that upon increasing one variable, the other one decreases. An example would be the relationship between the age and maturity of a random person.
Regression aims to find the mathematical relationship between a set of variables. While the correlation was a statistical measure, regression is a mathematical measure that can be measured in the form of variables. Once the relationship between variables is formed, one variable can be used to predict the other variable.
This method has a huge application when it comes to predicting future data. If your research is based upon calculating future occurrences of some data based on past data and then testing it, make sure you use this method.
A Summary of Data Analysis Methods
Now that we’re done with some of the most common methods for both quantitative and qualitative data, let’s summarize them in a tabular form so you would have something to take home in the end.
Before we close the article, I’d like to strongly recommend you to check out some interesting related topics:
That’s it! We have seen why data analysis is such an important tool when it comes to research and how it saves a huge lot of time for the researchers, making them not only efficient but more productive as well.
Moreover, the article covers some of the most important data analysis techniques that one needs to know for research purposes in today’s age. We’ve gone through the analysis methods for both quantitative and qualitative data in a basic way so it might be easy to understand for beginners.
Emidio Amadebai
As an IT Engineer, who is passionate about learning and sharing. I have worked and learned quite a bit from Data Engineers, Data Analysts, Business Analysts, and Key Decision Makers almost for the past 5 years. Interested in learning more about Data Science and How to leverage it for better decision-making in my business and hopefully help you do the same in yours.
Recent Posts
Causal vs Evidential Decision-making (How to Make Businesses More Effective)
In today’s fast-paced business landscape, it is crucial to make informed decisions to stay in the competition which makes it important to understand the concept of the different characteristics and...
Bootstrapping vs. Boosting
Over the past decade, the field of machine learning has witnessed remarkable advancements in predictive techniques and ensemble learning methods. Ensemble techniques are very popular in machine...

Quantitative Data Analysis 101
The lingo, methods and techniques, explained simply.
By: Derek Jansen (MBA) and Kerryn Warren (PhD) | December 2020
Quantitative data analysis is one of those things that often strikes fear in students. It’s totally understandable – quantitative analysis is a complex topic, full of daunting lingo , like medians, modes, correlation and regression. Suddenly we’re all wishing we’d paid a little more attention in math class…
The good news is that while quantitative data analysis is a mammoth topic, gaining a working understanding of the basics isn’t that hard , even for those of us who avoid numbers and math . In this post, we’ll break quantitative analysis down into simple , bite-sized chunks so you can approach your research with confidence.

Overview: Quantitative Data Analysis 101
- What (exactly) is quantitative data analysis?
- When to use quantitative analysis
- How quantitative analysis works
The two “branches” of quantitative analysis
- Descriptive statistics 101
- Inferential statistics 101
- How to choose the right quantitative methods
- Recap & summary
What is quantitative data analysis?
Despite being a mouthful, quantitative data analysis simply means analysing data that is numbers-based – or data that can be easily “converted” into numbers without losing any meaning.
For example, category-based variables like gender, ethnicity, or native language could all be “converted” into numbers without losing meaning – for example, English could equal 1, French 2, etc.
This contrasts against qualitative data analysis, where the focus is on words, phrases and expressions that can’t be reduced to numbers. If you’re interested in learning about qualitative analysis, check out our post and video here .
What is quantitative analysis used for?
Quantitative analysis is generally used for three purposes.
- Firstly, it’s used to measure differences between groups . For example, the popularity of different clothing colours or brands.
- Secondly, it’s used to assess relationships between variables . For example, the relationship between weather temperature and voter turnout.
- And third, it’s used to test hypotheses in a scientifically rigorous way. For example, a hypothesis about the impact of a certain vaccine.
Again, this contrasts with qualitative analysis , which can be used to analyse people’s perceptions and feelings about an event or situation. In other words, things that can’t be reduced to numbers.
How does quantitative analysis work?
Well, since quantitative data analysis is all about analysing numbers , it’s no surprise that it involves statistics . Statistical analysis methods form the engine that powers quantitative analysis, and these methods can vary from pretty basic calculations (for example, averages and medians) to more sophisticated analyses (for example, correlations and regressions).
Sounds like gibberish? Don’t worry. We’ll explain all of that in this post. Importantly, you don’t need to be a statistician or math wiz to pull off a good quantitative analysis. We’ll break down all the technical mumbo jumbo in this post.
Need a helping hand?
As I mentioned, quantitative analysis is powered by statistical analysis methods . There are two main “branches” of statistical methods that are used – descriptive statistics and inferential statistics . In your research, you might only use descriptive statistics, or you might use a mix of both , depending on what you’re trying to figure out. In other words, depending on your research questions, aims and objectives . I’ll explain how to choose your methods later.
So, what are descriptive and inferential statistics?
Well, before I can explain that, we need to take a quick detour to explain some lingo. To understand the difference between these two branches of statistics, you need to understand two important words. These words are population and sample .
First up, population . In statistics, the population is the entire group of people (or animals or organisations or whatever) that you’re interested in researching. For example, if you were interested in researching Tesla owners in the US, then the population would be all Tesla owners in the US.
However, it’s extremely unlikely that you’re going to be able to interview or survey every single Tesla owner in the US. Realistically, you’ll likely only get access to a few hundred, or maybe a few thousand owners using an online survey. This smaller group of accessible people whose data you actually collect is called your sample .
So, to recap – the population is the entire group of people you’re interested in, and the sample is the subset of the population that you can actually get access to. In other words, the population is the full chocolate cake , whereas the sample is a slice of that cake.
So, why is this sample-population thing important?
Well, descriptive statistics focus on describing the sample , while inferential statistics aim to make predictions about the population, based on the findings within the sample. In other words, we use one group of statistical methods – descriptive statistics – to investigate the slice of cake, and another group of methods – inferential statistics – to draw conclusions about the entire cake. There I go with the cake analogy again…
With that out the way, let’s take a closer look at each of these branches in more detail.

Branch 1: Descriptive Statistics
Descriptive statistics serve a simple but critically important role in your research – to describe your data set – hence the name. In other words, they help you understand the details of your sample . Unlike inferential statistics (which we’ll get to soon), descriptive statistics don’t aim to make inferences or predictions about the entire population – they’re purely interested in the details of your specific sample .
When you’re writing up your analysis, descriptive statistics are the first set of stats you’ll cover, before moving on to inferential statistics. But, that said, depending on your research objectives and research questions , they may be the only type of statistics you use. We’ll explore that a little later.
So, what kind of statistics are usually covered in this section?
Some common statistical tests used in this branch include the following:
- Mean – this is simply the mathematical average of a range of numbers.
- Median – this is the midpoint in a range of numbers when the numbers are arranged in numerical order. If the data set makes up an odd number, then the median is the number right in the middle of the set. If the data set makes up an even number, then the median is the midpoint between the two middle numbers.
- Mode – this is simply the most commonly occurring number in the data set.
- In cases where most of the numbers are quite close to the average, the standard deviation will be relatively low.
- Conversely, in cases where the numbers are scattered all over the place, the standard deviation will be relatively high.
- Skewness . As the name suggests, skewness indicates how symmetrical a range of numbers is. In other words, do they tend to cluster into a smooth bell curve shape in the middle of the graph, or do they skew to the left or right?
Feeling a bit confused? Let’s look at a practical example using a small data set.

On the left-hand side is the data set. This details the bodyweight of a sample of 10 people. On the right-hand side, we have the descriptive statistics. Let’s take a look at each of them.
First, we can see that the mean weight is 72.4 kilograms. In other words, the average weight across the sample is 72.4 kilograms. Straightforward.
Next, we can see that the median is very similar to the mean (the average). This suggests that this data set has a reasonably symmetrical distribution (in other words, a relatively smooth, centred distribution of weights, clustered towards the centre).
In terms of the mode , there is no mode in this data set. This is because each number is present only once and so there cannot be a “most common number”. If there were two people who were both 65 kilograms, for example, then the mode would be 65.
Next up is the standard deviation . 10.6 indicates that there’s quite a wide spread of numbers. We can see this quite easily by looking at the numbers themselves, which range from 55 to 90, which is quite a stretch from the mean of 72.4.
And lastly, the skewness of -0.2 tells us that the data is very slightly negatively skewed. This makes sense since the mean and the median are slightly different.
As you can see, these descriptive statistics give us some useful insight into the data set. Of course, this is a very small data set (only 10 records), so we can’t read into these statistics too much. Also, keep in mind that this is not a list of all possible descriptive statistics – just the most common ones.
But why do all of these numbers matter?
While these descriptive statistics are all fairly basic, they’re important for a few reasons:
- Firstly, they help you get both a macro and micro-level view of your data. In other words, they help you understand both the big picture and the finer details.
- Secondly, they help you spot potential errors in the data – for example, if an average is way higher than you’d expect, or responses to a question are highly varied, this can act as a warning sign that you need to double-check the data.
- And lastly, these descriptive statistics help inform which inferential statistical techniques you can use, as those techniques depend on the skewness (in other words, the symmetry and normality) of the data.
Simply put, descriptive statistics are really important , even though the statistical techniques used are fairly basic. All too often at Grad Coach, we see students skimming over the descriptives in their eagerness to get to the more exciting inferential methods, and then landing up with some very flawed results.
Don’t be a sucker – give your descriptive statistics the love and attention they deserve!

Branch 2: Inferential Statistics
As I mentioned, while descriptive statistics are all about the details of your specific data set – your sample – inferential statistics aim to make inferences about the population . In other words, you’ll use inferential statistics to make predictions about what you’d expect to find in the full population.
What kind of predictions, you ask? Well, there are two common types of predictions that researchers try to make using inferential stats:
- Firstly, predictions about differences between groups – for example, height differences between children grouped by their favourite meal or gender.
- And secondly, relationships between variables – for example, the relationship between body weight and the number of hours a week a person does yoga.
In other words, inferential statistics (when done correctly), allow you to connect the dots and make predictions about what you expect to see in the real world population, based on what you observe in your sample data. For this reason, inferential statistics are used for hypothesis testing – in other words, to test hypotheses that predict changes or differences.

Of course, when you’re working with inferential statistics, the composition of your sample is really important. In other words, if your sample doesn’t accurately represent the population you’re researching, then your findings won’t necessarily be very useful.
For example, if your population of interest is a mix of 50% male and 50% female , but your sample is 80% male , you can’t make inferences about the population based on your sample, since it’s not representative. This area of statistics is called sampling, but we won’t go down that rabbit hole here (it’s a deep one!) – we’ll save that for another post .
What statistics are usually used in this branch?
There are many, many different statistical analysis methods within the inferential branch and it’d be impossible for us to discuss them all here. So we’ll just take a look at some of the most common inferential statistical methods so that you have a solid starting point.
First up are T-Tests . T-tests compare the means (the averages) of two groups of data to assess whether they’re statistically significantly different. In other words, do they have significantly different means, standard deviations and skewness.
This type of testing is very useful for understanding just how similar or different two groups of data are. For example, you might want to compare the mean blood pressure between two groups of people – one that has taken a new medication and one that hasn’t – to assess whether they are significantly different.
Kicking things up a level, we have ANOVA, which stands for “analysis of variance”. This test is similar to a T-test in that it compares the means of various groups, but ANOVA allows you to analyse multiple groups , not just two groups So it’s basically a t-test on steroids…
Next, we have correlation analysis . This type of analysis assesses the relationship between two variables. In other words, if one variable increases, does the other variable also increase, decrease or stay the same. For example, if the average temperature goes up, do average ice creams sales increase too? We’d expect some sort of relationship between these two variables intuitively , but correlation analysis allows us to measure that relationship scientifically .
Lastly, we have regression analysis – this is quite similar to correlation in that it assesses the relationship between variables, but it goes a step further to understand cause and effect between variables, not just whether they move together. In other words, does the one variable actually cause the other one to move, or do they just happen to move together naturally thanks to another force? Just because two variables correlate doesn’t necessarily mean that one causes the other.
Stats overload…
I hear you. To make this all a little more tangible, let’s take a look at an example of a correlation in action.
Here’s a scatter plot demonstrating the correlation (relationship) between weight and height. Intuitively, we’d expect there to be some relationship between these two variables, which is what we see in this scatter plot. In other words, the results tend to cluster together in a diagonal line from bottom left to top right.

As I mentioned, these are are just a handful of inferential techniques – there are many, many more. Importantly, each statistical method has its own assumptions and limitations .
For example, some methods only work with normally distributed (parametric) data, while other methods are designed specifically for non-parametric data. And that’s exactly why descriptive statistics are so important – they’re the first step to knowing which inferential techniques you can and can’t use.

How to choose the right analysis method
To choose the right statistical methods, you need to think about two important factors :
- The type of quantitative data you have (specifically, level of measurement and the shape of the data). And,
- Your research questions and hypotheses
Let’s take a closer look at each of these.
Factor 1 – Data type
The first thing you need to consider is the type of data you’ve collected (or the type of data you will collect). By data types, I’m referring to the four levels of measurement – namely, nominal, ordinal, interval and ratio. If you’re not familiar with this lingo, check out the video below.
Why does this matter?
Well, because different statistical methods and techniques require different types of data. This is one of the “assumptions” I mentioned earlier – every method has its assumptions regarding the type of data.
For example, some techniques work with categorical data (for example, yes/no type questions, or gender or ethnicity), while others work with continuous numerical data (for example, age, weight or income) – and, of course, some work with multiple data types.
If you try to use a statistical method that doesn’t support the data type you have, your results will be largely meaningless . So, make sure that you have a clear understanding of what types of data you’ve collected (or will collect). Once you have this, you can then check which statistical methods would support your data types here .
If you haven’t collected your data yet, you can work in reverse and look at which statistical method would give you the most useful insights, and then design your data collection strategy to collect the correct data types.
Another important factor to consider is the shape of your data . Specifically, does it have a normal distribution (in other words, is it a bell-shaped curve, centred in the middle) or is it very skewed to the left or the right? Again, different statistical techniques work for different shapes of data – some are designed for symmetrical data while others are designed for skewed data.
This is another reminder of why descriptive statistics are so important – they tell you all about the shape of your data.
Factor 2: Your research questions
The next thing you need to consider is your specific research questions, as well as your hypotheses (if you have some). The nature of your research questions and research hypotheses will heavily influence which statistical methods and techniques you should use.
If you’re just interested in understanding the attributes of your sample (as opposed to the entire population), then descriptive statistics are probably all you need. For example, if you just want to assess the means (averages) and medians (centre points) of variables in a group of people.
On the other hand, if you aim to understand differences between groups or relationships between variables and to infer or predict outcomes in the population, then you’ll likely need both descriptive statistics and inferential statistics.
So, it’s really important to get very clear about your research aims and research questions, as well your hypotheses – before you start looking at which statistical techniques to use.
Never shoehorn a specific statistical technique into your research just because you like it or have some experience with it. Your choice of methods must align with all the factors we’ve covered here.
Time to recap…
You’re still with me? That’s impressive. We’ve covered a lot of ground here, so let’s recap on the key points:
- Quantitative data analysis is all about analysing number-based data (which includes categorical and numerical data) using various statistical techniques.
- The two main branches of statistics are descriptive statistics and inferential statistics . Descriptives describe your sample, whereas inferentials make predictions about what you’ll find in the population.
- Common descriptive statistical methods include mean (average), median , standard deviation and skewness .
- Common inferential statistical methods include t-tests , ANOVA , correlation and regression analysis.
- To choose the right statistical methods and techniques, you need to consider the type of data you’re working with , as well as your research questions and hypotheses.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
You Might Also Like:
")
75 Comments

Hi, I have read your article. Such a brilliant post you have created.

Thank you for the feedback. Good luck with your quantitative analysis.

Thank you so much.

Thank you so much. I learnt much well. I love your summaries of the concepts. I had love you to explain how to input data using SPSS

Amazing and simple way of breaking down quantitative methods.

This is beautiful….especially for non-statisticians. I have skimmed through but I wish to read again. and please include me in other articles of the same nature when you do post. I am interested. I am sure, I could easily learn from you and get off the fear that I have had in the past. Thank you sincerely.

Send me every new information you might have.

i need every new information

Thank you for the blog. It is quite informative. Dr Peter Nemaenzhe PhD

It is wonderful. l’ve understood some of the concepts in a more compréhensive manner

Your article is so good! However, I am still a bit lost. I am doing a secondary research on Gun control in the US and increase in crime rates and I am not sure which analysis method I should use?

Based on the given learning points, this is inferential analysis, thus, use ‘t-tests, ANOVA, correlation and regression analysis’

Well explained notes. Am an MPH student and currently working on my thesis proposal, this has really helped me understand some of the things I didn’t know.

I like your page..helpful

wonderful i got my concept crystal clear. thankyou!!

This is really helpful , thank you

Thank you so much this helped

Wonderfully explained

thank u so much, it was so informative

THANKYOU, this was very informative and very helpful

This is great GRADACOACH I am not a statistician but I require more of this in my thesis
Include me in your posts.

This is so great and fully useful. I would like to thank you again and again.

Glad to read this article. I’ve read lot of articles but this article is clear on all concepts. Thanks for sharing.

Thank you so much. This is a very good foundation and intro into quantitative data analysis. Appreciate!

You have a very impressive, simple but concise explanation of data analysis for Quantitative Research here. This is a God-send link for me to appreciate research more. Thank you so much!

Avery good presentation followed by the write up. yes you simplified statistics to make sense even to a layman like me. Thank so much keep it up. The presenter did ell too. i would like more of this for Qualitative and exhaust more of the test example like the Anova.

This is a very helpful article, couldn’t have been clearer. Thank you.

Awesome and phenomenal information.Well done

The video with the accompanying article is super helpful to demystify this topic. Very well done. Thank you so much.

thank you so much, your presentation helped me a lot

I don’t know how should I express that ur article is saviour for me 🥺😍

It is well defined information and thanks for sharing. It helps me a lot in understanding the statistical data.

I gain a lot and thanks for sharing brilliant ideas, so wish to be linked on your email update.

Very helpful and clear .Thank you Gradcoach.

Thank for sharing this article, well organized and information presented are very clear.

VERY INTERESTING AND SUPPORTIVE TO NEW RESEARCHERS LIKE ME. AT LEAST SOME BASICS ABOUT QUANTITATIVE.

An outstanding, well explained and helpful article. This will help me so much with my data analysis for my research project. Thank you!

wow this has just simplified everything i was scared of how i am gonna analyse my data but thanks to you i will be able to do so

simple and constant direction to research. thanks

This is helpful

Great writing!! Comprehensive and very helpful.

Do you provide any assistance for other steps of research methodology like making research problem testing hypothesis report and thesis writing?

Thank you so much for such useful article!

Amazing article. So nicely explained. Wow

Very insightfull. Thanks

I am doing a quality improvement project to determine if the implementation of a protocol will change prescribing habits. Would this be a t-test?

The is a very helpful blog, however, I’m still not sure how to analyze my data collected. I’m doing a research on “Free Education at the University of Guyana”

tnx. fruitful blog!

So I am writing exams and would like to know how do establish which method of data analysis to use from the below research questions: I am a bit lost as to how I determine the data analysis method from the research questions.
Do female employees report higher job satisfaction than male employees with similar job descriptions across the South African telecommunications sector? – I though that maybe Chi Square could be used here. – Is there a gender difference in talented employees’ actual turnover decisions across the South African telecommunications sector? T-tests or Correlation in this one. – Is there a gender difference in the cost of actual turnover decisions across the South African telecommunications sector? T-tests or Correlation in this one. – What practical recommendations can be made to the management of South African telecommunications companies on leveraging gender to mitigate employee turnover decisions?
Your assistance will be appreciated if I could get a response as early as possible tomorrow

This was quite helpful. Thank you so much.

wow I got a lot from this article, thank you very much, keep it up

Thanks for yhe guidance. Can you send me this guidance on my email? To enable offline reading?

Thank you very much, this service is very helpful.

Every novice researcher needs to read this article as it puts things so clear and easy to follow. Its been very helpful.

Wonderful!!!! you explained everything in a way that anyone can learn. Thank you!!

I really enjoyed reading though this. Very easy to follow. Thank you

Many thanks for your useful lecture, I would be really appreciated if you could possibly share with me the PPT of presentation related to Data type?

Thank you very much for sharing, I got much from this article

This is a very informative write-up. Kindly include me in your latest posts.

Very interesting mostly for social scientists

Thank you so much, very helpfull
You’re welcome 🙂

woow, its great, its very informative and well understood because of your way of writing like teaching in front of me in simple languages.

I have been struggling to understand a lot of these concepts. Thank you for the informative piece which is written with outstanding clarity.

very informative article. Easy to understand

Beautiful read, much needed.

Always greet intro and summary. I learn so much from GradCoach

Quite informative. Simple and clear summary.

I thoroughly enjoyed reading your informative and inspiring piece. Your profound insights into this topic truly provide a better understanding of its complexity. I agree with the points you raised, especially when you delved into the specifics of the article. In my opinion, that aspect is often overlooked and deserves further attention.

Absolutely!!! Thank you

Thank you very much for this post. It made me to understand how to do my data analysis.

its nice work and excellent job ,you have made my work easier
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- What Is Quantitative Research? | Definition & Methods
What Is Quantitative Research? | Definition & Methods
Published on 4 April 2022 by Pritha Bhandari . Revised on 10 October 2022.
Quantitative research is the process of collecting and analysing numerical data. It can be used to find patterns and averages, make predictions, test causal relationships, and generalise results to wider populations.
Quantitative research is the opposite of qualitative research , which involves collecting and analysing non-numerical data (e.g. text, video, or audio).
Quantitative research is widely used in the natural and social sciences: biology, chemistry, psychology, economics, sociology, marketing, etc.
- What is the demographic makeup of Singapore in 2020?
- How has the average temperature changed globally over the last century?
- Does environmental pollution affect the prevalence of honey bees?
- Does working from home increase productivity for people with long commutes?
Table of contents
Quantitative research methods, quantitative data analysis, advantages of quantitative research, disadvantages of quantitative research, frequently asked questions about quantitative research.
You can use quantitative research methods for descriptive, correlational or experimental research.
- In descriptive research , you simply seek an overall summary of your study variables.
- In correlational research , you investigate relationships between your study variables.
- In experimental research , you systematically examine whether there is a cause-and-effect relationship between variables.
Correlational and experimental research can both be used to formally test hypotheses , or predictions, using statistics. The results may be generalised to broader populations based on the sampling method used.
To collect quantitative data, you will often need to use operational definitions that translate abstract concepts (e.g., mood) into observable and quantifiable measures (e.g., self-ratings of feelings and energy levels).
Prevent plagiarism, run a free check.
Once data is collected, you may need to process it before it can be analysed. For example, survey and test data may need to be transformed from words to numbers. Then, you can use statistical analysis to answer your research questions .
Descriptive statistics will give you a summary of your data and include measures of averages and variability. You can also use graphs, scatter plots and frequency tables to visualise your data and check for any trends or outliers.
Using inferential statistics , you can make predictions or generalisations based on your data. You can test your hypothesis or use your sample data to estimate the population parameter .
You can also assess the reliability and validity of your data collection methods to indicate how consistently and accurately your methods actually measured what you wanted them to.
Quantitative research is often used to standardise data collection and generalise findings . Strengths of this approach include:
- Replication
Repeating the study is possible because of standardised data collection protocols and tangible definitions of abstract concepts.
- Direct comparisons of results
The study can be reproduced in other cultural settings, times or with different groups of participants. Results can be compared statistically.
- Large samples
Data from large samples can be processed and analysed using reliable and consistent procedures through quantitative data analysis.
- Hypothesis testing
Using formalised and established hypothesis testing procedures means that you have to carefully consider and report your research variables, predictions, data collection and testing methods before coming to a conclusion.
Despite the benefits of quantitative research, it is sometimes inadequate in explaining complex research topics. Its limitations include:
- Superficiality
Using precise and restrictive operational definitions may inadequately represent complex concepts. For example, the concept of mood may be represented with just a number in quantitative research, but explained with elaboration in qualitative research.
- Narrow focus
Predetermined variables and measurement procedures can mean that you ignore other relevant observations.
- Structural bias
Despite standardised procedures, structural biases can still affect quantitative research. Missing data , imprecise measurements or inappropriate sampling methods are biases that can lead to the wrong conclusions.
- Lack of context
Quantitative research often uses unnatural settings like laboratories or fails to consider historical and cultural contexts that may affect data collection and results.
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to test a hypothesis by systematically collecting and analysing data, while qualitative methods allow you to explore ideas and experiences in depth.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organisations.
Operationalisation means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioural avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalise the variables that you want to measure.
Reliability and validity are both about how well a method measures something:
- Reliability refers to the consistency of a measure (whether the results can be reproduced under the same conditions).
- Validity refers to the accuracy of a measure (whether the results really do represent what they are supposed to measure).
If you are doing experimental research , you also have to consider the internal and external validity of your experiment.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Bhandari, P. (2022, October 10). What Is Quantitative Research? | Definition & Methods. Scribbr. Retrieved 14 May 2024, from https://www.scribbr.co.uk/research-methods/introduction-to-quantitative-research/
Is this article helpful?

Pritha Bhandari

1 Introduction to Quantitative Analysis
Chris Bailey, PhD, CSCS, RSCC
Chapter Learning Objectives
- Understand the justification for quantitative analysis
- Learn how data and the scientific process can be used to inform decisions
- Learn and differentiate between some of the commonly used terminology in quantitative analysis
- Introduce the functions of quantitative analysis
- Introduce some of the technology used in quantitative analysis
Why is quantitative analysis important?
Let’s begin by answering the “who cares” question. When will you ever use any of this? As we will soon demonstrate, you likely already are, but it may not be the most objective method. Quantitative data are objective in nature, which is a benefit when we are trying to make decisions based on data without the influence of anything else. Much of what we will learn in quantitative analysis enables us to become more objective so that our individual experiences, traditions, and biases [1] cannot influence our decisions.
No matter what career path you are on, you will need to be able to justify your actions and decisions with data. Whether you are a sport performance professional, personal trainer, or physical therapist, you are likely tracking progression and using the data to influence your future plans for athletes, clients, or patients. Data from the individuals you work with may justify your current plan, or they could illustrate an area that needs to be adjusted to meet certain goals.
If we are not collecting data, we have to rely on our short memories and subjective feelings. These can be biased whether we realize it or not. For example as a physical therapist (PT), we want our rehabilitation plan to work, so we may only see and remember the positives and miss the negatives. If we had a set regimen of tests, we could look at it in a more objective way that is less likely to be influenced by our own biases.

Let’s look at an example of how you might use analysis on a regular basis. In this scenario, your cell phone is outdated, has a cracked screen, and takes terrible photos compared to currently available options. What factors would you consider when thinking about your new phone purchase?
Here are some ways you might approach your decision:
- Brand loyalty
- Read reviews
- Watch YouTube video reviews
- Check out your friend’s phone
First and most often foremost is price. What can you afford? You’ll need to research the different phones available and which are in your price range.
What about the type of phone you currently have? Does that play a role? Many cell phone users like to stick to the same operating system they are used to. For example, if you currently have an iPhone, you are probably more likely to stick with an iPhone for your next purchase as opposed to switching to an Android device. This is referred to as brand loyalty.
The next step might be to read reviews or watch video reviews on YouTube.
Finally, maybe you are jealous of the phone your friend just got. So you’ll just get the same one or the slightly newer version. Of course, you may come up with other factors that play a role in your decision-making process.
Each of these are ways of collecting data to influence your decision, even if you don’t realize you are collecting data. The decision-making process is likely a multi-factor process as we discussed. In kinesiology, we can answer questions in a similar way by creating methods of data collection to help us answer questions and make informed decisions.
A more kinesiology specific example
Let’s look at a more specific example in kinesiology, tracking physical activity…or lack thereof. What if we wanted to evaluate the physical inactivity of adults in the United States at the state level and examine if there are differences according to race or ethnicity? Fortunately, the United State Center for Disease Control (CDC) has compiled such data. According to the CDC, all states in the United States had more than 15% of adults that were considered physically inactive as of 2018 [2] .
Let’s break this down a little further, because this statistic is actually worse than it sounds and the results differ depending on race/ethnicity. The CDC defines physical inactivity as not participating in any physical activity during the past month (via self-report and excluding work-related activities). The actual range of physically inactive adults was from 17.3 – 47.7% in all states. There were 22 states that had greater than 25% of their population classified as physically inactive. Interestingly, these results differ slightly when race or ethnicity is considered. This study classified their sample into 3 groups: Hispanic adults, non-Hispanic black adults, and non-Hispanic white adults. Of the 3, those that would be considered minorities in the United States had higher percentages of physical inactivity. Hispanic adults expressed physical inactivity of 30% or greater in 22 states plus Puerto Rico, and 23 states plus Washington D.C. expressed physical inactivity of 30% or higher in non-Hispanic black adults. If we compare that data to non-Hispanic white adults, only 5 states plus Puerto Rico expressed physical inactivity of 30% or higher. [3]
In this example, we just used some data to answer a question about the prevalence of physical inactivity in the United States. But, we shouldn’t stop there. We should come up with some sort of practical application. A very simple one based on the data is that we should encourage more physical activity in the U.S. Said another way, we should discourage physical inactivity as the data suggests that there are many that are physically inactive. Looking a bit deeper at the results, we might suggest that health educators target their efforts in specific areas and populations since the results suggest that geographic and population disparities exist. This study did not evaluate why these disparities exist, but we should consider them in potential solutions.
While this may seem fairly straight forward, there are many other factors we need to consider in quantitative analysis. For example, do we know whether or not the data are valid and reliable? Do you know the difference between validity and reliability ? It’s okay if you don’t. As we will see later, many people confuse these two on a regular basis. What issues do you see with the data collection? Many may take issue with the data being acquired via self-report. We will discuss surveys/questionnaires later in this book, but they are a great way to reach a very wide and large sample of a population. Obviously, more objective methods (e.g. an accelerometer or pedometer) would be better, but when we have a very large sample, potential error is less of a concern since a greater proportion of the population is being measured.
Using Data and the Scientific Process to Inform
As we have just seen, data collected on a specific topic is used as information to help us understand more about that topic. This is a part of the scientific process of acquiring knowledge, sometimes referred to as the scientific method, which you’ve likely heard of before. While the scientific method was popularized in the 20th century, it’s development is often credited to Aristotle. [4] [5]

While the number of steps and their naming may differ depending on the source, they are often similar to Figure 1.1 shown above. First, one might wonder about a specific question based on an observation. Consider an example where Elise, an athletic trainer with a professional baseball team, notices that the majority of injuries and treatment times are highest each year during Spring Training [6] . Anecdotally , she observes that several of the injured players did not follow the off-season training program. She wonders if the sudden increase in workload plays a role. In this example, she is at the first step we described above.
Moving forward, she should examine previously published relevant research. In doing so, she notices there are quite a few studies in this area and many specifically look at the ratio of recent (acute) workloads to the accumulated (chronic) workloads and some have found higher risks of injury associated with higher levels of these ratios. [7] [8]
Now that she has enough information, she can finalize a hypothesis . Elise then hypothesizes that elevated ratios will increase the risk of injuries, but that the increased risk may differ from previous research because it wasn’t done on baseball players.
Now she is on to the experiment stage and she must design a way to test her hypothesis. So, she utilizes a smartphone application that helps athletes and coaches track their workloads during the off-season and during spring training. She also uses their injury data during Spring Training to see if those that incurred injuries during spring training had higher acute:chronic workload ratios compared to those that did not get injured. Spring Training is now over and she can now analyze the results. She finds that there is no statistical difference in acute:chronic workload ratios between the injured and non-injured groups.
Moving to the next stage she must draw conclusions based on the results found. The results did not support Elise’s hypothesis, so she cannot say that a sudden increase in workload increases risk of injury. But as she is contemplating this, she realizes that she did not take different injury types into consideration. Her sample included all athletes that were injured during Spring Training, which includes both ligament (for example, ulnar collateral ligament sprain), muscular (for example, hamstring strain), and tendon (for example, patellar tendon strain) injuries. She now recognizes that injury type may play a role in the relationship between workload accumulation and injury risk.
Now it’s time to report the results. This step may take different forms depending on your occupation. In Elise’s case, this may be a written report or a presentation to the team’s staff and front office executives. This could also be formally written up as a research paper and submitted for publication.
Hopefully you noticed that this step is also followed by an arrow that leads back to the first step. The scientific process is a cycle and we often finish the last step with more questions, which lead right back into more research. This was also the case with Elise’s example. She can now repeat the study and examine if injury type is important to her previous research question.
This text will focus on working with and analyzing data, but many of the other stages are dependent on this data. Also, the data analysis stage is dependent upon those that happened before it. Can you spot the data used in the example above? It primarily used workloads and injury status. If the data we need to answer a question aren’t available, we must find ways to collect it and that is what Elise did in the example above. There may be other times were the data are already available, but they aren’t recorded in the same source (table or spreadsheet), which means they need to be combined. Many times, the data are not recorded in an immediately usable format, so we may need to reorganize it (often referred to as data wrangling). Once we have the data in a usable format, we can then move onto analysis. Overwhelmingly, this text will focus on the analysis stage and all of the different techniques that can be used when appropriate. But how the other stages are influenced by the analysis stage and how the other stages influence it will also be addressed.
Terminology in Quantitative Analysis
There are many terms that are frequently used in statistical and quantitative analysis that are often confused and used interchangeably, but should not be. Many of which we may have already used, so now is a good time to begin defining some of our frequently used terms so that we avoid some confusion. Of course, we will have important terminology later on and we will define it when we encounter it.
- If we were to measure the body mass index (BMI) of all of the U.S. population, we would need to collect both the height and body mass of roughly 332.4 million people [9] .
- In the example above using the BMI of the entire U.S. population, the BMI would be a parameter.
- If we were to measure the BMI of only a sample of the U.S. population, we might randomly sample only 1% of the U.S. population (≈ 3.3 million people).
- In the example above using the BMI in a sample of the U.S. population, the BMI would be a statistic.
- A new device is created to evaluate your heart rate variability (HRV) via the camera sensors on your smart phone. To make sure it is actually measuring accurately, we might compare the new data to a well known and accepted standard way to measure HRV.
- In order to evaluate the between trial reliability of the newly created HRV device described above, we might collect data at 2 or 3 different times throughout the early morning to see how similar they are (or aren’t).
- Anecdotal : evidence that is collected by personal experiences and not in systematic manner. Most often considered of lower value in scientific occupations and may lead to error.
- Empirical : evidence that is collected and documented by systematic experimentation.
- Hypothesis : a research and scientific-based guess to answer a specific question or phenomenon.
- For example, we might compare jump performance results of one athlete to other athletes to say that he or she is a superior performer. Or we could use these results in a rehab setting to determine if our patient is progressing in their rehabilitation as they should, compared to data previous patients have produced at the same stage of recovery.
- For example measuring vertical jump performance likely results in a measure of jump height or vertical power.
- Following with the example above, we could use a jump and reach device, a switch mat, or a force plate to measure vertical jumping performance. Not all measurements in kinesiology are physical in nature, so these instruments may take other forms.
- Formative evaluation: Pretest, mid-test, or any evaluation prior to the final evaluation that helps to track changes in the quantity being measured.
- Summative evaluation: Final evaluation that helps to demonstrate achievement.

Examine the data plot above that shows a measurement of strength asymmetry as a percentage for an athlete returning from an ACL knee injury. Positive values indicate a left-side asymmetry and negative values indicate a right-side asymmetry. Can you guess which side was injured based on the initial data? This athlete had a right knee injury. Initially the athlete was roughly 17% stronger on the left side, which should have given you a clue to answer the previous question. Based on what we discussed in the previous 2 terms, would you say this data was created by formative or summative assessments?
Criterion-referencing : compares a performance to a specific preset requirement.
For example, passing a strength and conditioning, personal trainer, or other fitness related certification exam. Generally, these exams require test-takers to achieve a minimum score that represents mastery over the content. Some may even require that test takers achieve a specific score in many areas, not necessarily just the overall score. Either way, there may be a set score that represents the “criterion” necessary for certification, such as 70% or better. Some other criterion referenced standards based evaluation examples include: athletic training Board of Certification (BOC) exam, CPR exam, or a U.S. driver’s learners permit exam (this may vary by state).
Norm-referencing : compares performance(s) to the sample that the performer tested with or with a similar population.
Examples of norm-referenced standards include the interpretation of SAT, ACT, GRE, and IQ test scores. All of these may express results relative to those that take the exam. For example a score of 100 on the IQ (intelligence quotient) test represents the average score based on a normal distribution. We’ll learn about the normal distribution later, but this means that roughly 66.6% of test takers will score between 85 and 115. This is because all scores are transformed to make the current average score equal 100 with a standard deviation of 15 [10] . This means that a test-takers score might change based on the intelligence of the others that also take the exam in a similar time period. This also means that comparing the IQ of someone who took the exam today to someone who took the test 10 or more years ago is meaningless as a score of 135 may show that you are in the 99th percentile of your current time period. Furthermore, IQs have been shown substantially rise with time [11] . So, you could argue that an IQ of 100 as tested in 2020 is superior to the IQ of 100 in 2000.
Functions of Quantitative Analysis
Overall, it is required of us as professionals (or future professionals) in the field of kinesiology to make informed decisions, which often means using quantitative data. We can break this down further into several functions of quantitative analysis. Morrow and colleagues (2016) [12] recognize the following functions of quantitative analysis in Human Performance:
- Professionals may be able to group athletes, patients, or students following an evaluation of their abilities, which may help facilitate development. For example, an initial assessment may help a youth softball coach group athletes based on skill level and experience.
- The ability to predict future events may be the “Holy Grail” of many fields of research and business, but it requires large amounts of data that is often hard to come by (especially in sport performance). A very common example of this is the efforts and money spent on predicting injury in sports. Intuitively, the notion makes sense. If we can predict an injury, we should be able to prevent it. Currently, much of this research lies in the area of training loads and the rate at which an athlete increases them. [13] [14] [15]
- Many coaches and trainers set goals for their athletes and clients. Many physical therapists set goals for their patients. Many individuals set goals for themselves. Without doing this and measuring a specific quality, there will be no knowledge of improvement or progress.
- For many, scores on a specific test may provide motivation to perform better. This may be because they did not perform as well as they thought they should, they performed well and want to set another personal record, or they may be competing with other participants. As another example, consider a situation where you have been running a 5k every other week, but don’t know your time when you finish. Would you train harder if you did? What if you knew your overall placement amongst those who ran?
- Similar to achievement, programs themselves should be evaluated. Imagine you are a strength coach and you want to demonstrate that you are doing a great job developing your athletes. If your team is very successful on the field, court, or pitch, this may not be too much more difficult than pointing to your win-loss record. But what if your are working with a team that is very young and not yet performing to their full potential. This is precisely where demonstrating improvement in key areas that are related to competition performance could demonstrate your value to those that pay your salary.
Technology in Quantitative Analysis
Data storage and analysis.
There are many different types of technology that will be beneficial in analysis and several will be introduced in this text. Microsoft Excel and JASP will primarily be used here due to their availability and price tag (often $0), but there are many other software programs and technologies that may be useful in your future careers. Depending on the specific type of work you are doing, some programs may be better than others. Or, more than likely, you may end up using a combination of resources. Each resource has its own advantages and disadvantages. This text will make an effort to highlight those along with potential solutions for any issues.
As mentioned previously, attributes such as availability and cost are quite important for many when selecting statistical analysis software. Historically, SPSS from IBM has been the most widely used software, but that is changing. SPSS can do quite a lot, but carries a large price tag for those not affiliated with a university where they can get affordable access. Free and open source resources such as R are increasing in usage in published research as is Python in quantitative based job requirements. Meanwhile programs such as SPSS are declining in usage and desirability from potential employers. [17] [18] [19] There are many that still prefer the SPSS “point and click” style over learning coding syntax, so it will likely stick around. Many learn to use SPSS during their time as a student at a university that provides access. Once they graduate, however, they are confronted with the fact that they will need to pay for SPSS use which can be expensive (≅ $1,200/year as of 2021 [20] ). This pushes more users to options such as Excel or a coding-based solution like R and Python. JASP , a relatively new and free use product recently became available that has a similar user interface to SPSS, which many may prefer. For many of the reasons above, this text will focus on the usage of Excel and JASP. Each technique described in this text will include solutions in both programs, [21] so readers can follow the path they find most useful in their specific situations. Solution tutorials for Excel will be shown in green/teal boxes, while solutions in JASP will be shown in purple boxes (examples below).
Example MS Excel Solution Tutorial
All solutions in Excel will be in this color scheme and will have the word “Excel” somewhere in the title.
Example JASP Solution Tutorial
Data collection.
Along with data storage and analysis software, we might also be using technology in the data collection process. Take a look at the image below. Here we see an example of data collection happening in a boxing training session. Notice that the coach is viewing near real-time data on his tablet. How is this occurring? It’s not magic. In fact, many of you probably use this technological process daily. If you have a smart watch that is connected to your phone, it is continuously sending data via Bluetooth throughout the day. The same process is happening in the picture above. Each of the punching bags is instrumented with an accelerometer, which measures acceleration of the bag after it is hit, and is connected to the tablet via Bluetooth. This data is often automatically saved to a cloud storage account that can also be retrieved later. Many of our data collection instruments are now equipped with some form of telemetry (WiFi or Bluetooth) that can send the collected data directly to a storage site. Can you think of one besides your smart watch and the example on the screen?

Specifically concerning the field of kinesiology, the usage of technology and the digitization process of data has solved quite a few issues from the past. Previously, data had to be manually tabulated by hand and then transcribed into a computer for analysis. This could result in many errors when typing in the data that could negatively impact our results. Now, much of our data collection involves equipment that automatically collects the digital data for us and often saves it in the cloud. Many patient and athlete management systems utilize these methods to track progress and performance.
Actually, we could go back a couple of decades before this, when much of the analysis was also done by hand. Thankfully, we won’t have to worry about that. We can now utilize computers and software to run the analysis for us and we rarely have to recall any formulas.
Beyond directly collecting data, computers and technology can be used to collect data in other ways. Public data can be taken from websites and other sources digitally from a process known as ”web-scraping.” This can be done in MS Excel, but is more often done with coding languages such as R or Python that can more precisely pull and then reformat the data into a usable format. There are also many freely available and open databases that we can use for research purposes. Many sports organizations and leagues produce these. Many data and sport scientists are trained to retrieve and analyze much of these types data on a regular basis.
Data Tables and Spreadsheets
While data tables and spreadsheets are terms that are often used interchangeably, the are not the same thing. A data table is simply a way to organize data into rows and columns, where each intersection of a row and column is a cell and this may also be referred to as a data set. Many who use MS Excel, Google Sheets, or Apple’s Numbers may refer to this as a spreadsheet, but this is technically incorrect as spreadsheets also allow for formatting and manipulation of the data in each cell. A simple spreadsheet can be used as a data table or it may include a data table. Spreadsheet software incorporates many of the analysis processes into the same spot, which can be a benefit depending on the complexity of your analyses. If you want to go further than some of the more basic analyses, you may not be able to complete the job with products such as MS Excel. This creates a potential issue for those who have stored their data in the standard .xlsx or .xls formats in MS Excel, as many other programs cannot import the data. Fortunately, MS Excel provides many options for saving your files as different extensions that are more usable in other programs. Currently, most common among these is the .csv file extension which stands for comma separated values. If you were to open this file in a text editor, you would literally see a list of all the data with each cell separated by a comma. Unfortunately, the .csv format will not save any of the equations one might use to manipulate data, any plots, or formatting. So it is a good idea to save the data tables created in Excel as a .csv file, but also to save any analysis files in the standard format (.xlsx).
Data Table Organization
No matter what software you use to store your data, it is always a good idea to standardize the organization. While you may like a specific format at one point in time, it’s important to remember that in needs to make sense to everyone who views it and other programs may not recognize it if it’s not organized in a traditional manner. That being said, there are some best practices to organizing our data. Within a data table or dataset, we have 3 main pieces: variables, observations, and values.
- Variables are a specific attribute being measured. These are generally set up as columns.
- Observations are all measures on specific entities (for example, a name or date). These are generally set up as rows.
- Values are the intersections of our variables and observations. You would consider this an individual cell in a spreadsheet. Each value is one specific measure of an attribute for a specific date or individual.
Consider the table below in Figure 1.4 that depicts some objective and subjective data on exercise intensity collected at exhaustion in a graded treadmill test. Notice that each column is a variable. So we have 3 variables, which include the subject ID, % HRmax, and RPE. We also have several observations shown as rows. Each subject has 1 ID number, 1 % HRmax value, and 1 RPE value. Speaking of values, a specific value for a given variable and observation can be found at their intersection. For example, if we want to know what subject 314159’s RPE value is we must find where they intersect. The observation is shaded in red, the variable is shaded in blue, and the value (intersection) of 17 is shaded in purple for emphasis.

An Important Caveat for MS Excel/Spreadsheet Users
Consider a sample of 200 university students that were enrolled in a study measuring resting heart rates during finals week. How many rows should there be? If all 200 were tested once, we should have 200 rows. One caveat to that is if you are working in MS Excel or a similar spreadsheet application, the first row is often used to name your variables. So, row 1 wouldn’t contain any data yet. This would mean you would technically have 201 rows if you had 200 observations and your first row of data would be row 2. For other programs, variable names may be included separately and the type of data will also need to be selected. Data types will be discussed in the next chapter.
When logging data for use in an analysis program, it can be perfectly straightforward for many variables like weight or height (in cm). You just type in the value. But what about gender or class? Can you just type that in as a word? Most often you can’t. Many of the analysis programs do not know how to deal with strings or words. So you might code that as a number. For example, a value of 1 might refer to freshmen, 2 might refer to sophomore, and so on. This will be discussed this further later on when segmenting data into groups is desired.
Enabling the Data Analysis Toolpak in MS Excel
Excel can handle many of the same analysis that other statistical programs can, although it’s not always as easy as the other programs. But, it is much more available than those programs, so there are tradeoffs. In order to be able to run many of these types of analysis, you will need to enable the “ Data Analysis Toolpak ” as that is not automatically available. Please refer to the Microsoft support page in order to do this, which has step by step instructions for PCs and Macs.
Enable the Data Analysis Toolpak for MS Excel
Installing JASP
If you choose to utilize a true statistical analysis software, JASP is a good option. It is free and has easy solutions for nearly all types of analyses. JASP can be installed on PC, Mac, and Linux operating systems.
Download and Install JASP
- Bias means that we lean more towards a specific notion and it is often thought of in a negative light. From a statistical perspective, the motivation for why we think a certain way does not matter. It can be negative or positive. All that matters is that our biases could result in beliefs that are not consistent with what the data actually tell us. For example, we might think very highly of a specific person we are testing and therefore give them a slightly better score than if we did not know that person at all. This type of bias may not be considered negative in motivation, but it is negative in that we are potentially misleading ourselves and others. Whether or not we like to admit it, we all have biases and relying on quantitative data to justify our decisions may help us to avoid them or avoid making decision because of them. ↵
- 2020. Adult Physical Inactivity Prevalence Maps by Race/Ethnicity . https://www.cdc.gov/physicalactivity/data/inactivity-prevalence-maps/index.html ↵
- If you would like to take a more granular look at this data, please visit https://www.cdc.gov/physicalactivity/data/inactivity-prevalence-maps/index.html . ↵
- Riccardo Pozzo (2004) The impact of Aristotelianism on modern philosophy. CUA Press. p. 41. ↵
- https://en.wikipedia.org/wiki/Scientific_method ↵
- https://en.wikipedia.org/wiki/Spring_training ↵
- Bowen L, Gross AS, Gimpel M, Bruce-Low S, Li FX. Spikes in acute:chronic workload ratio (ACWR) associated with a 5-7 times greater injury rate in English Premier League football players: a comprehensive 3-year study. Br J Sports Med. 2020 Jun;54(12):731-738. doi: 10.1136/bjsports-2018-099422. Epub 2019 Feb 21. PMID: 30792258; PMCID: PMC7285788. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7285788/ ↵
- Bowen L, Gross AS, Gimpel M, Li FX. Accumulated workloads and the acute:chronic workload ratio relate to injury risk in elite youth football players. Br J Sports Med. 2017 Mar;51(5):452-459. doi: 10.1136/bjsports-2015-095820. Epub 2016 Jul 22. PMID: 27450360; PMCID: PMC5460663. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5460663/ ↵
- Current US Population as checked in 2021. https://www.census.gov/popclock/ ↵
- https://en.wikipedia.org/wiki/Intelligence_quotient#Precursors_to_IQ_testing ↵
- Flynn Effect. https://en.wikipedia.org/wiki/Flynn_effect ↵
- Morrow, J., Mood, D., Disch, J., and Kang, M. 2016. Measurement and Evaluation in Human Performance. Human Kinetics. Champaign, IL. ↵
- Gabbett TJ. The training-injury prevention paradox: should athletes be training smarter and harder? Br J Sports Med. 2016 Mar;50(5):273-80. doi: 10.1136/bjsports-2015-095788. Epub 2016 Jan 12. PMID: 26758673; PMCID: PMC4789704. ↵
- Bourdon PC, Cardinale M, Murray A, Gastin P, Kellmann M, Varley MC, Gabbett TJ, Coutts AJ, Burgess DJ, Gregson W, Cable NT. Monitoring Athlete Training Loads: Consensus Statement. Int J Sports Physiol Perform. 2017 Apr;12(Suppl 2):S2161-S2170. doi: 10.1123/IJSPP.2017-0208. PMID: 28463642. ↵
- Eckard TG, Padua DA, Hearn DW, Pexa BS, Frank BS. The Relationship Between Training Load and Injury in Athletes: A Systematic Review. Sports Med. 2018 Aug;48(8):1929-1961. doi: 10.1007/s40279-018-0951-z. Erratum in: Sports Med. 2020 Jun;50(6):1223. PMID: 29943231. ↵
- Morrow et al. (2016) also include Diagnosis as a function of quantitative analysis, but that is not included here as most professionals in human performance and kinesiology do not possess the the authority to diagnose. They may be asked to perform a test and those result may help diagnose an issue, but diagnosis is generally reserved to those practicing medicine. ↵
- http://r4stats.com/2014/08/20/r-passes-spss-in-scholarly-use-stata-growing-rapidly/ ↵
- http://r4stats.com/2019/04/01/scholarly-datasci-popularity-2019/ ↵
- https://lindeloev.net/spss-is-dying/ ↵
- https://www.ibm.com/products/spss-statistics/pricing ↵
- When possible. There are some instances when MS Excel does not have the capability to run the same analyses as JASP. ↵
- Wickham, H. (2014). Tidy Data. Journal of Statistical Software. https://www.jstatsoft.org/article/view/v059i10/ ↵
how well scores represent the variable they are supposed to; or how well the measurement measures what it is supposed to.
refers to the consistency of data. Often includes various types: test-retest (across time), between raters (interrater), within rater (intrarater), or internal consistency (across items).
evidence that is collected by personal experiences and not in systematic manner. Most often considered of lower value in scientific occupations.
a research and scientific-based guess to answer a specific question or phenomenon
includes every single member of a specific group
Variable of interest measured in the population
a subset of the population that should generally be representative of that population. Samples are often used when collecting data on the entire population is unrealistic.
Variable of interest measured in the sample
evidence that is collected and documented by systematic experimentation
a statement about quality that generally is decided upon after comparing other observations.
quantification of a specific quality being assessed.
a tool used to measure a specific quality
Pretest, mid-test, or any evaluation prior to the final evaluation that helps to track changes in the quantity being measured.
Final evaluation that helps to demonstrate achievement.
compares a performance to a specific preset requirement.
compares performance(s) to the sample that the performer tested with or with a similar population.
Quantitative Analysis in Exercise and Sport Science by Chris Bailey, PhD, CSCS, RSCC is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License , except where otherwise noted.
Share This Book
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Data Analysis in Research: Types & Methods

Content Index
Why analyze data in research?
Types of data in research, finding patterns in the qualitative data, methods used for data analysis in qualitative research, preparing data for analysis, methods used for data analysis in quantitative research, considerations in research data analysis, what is data analysis in research.
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense.
Three essential things occur during the data analysis process — the first is data organization . Summarization and categorization together contribute to becoming the second known method used for data reduction. It helps find patterns and themes in the data for easy identification and linking. The third and last way is data analysis – researchers do it in both top-down and bottom-up fashion.
LEARN ABOUT: Research Process Steps
On the other hand, Marshall and Rossman describe data analysis as a messy, ambiguous, and time-consuming but creative and fascinating process through which a mass of collected data is brought to order, structure and meaning.
We can say that “the data analysis and data interpretation is a process representing the application of deductive and inductive logic to the research and data analysis.”
Researchers rely heavily on data as they have a story to tell or research problems to solve. It starts with a question, and data is nothing but an answer to that question. But, what if there is no question to ask? Well! It is possible to explore data even without a problem – we call it ‘Data Mining’, which often reveals some interesting patterns within the data that are worth exploring.
Irrelevant to the type of data researchers explore, their mission and audiences’ vision guide them to find the patterns to shape the story they want to tell. One of the essential things expected from researchers while analyzing data is to stay open and remain unbiased toward unexpected patterns, expressions, and results. Remember, sometimes, data analysis tells the most unforeseen yet exciting stories that were not expected when initiating data analysis. Therefore, rely on the data you have at hand and enjoy the journey of exploratory research.
Create a Free Account
Every kind of data has a rare quality of describing things after assigning a specific value to it. For analysis, you need to organize these values, processed and presented in a given context, to make it useful. Data can be in different forms; here are the primary data types.
- Qualitative data: When the data presented has words and descriptions, then we call it qualitative data . Although you can observe this data, it is subjective and harder to analyze data in research, especially for comparison. Example: Quality data represents everything describing taste, experience, texture, or an opinion that is considered quality data. This type of data is usually collected through focus groups, personal qualitative interviews , qualitative observation or using open-ended questions in surveys.
- Quantitative data: Any data expressed in numbers of numerical figures are called quantitative data . This type of data can be distinguished into categories, grouped, measured, calculated, or ranked. Example: questions such as age, rank, cost, length, weight, scores, etc. everything comes under this type of data. You can present such data in graphical format, charts, or apply statistical analysis methods to this data. The (Outcomes Measurement Systems) OMS questionnaires in surveys are a significant source of collecting numeric data.
- Categorical data: It is data presented in groups. However, an item included in the categorical data cannot belong to more than one group. Example: A person responding to a survey by telling his living style, marital status, smoking habit, or drinking habit comes under the categorical data. A chi-square test is a standard method used to analyze this data.
Learn More : Examples of Qualitative Data in Education
Data analysis in qualitative research
Data analysis and qualitative data research work a little differently from the numerical data as the quality data is made up of words, descriptions, images, objects, and sometimes symbols. Getting insight from such complicated information is a complicated process. Hence it is typically used for exploratory research and data analysis .
Although there are several ways to find patterns in the textual information, a word-based method is the most relied and widely used global technique for research and data analysis. Notably, the data analysis process in qualitative research is manual. Here the researchers usually read the available data and find repetitive or commonly used words.
For example, while studying data collected from African countries to understand the most pressing issues people face, researchers might find “food” and “hunger” are the most commonly used words and will highlight them for further analysis.
LEARN ABOUT: Level of Analysis
The keyword context is another widely used word-based technique. In this method, the researcher tries to understand the concept by analyzing the context in which the participants use a particular keyword.
For example , researchers conducting research and data analysis for studying the concept of ‘diabetes’ amongst respondents might analyze the context of when and how the respondent has used or referred to the word ‘diabetes.’
The scrutiny-based technique is also one of the highly recommended text analysis methods used to identify a quality data pattern. Compare and contrast is the widely used method under this technique to differentiate how a specific text is similar or different from each other.
For example: To find out the “importance of resident doctor in a company,” the collected data is divided into people who think it is necessary to hire a resident doctor and those who think it is unnecessary. Compare and contrast is the best method that can be used to analyze the polls having single-answer questions types .
Metaphors can be used to reduce the data pile and find patterns in it so that it becomes easier to connect data with theory.
Variable Partitioning is another technique used to split variables so that researchers can find more coherent descriptions and explanations from the enormous data.
LEARN ABOUT: Qualitative Research Questions and Questionnaires
There are several techniques to analyze the data in qualitative research, but here are some commonly used methods,
- Content Analysis: It is widely accepted and the most frequently employed technique for data analysis in research methodology. It can be used to analyze the documented information from text, images, and sometimes from the physical items. It depends on the research questions to predict when and where to use this method.
- Narrative Analysis: This method is used to analyze content gathered from various sources such as personal interviews, field observation, and surveys . The majority of times, stories, or opinions shared by people are focused on finding answers to the research questions.
- Discourse Analysis: Similar to narrative analysis, discourse analysis is used to analyze the interactions with people. Nevertheless, this particular method considers the social context under which or within which the communication between the researcher and respondent takes place. In addition to that, discourse analysis also focuses on the lifestyle and day-to-day environment while deriving any conclusion.
- Grounded Theory: When you want to explain why a particular phenomenon happened, then using grounded theory for analyzing quality data is the best resort. Grounded theory is applied to study data about the host of similar cases occurring in different settings. When researchers are using this method, they might alter explanations or produce new ones until they arrive at some conclusion.
LEARN ABOUT: 12 Best Tools for Researchers
Data analysis in quantitative research
The first stage in research and data analysis is to make it for the analysis so that the nominal data can be converted into something meaningful. Data preparation consists of the below phases.
Phase I: Data Validation
Data validation is done to understand if the collected data sample is per the pre-set standards, or it is a biased data sample again divided into four different stages
- Fraud: To ensure an actual human being records each response to the survey or the questionnaire
- Screening: To make sure each participant or respondent is selected or chosen in compliance with the research criteria
- Procedure: To ensure ethical standards were maintained while collecting the data sample
- Completeness: To ensure that the respondent has answered all the questions in an online survey. Else, the interviewer had asked all the questions devised in the questionnaire.
Phase II: Data Editing
More often, an extensive research data sample comes loaded with errors. Respondents sometimes fill in some fields incorrectly or sometimes skip them accidentally. Data editing is a process wherein the researchers have to confirm that the provided data is free of such errors. They need to conduct necessary checks and outlier checks to edit the raw edit and make it ready for analysis.
Phase III: Data Coding
Out of all three, this is the most critical phase of data preparation associated with grouping and assigning values to the survey responses . If a survey is completed with a 1000 sample size, the researcher will create an age bracket to distinguish the respondents based on their age. Thus, it becomes easier to analyze small data buckets rather than deal with the massive data pile.
LEARN ABOUT: Steps in Qualitative Research
After the data is prepared for analysis, researchers are open to using different research and data analysis methods to derive meaningful insights. For sure, statistical analysis plans are the most favored to analyze numerical data. In statistical analysis, distinguishing between categorical data and numerical data is essential, as categorical data involves distinct categories or labels, while numerical data consists of measurable quantities. The method is again classified into two groups. First, ‘Descriptive Statistics’ used to describe data. Second, ‘Inferential statistics’ that helps in comparing the data .
Descriptive statistics
This method is used to describe the basic features of versatile types of data in research. It presents the data in such a meaningful way that pattern in the data starts making sense. Nevertheless, the descriptive analysis does not go beyond making conclusions. The conclusions are again based on the hypothesis researchers have formulated so far. Here are a few major types of descriptive analysis methods.
Measures of Frequency
- Count, Percent, Frequency
- It is used to denote home often a particular event occurs.
- Researchers use it when they want to showcase how often a response is given.
Measures of Central Tendency
- Mean, Median, Mode
- The method is widely used to demonstrate distribution by various points.
- Researchers use this method when they want to showcase the most commonly or averagely indicated response.
Measures of Dispersion or Variation
- Range, Variance, Standard deviation
- Here the field equals high/low points.
- Variance standard deviation = difference between the observed score and mean
- It is used to identify the spread of scores by stating intervals.
- Researchers use this method to showcase data spread out. It helps them identify the depth until which the data is spread out that it directly affects the mean.
Measures of Position
- Percentile ranks, Quartile ranks
- It relies on standardized scores helping researchers to identify the relationship between different scores.
- It is often used when researchers want to compare scores with the average count.
For quantitative research use of descriptive analysis often give absolute numbers, but the in-depth analysis is never sufficient to demonstrate the rationale behind those numbers. Nevertheless, it is necessary to think of the best method for research and data analysis suiting your survey questionnaire and what story researchers want to tell. For example, the mean is the best way to demonstrate the students’ average scores in schools. It is better to rely on the descriptive statistics when the researchers intend to keep the research or outcome limited to the provided sample without generalizing it. For example, when you want to compare average voting done in two different cities, differential statistics are enough.
Descriptive analysis is also called a ‘univariate analysis’ since it is commonly used to analyze a single variable.
Inferential statistics
Inferential statistics are used to make predictions about a larger population after research and data analysis of the representing population’s collected sample. For example, you can ask some odd 100 audiences at a movie theater if they like the movie they are watching. Researchers then use inferential statistics on the collected sample to reason that about 80-90% of people like the movie.
Here are two significant areas of inferential statistics.
- Estimating parameters: It takes statistics from the sample research data and demonstrates something about the population parameter.
- Hypothesis test: I t’s about sampling research data to answer the survey research questions. For example, researchers might be interested to understand if the new shade of lipstick recently launched is good or not, or if the multivitamin capsules help children to perform better at games.
These are sophisticated analysis methods used to showcase the relationship between different variables instead of describing a single variable. It is often used when researchers want something beyond absolute numbers to understand the relationship between variables.
Here are some of the commonly used methods for data analysis in research.
- Correlation: When researchers are not conducting experimental research or quasi-experimental research wherein the researchers are interested to understand the relationship between two or more variables, they opt for correlational research methods.
- Cross-tabulation: Also called contingency tables, cross-tabulation is used to analyze the relationship between multiple variables. Suppose provided data has age and gender categories presented in rows and columns. A two-dimensional cross-tabulation helps for seamless data analysis and research by showing the number of males and females in each age category.
- Regression analysis: For understanding the strong relationship between two variables, researchers do not look beyond the primary and commonly used regression analysis method, which is also a type of predictive analysis used. In this method, you have an essential factor called the dependent variable. You also have multiple independent variables in regression analysis. You undertake efforts to find out the impact of independent variables on the dependent variable. The values of both independent and dependent variables are assumed as being ascertained in an error-free random manner.
- Frequency tables: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Analysis of variance: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Researchers must have the necessary research skills to analyze and manipulation the data , Getting trained to demonstrate a high standard of research practice. Ideally, researchers must possess more than a basic understanding of the rationale of selecting one statistical method over the other to obtain better data insights.
- Usually, research and data analytics projects differ by scientific discipline; therefore, getting statistical advice at the beginning of analysis helps design a survey questionnaire, select data collection methods , and choose samples.
LEARN ABOUT: Best Data Collection Tools
- The primary aim of data research and analysis is to derive ultimate insights that are unbiased. Any mistake in or keeping a biased mind to collect data, selecting an analysis method, or choosing audience sample il to draw a biased inference.
- Irrelevant to the sophistication used in research data and analysis is enough to rectify the poorly defined objective outcome measurements. It does not matter if the design is at fault or intentions are not clear, but lack of clarity might mislead readers, so avoid the practice.
- The motive behind data analysis in research is to present accurate and reliable data. As far as possible, avoid statistical errors, and find a way to deal with everyday challenges like outliers, missing data, data altering, data mining , or developing graphical representation.
LEARN MORE: Descriptive Research vs Correlational Research The sheer amount of data generated daily is frightening. Especially when data analysis has taken center stage. in 2018. In last year, the total data supply amounted to 2.8 trillion gigabytes. Hence, it is clear that the enterprises willing to survive in the hypercompetitive world must possess an excellent capability to analyze complex research data, derive actionable insights, and adapt to the new market needs.
LEARN ABOUT: Average Order Value
QuestionPro is an online survey platform that empowers organizations in data analysis and research and provides them a medium to collect data by creating appealing surveys.
MORE LIKE THIS

Data Information vs Insight: Essential differences
May 14, 2024

Pricing Analytics Software: Optimize Your Pricing Strategy
May 13, 2024

Relationship Marketing: What It Is, Examples & Top 7 Benefits
May 8, 2024

The Best Email Survey Tool to Boost Your Feedback Game
May 7, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
- Privacy Policy
Home » Quantitative Research – Methods, Types and Analysis
Quantitative Research – Methods, Types and Analysis
Table of Contents

Quantitative Research
Quantitative research is a type of research that collects and analyzes numerical data to test hypotheses and answer research questions . This research typically involves a large sample size and uses statistical analysis to make inferences about a population based on the data collected. It often involves the use of surveys, experiments, or other structured data collection methods to gather quantitative data.
Quantitative Research Methods

Quantitative Research Methods are as follows:
Descriptive Research Design
Descriptive research design is used to describe the characteristics of a population or phenomenon being studied. This research method is used to answer the questions of what, where, when, and how. Descriptive research designs use a variety of methods such as observation, case studies, and surveys to collect data. The data is then analyzed using statistical tools to identify patterns and relationships.
Correlational Research Design
Correlational research design is used to investigate the relationship between two or more variables. Researchers use correlational research to determine whether a relationship exists between variables and to what extent they are related. This research method involves collecting data from a sample and analyzing it using statistical tools such as correlation coefficients.
Quasi-experimental Research Design
Quasi-experimental research design is used to investigate cause-and-effect relationships between variables. This research method is similar to experimental research design, but it lacks full control over the independent variable. Researchers use quasi-experimental research designs when it is not feasible or ethical to manipulate the independent variable.
Experimental Research Design
Experimental research design is used to investigate cause-and-effect relationships between variables. This research method involves manipulating the independent variable and observing the effects on the dependent variable. Researchers use experimental research designs to test hypotheses and establish cause-and-effect relationships.
Survey Research
Survey research involves collecting data from a sample of individuals using a standardized questionnaire. This research method is used to gather information on attitudes, beliefs, and behaviors of individuals. Researchers use survey research to collect data quickly and efficiently from a large sample size. Survey research can be conducted through various methods such as online, phone, mail, or in-person interviews.
Quantitative Research Analysis Methods
Here are some commonly used quantitative research analysis methods:
Statistical Analysis
Statistical analysis is the most common quantitative research analysis method. It involves using statistical tools and techniques to analyze the numerical data collected during the research process. Statistical analysis can be used to identify patterns, trends, and relationships between variables, and to test hypotheses and theories.
Regression Analysis
Regression analysis is a statistical technique used to analyze the relationship between one dependent variable and one or more independent variables. Researchers use regression analysis to identify and quantify the impact of independent variables on the dependent variable.
Factor Analysis
Factor analysis is a statistical technique used to identify underlying factors that explain the correlations among a set of variables. Researchers use factor analysis to reduce a large number of variables to a smaller set of factors that capture the most important information.
Structural Equation Modeling
Structural equation modeling is a statistical technique used to test complex relationships between variables. It involves specifying a model that includes both observed and unobserved variables, and then using statistical methods to test the fit of the model to the data.
Time Series Analysis
Time series analysis is a statistical technique used to analyze data that is collected over time. It involves identifying patterns and trends in the data, as well as any seasonal or cyclical variations.
Multilevel Modeling
Multilevel modeling is a statistical technique used to analyze data that is nested within multiple levels. For example, researchers might use multilevel modeling to analyze data that is collected from individuals who are nested within groups, such as students nested within schools.
Applications of Quantitative Research
Quantitative research has many applications across a wide range of fields. Here are some common examples:
- Market Research : Quantitative research is used extensively in market research to understand consumer behavior, preferences, and trends. Researchers use surveys, experiments, and other quantitative methods to collect data that can inform marketing strategies, product development, and pricing decisions.
- Health Research: Quantitative research is used in health research to study the effectiveness of medical treatments, identify risk factors for diseases, and track health outcomes over time. Researchers use statistical methods to analyze data from clinical trials, surveys, and other sources to inform medical practice and policy.
- Social Science Research: Quantitative research is used in social science research to study human behavior, attitudes, and social structures. Researchers use surveys, experiments, and other quantitative methods to collect data that can inform social policies, educational programs, and community interventions.
- Education Research: Quantitative research is used in education research to study the effectiveness of teaching methods, assess student learning outcomes, and identify factors that influence student success. Researchers use experimental and quasi-experimental designs, as well as surveys and other quantitative methods, to collect and analyze data.
- Environmental Research: Quantitative research is used in environmental research to study the impact of human activities on the environment, assess the effectiveness of conservation strategies, and identify ways to reduce environmental risks. Researchers use statistical methods to analyze data from field studies, experiments, and other sources.
Characteristics of Quantitative Research
Here are some key characteristics of quantitative research:
- Numerical data : Quantitative research involves collecting numerical data through standardized methods such as surveys, experiments, and observational studies. This data is analyzed using statistical methods to identify patterns and relationships.
- Large sample size: Quantitative research often involves collecting data from a large sample of individuals or groups in order to increase the reliability and generalizability of the findings.
- Objective approach: Quantitative research aims to be objective and impartial in its approach, focusing on the collection and analysis of data rather than personal beliefs, opinions, or experiences.
- Control over variables: Quantitative research often involves manipulating variables to test hypotheses and establish cause-and-effect relationships. Researchers aim to control for extraneous variables that may impact the results.
- Replicable : Quantitative research aims to be replicable, meaning that other researchers should be able to conduct similar studies and obtain similar results using the same methods.
- Statistical analysis: Quantitative research involves using statistical tools and techniques to analyze the numerical data collected during the research process. Statistical analysis allows researchers to identify patterns, trends, and relationships between variables, and to test hypotheses and theories.
- Generalizability: Quantitative research aims to produce findings that can be generalized to larger populations beyond the specific sample studied. This is achieved through the use of random sampling methods and statistical inference.
Examples of Quantitative Research
Here are some examples of quantitative research in different fields:
- Market Research: A company conducts a survey of 1000 consumers to determine their brand awareness and preferences. The data is analyzed using statistical methods to identify trends and patterns that can inform marketing strategies.
- Health Research : A researcher conducts a randomized controlled trial to test the effectiveness of a new drug for treating a particular medical condition. The study involves collecting data from a large sample of patients and analyzing the results using statistical methods.
- Social Science Research : A sociologist conducts a survey of 500 people to study attitudes toward immigration in a particular country. The data is analyzed using statistical methods to identify factors that influence these attitudes.
- Education Research: A researcher conducts an experiment to compare the effectiveness of two different teaching methods for improving student learning outcomes. The study involves randomly assigning students to different groups and collecting data on their performance on standardized tests.
- Environmental Research : A team of researchers conduct a study to investigate the impact of climate change on the distribution and abundance of a particular species of plant or animal. The study involves collecting data on environmental factors and population sizes over time and analyzing the results using statistical methods.
- Psychology : A researcher conducts a survey of 500 college students to investigate the relationship between social media use and mental health. The data is analyzed using statistical methods to identify correlations and potential causal relationships.
- Political Science: A team of researchers conducts a study to investigate voter behavior during an election. They use survey methods to collect data on voting patterns, demographics, and political attitudes, and analyze the results using statistical methods.
How to Conduct Quantitative Research
Here is a general overview of how to conduct quantitative research:
- Develop a research question: The first step in conducting quantitative research is to develop a clear and specific research question. This question should be based on a gap in existing knowledge, and should be answerable using quantitative methods.
- Develop a research design: Once you have a research question, you will need to develop a research design. This involves deciding on the appropriate methods to collect data, such as surveys, experiments, or observational studies. You will also need to determine the appropriate sample size, data collection instruments, and data analysis techniques.
- Collect data: The next step is to collect data. This may involve administering surveys or questionnaires, conducting experiments, or gathering data from existing sources. It is important to use standardized methods to ensure that the data is reliable and valid.
- Analyze data : Once the data has been collected, it is time to analyze it. This involves using statistical methods to identify patterns, trends, and relationships between variables. Common statistical techniques include correlation analysis, regression analysis, and hypothesis testing.
- Interpret results: After analyzing the data, you will need to interpret the results. This involves identifying the key findings, determining their significance, and drawing conclusions based on the data.
- Communicate findings: Finally, you will need to communicate your findings. This may involve writing a research report, presenting at a conference, or publishing in a peer-reviewed journal. It is important to clearly communicate the research question, methods, results, and conclusions to ensure that others can understand and replicate your research.
When to use Quantitative Research
Here are some situations when quantitative research can be appropriate:
- To test a hypothesis: Quantitative research is often used to test a hypothesis or a theory. It involves collecting numerical data and using statistical analysis to determine if the data supports or refutes the hypothesis.
- To generalize findings: If you want to generalize the findings of your study to a larger population, quantitative research can be useful. This is because it allows you to collect numerical data from a representative sample of the population and use statistical analysis to make inferences about the population as a whole.
- To measure relationships between variables: If you want to measure the relationship between two or more variables, such as the relationship between age and income, or between education level and job satisfaction, quantitative research can be useful. It allows you to collect numerical data on both variables and use statistical analysis to determine the strength and direction of the relationship.
- To identify patterns or trends: Quantitative research can be useful for identifying patterns or trends in data. For example, you can use quantitative research to identify trends in consumer behavior or to identify patterns in stock market data.
- To quantify attitudes or opinions : If you want to measure attitudes or opinions on a particular topic, quantitative research can be useful. It allows you to collect numerical data using surveys or questionnaires and analyze the data using statistical methods to determine the prevalence of certain attitudes or opinions.
Purpose of Quantitative Research
The purpose of quantitative research is to systematically investigate and measure the relationships between variables or phenomena using numerical data and statistical analysis. The main objectives of quantitative research include:
- Description : To provide a detailed and accurate description of a particular phenomenon or population.
- Explanation : To explain the reasons for the occurrence of a particular phenomenon, such as identifying the factors that influence a behavior or attitude.
- Prediction : To predict future trends or behaviors based on past patterns and relationships between variables.
- Control : To identify the best strategies for controlling or influencing a particular outcome or behavior.
Quantitative research is used in many different fields, including social sciences, business, engineering, and health sciences. It can be used to investigate a wide range of phenomena, from human behavior and attitudes to physical and biological processes. The purpose of quantitative research is to provide reliable and valid data that can be used to inform decision-making and improve understanding of the world around us.
Advantages of Quantitative Research
There are several advantages of quantitative research, including:
- Objectivity : Quantitative research is based on objective data and statistical analysis, which reduces the potential for bias or subjectivity in the research process.
- Reproducibility : Because quantitative research involves standardized methods and measurements, it is more likely to be reproducible and reliable.
- Generalizability : Quantitative research allows for generalizations to be made about a population based on a representative sample, which can inform decision-making and policy development.
- Precision : Quantitative research allows for precise measurement and analysis of data, which can provide a more accurate understanding of phenomena and relationships between variables.
- Efficiency : Quantitative research can be conducted relatively quickly and efficiently, especially when compared to qualitative research, which may involve lengthy data collection and analysis.
- Large sample sizes : Quantitative research can accommodate large sample sizes, which can increase the representativeness and generalizability of the results.
Limitations of Quantitative Research
There are several limitations of quantitative research, including:
- Limited understanding of context: Quantitative research typically focuses on numerical data and statistical analysis, which may not provide a comprehensive understanding of the context or underlying factors that influence a phenomenon.
- Simplification of complex phenomena: Quantitative research often involves simplifying complex phenomena into measurable variables, which may not capture the full complexity of the phenomenon being studied.
- Potential for researcher bias: Although quantitative research aims to be objective, there is still the potential for researcher bias in areas such as sampling, data collection, and data analysis.
- Limited ability to explore new ideas: Quantitative research is often based on pre-determined research questions and hypotheses, which may limit the ability to explore new ideas or unexpected findings.
- Limited ability to capture subjective experiences : Quantitative research is typically focused on objective data and may not capture the subjective experiences of individuals or groups being studied.
- Ethical concerns : Quantitative research may raise ethical concerns, such as invasion of privacy or the potential for harm to participants.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Questionnaire – Definition, Types, and Examples

Case Study – Methods, Examples and Guide

Observational Research – Methods and Guide

Qualitative Research Methods

Explanatory Research – Types, Methods, Guide

Survey Research – Types, Methods, Examples

Quantitative Data Analysis
In quantitative data analysis you are expected to turn raw numbers into meaningful data through the application of rational and critical thinking. Quantitative data analysis may include the calculation of frequencies of variables and differences between variables. A quantitative approach is usually associated with finding evidence to either support or reject hypotheses you have formulated at the earlier stages of your research process .
The same figure within data set can be interpreted in many different ways; therefore it is important to apply fair and careful judgement.
For example, questionnaire findings of a research titled “A study into the impacts of informal management-employee communication on the levels of employee motivation: a case study of Agro Bravo Enterprise” may indicate that the majority 52% of respondents assess communication skills of their immediate supervisors as inadequate.
This specific piece of primary data findings needs to be critically analyzed and objectively interpreted through comparing it to other findings within the framework of the same research. For example, organizational culture of Agro Bravo Enterprise, leadership style, the levels of frequency of management-employee communications need to be taken into account during the data analysis.
Moreover, literature review findings conducted at the earlier stages of the research process need to be referred to in order to reflect the viewpoints of other authors regarding the causes of employee dissatisfaction with management communication. Also, secondary data needs to be integrated in data analysis in a logical and unbiased manner.
Let’s take another example. You are writing a dissertation exploring the impacts of foreign direct investment (FDI) on the levels of economic growth in Vietnam using correlation quantitative data analysis method . You have specified FDI and GDP as variables for your research and correlation tests produced correlation coefficient of 0.9.
In this case simply stating that there is a strong positive correlation between FDI and GDP would not suffice; you have to provide explanation about the manners in which the growth on the levels of FDI may contribute to the growth of GDP by referring to the findings of the literature review and applying your own critical and rational reasoning skills.
A set of analytical software can be used to assist with analysis of quantitative data. The following table illustrates the advantages and disadvantages of three popular quantitative data analysis software: Microsoft Excel, Microsoft Access and SPSS.
Advantages and disadvantages of popular quantitative analytical software
Quantitative data analysis with the application of statistical software consists of the following stages [1] :
- Preparing and checking the data. Input of data into computer.
- Selecting the most appropriate tables and diagrams to use according to your research objectives.
- Selecting the most appropriate statistics to describe your data.
- Selecting the most appropriate statistics to examine relationships and trends in your data.
It is important to note that while the application of various statistical software and programs are invaluable to avoid drawing charts by hand or undertake calculations manually, it is easy to use them incorrectly. In other words, quantitative data analysis is “a field where it is not at all difficult to carry out an analysis which is simply wrong, or inappropriate for your data or purposes. And the negative side of readily available specialist statistical software is that it becomes that much easier to generate elegantly presented rubbish” [2] .
Therefore, it is important for you to seek advice from your dissertation supervisor regarding statistical analyses in general and the choice and application of statistical software in particular.
My e-book, The Ultimate Guide to Writing a Dissertation in Business Studies: a step by step approach contains a detailed, yet simple explanation of quantitative data analysis methods . The e-book explains all stages of the research process starting from the selection of the research area to writing personal reflection. Important elements of dissertations such as research philosophy, research approach, research design, methods of data collection and data analysis are explained in simple words. John Dudovskiy

[1] Saunders, M., Lewis, P. & Thornhill, A. (2012) “Research Methods for Business Students” 6th edition, Pearson Education Limited.
[2] Robson, C. (2011) Real World Research: A Resource for Users of Social Research Methods in Applied Settings (3rd edn). Chichester: John Wiley.
Qualitative vs Quantitative Research Methods & Data Analysis
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
What is the difference between quantitative and qualitative?
The main difference between quantitative and qualitative research is the type of data they collect and analyze.
Quantitative research collects numerical data and analyzes it using statistical methods. The aim is to produce objective, empirical data that can be measured and expressed in numerical terms. Quantitative research is often used to test hypotheses, identify patterns, and make predictions.
Qualitative research , on the other hand, collects non-numerical data such as words, images, and sounds. The focus is on exploring subjective experiences, opinions, and attitudes, often through observation and interviews.
Qualitative research aims to produce rich and detailed descriptions of the phenomenon being studied, and to uncover new insights and meanings.
Quantitative data is information about quantities, and therefore numbers, and qualitative data is descriptive, and regards phenomenon which can be observed but not measured, such as language.
What Is Qualitative Research?
Qualitative research is the process of collecting, analyzing, and interpreting non-numerical data, such as language. Qualitative research can be used to understand how an individual subjectively perceives and gives meaning to their social reality.
Qualitative data is non-numerical data, such as text, video, photographs, or audio recordings. This type of data can be collected using diary accounts or in-depth interviews and analyzed using grounded theory or thematic analysis.
Qualitative research is multimethod in focus, involving an interpretive, naturalistic approach to its subject matter. This means that qualitative researchers study things in their natural settings, attempting to make sense of, or interpret, phenomena in terms of the meanings people bring to them. Denzin and Lincoln (1994, p. 2)
Interest in qualitative data came about as the result of the dissatisfaction of some psychologists (e.g., Carl Rogers) with the scientific study of psychologists such as behaviorists (e.g., Skinner ).
Since psychologists study people, the traditional approach to science is not seen as an appropriate way of carrying out research since it fails to capture the totality of human experience and the essence of being human. Exploring participants’ experiences is known as a phenomenological approach (re: Humanism ).
Qualitative research is primarily concerned with meaning, subjectivity, and lived experience. The goal is to understand the quality and texture of people’s experiences, how they make sense of them, and the implications for their lives.
Qualitative research aims to understand the social reality of individuals, groups, and cultures as nearly as possible as participants feel or live it. Thus, people and groups are studied in their natural setting.
Some examples of qualitative research questions are provided, such as what an experience feels like, how people talk about something, how they make sense of an experience, and how events unfold for people.
Research following a qualitative approach is exploratory and seeks to explain ‘how’ and ‘why’ a particular phenomenon, or behavior, operates as it does in a particular context. It can be used to generate hypotheses and theories from the data.
Qualitative Methods
There are different types of qualitative research methods, including diary accounts, in-depth interviews , documents, focus groups , case study research , and ethnography.
The results of qualitative methods provide a deep understanding of how people perceive their social realities and in consequence, how they act within the social world.
The researcher has several methods for collecting empirical materials, ranging from the interview to direct observation, to the analysis of artifacts, documents, and cultural records, to the use of visual materials or personal experience. Denzin and Lincoln (1994, p. 14)
Here are some examples of qualitative data:
Interview transcripts : Verbatim records of what participants said during an interview or focus group. They allow researchers to identify common themes and patterns, and draw conclusions based on the data. Interview transcripts can also be useful in providing direct quotes and examples to support research findings.
Observations : The researcher typically takes detailed notes on what they observe, including any contextual information, nonverbal cues, or other relevant details. The resulting observational data can be analyzed to gain insights into social phenomena, such as human behavior, social interactions, and cultural practices.
Unstructured interviews : generate qualitative data through the use of open questions. This allows the respondent to talk in some depth, choosing their own words. This helps the researcher develop a real sense of a person’s understanding of a situation.
Diaries or journals : Written accounts of personal experiences or reflections.
Notice that qualitative data could be much more than just words or text. Photographs, videos, sound recordings, and so on, can be considered qualitative data. Visual data can be used to understand behaviors, environments, and social interactions.
Qualitative Data Analysis
Qualitative research is endlessly creative and interpretive. The researcher does not just leave the field with mountains of empirical data and then easily write up his or her findings.
Qualitative interpretations are constructed, and various techniques can be used to make sense of the data, such as content analysis, grounded theory (Glaser & Strauss, 1967), thematic analysis (Braun & Clarke, 2006), or discourse analysis.
For example, thematic analysis is a qualitative approach that involves identifying implicit or explicit ideas within the data. Themes will often emerge once the data has been coded .

Key Features
- Events can be understood adequately only if they are seen in context. Therefore, a qualitative researcher immerses her/himself in the field, in natural surroundings. The contexts of inquiry are not contrived; they are natural. Nothing is predefined or taken for granted.
- Qualitative researchers want those who are studied to speak for themselves, to provide their perspectives in words and other actions. Therefore, qualitative research is an interactive process in which the persons studied teach the researcher about their lives.
- The qualitative researcher is an integral part of the data; without the active participation of the researcher, no data exists.
- The study’s design evolves during the research and can be adjusted or changed as it progresses. For the qualitative researcher, there is no single reality. It is subjective and exists only in reference to the observer.
- The theory is data-driven and emerges as part of the research process, evolving from the data as they are collected.
Limitations of Qualitative Research
- Because of the time and costs involved, qualitative designs do not generally draw samples from large-scale data sets.
- The problem of adequate validity or reliability is a major criticism. Because of the subjective nature of qualitative data and its origin in single contexts, it is difficult to apply conventional standards of reliability and validity. For example, because of the central role played by the researcher in the generation of data, it is not possible to replicate qualitative studies.
- Also, contexts, situations, events, conditions, and interactions cannot be replicated to any extent, nor can generalizations be made to a wider context than the one studied with confidence.
- The time required for data collection, analysis, and interpretation is lengthy. Analysis of qualitative data is difficult, and expert knowledge of an area is necessary to interpret qualitative data. Great care must be taken when doing so, for example, looking for mental illness symptoms.
Advantages of Qualitative Research
- Because of close researcher involvement, the researcher gains an insider’s view of the field. This allows the researcher to find issues that are often missed (such as subtleties and complexities) by the scientific, more positivistic inquiries.
- Qualitative descriptions can be important in suggesting possible relationships, causes, effects, and dynamic processes.
- Qualitative analysis allows for ambiguities/contradictions in the data, which reflect social reality (Denscombe, 2010).
- Qualitative research uses a descriptive, narrative style; this research might be of particular benefit to the practitioner as she or he could turn to qualitative reports to examine forms of knowledge that might otherwise be unavailable, thereby gaining new insight.
What Is Quantitative Research?
Quantitative research involves the process of objectively collecting and analyzing numerical data to describe, predict, or control variables of interest.
The goals of quantitative research are to test causal relationships between variables , make predictions, and generalize results to wider populations.
Quantitative researchers aim to establish general laws of behavior and phenomenon across different settings/contexts. Research is used to test a theory and ultimately support or reject it.
Quantitative Methods
Experiments typically yield quantitative data, as they are concerned with measuring things. However, other research methods, such as controlled observations and questionnaires , can produce both quantitative information.
For example, a rating scale or closed questions on a questionnaire would generate quantitative data as these produce either numerical data or data that can be put into categories (e.g., “yes,” “no” answers).
Experimental methods limit how research participants react to and express appropriate social behavior.
Findings are, therefore, likely to be context-bound and simply a reflection of the assumptions that the researcher brings to the investigation.
There are numerous examples of quantitative data in psychological research, including mental health. Here are a few examples:
Another example is the Experience in Close Relationships Scale (ECR), a self-report questionnaire widely used to assess adult attachment styles .
The ECR provides quantitative data that can be used to assess attachment styles and predict relationship outcomes.
Neuroimaging data : Neuroimaging techniques, such as MRI and fMRI, provide quantitative data on brain structure and function.
This data can be analyzed to identify brain regions involved in specific mental processes or disorders.
For example, the Beck Depression Inventory (BDI) is a clinician-administered questionnaire widely used to assess the severity of depressive symptoms in individuals.
The BDI consists of 21 questions, each scored on a scale of 0 to 3, with higher scores indicating more severe depressive symptoms.
Quantitative Data Analysis
Statistics help us turn quantitative data into useful information to help with decision-making. We can use statistics to summarize our data, describing patterns, relationships, and connections. Statistics can be descriptive or inferential.
Descriptive statistics help us to summarize our data. In contrast, inferential statistics are used to identify statistically significant differences between groups of data (such as intervention and control groups in a randomized control study).
- Quantitative researchers try to control extraneous variables by conducting their studies in the lab.
- The research aims for objectivity (i.e., without bias) and is separated from the data.
- The design of the study is determined before it begins.
- For the quantitative researcher, the reality is objective, exists separately from the researcher, and can be seen by anyone.
- Research is used to test a theory and ultimately support or reject it.
Limitations of Quantitative Research
- Context: Quantitative experiments do not take place in natural settings. In addition, they do not allow participants to explain their choices or the meaning of the questions they may have for those participants (Carr, 1994).
- Researcher expertise: Poor knowledge of the application of statistical analysis may negatively affect analysis and subsequent interpretation (Black, 1999).
- Variability of data quantity: Large sample sizes are needed for more accurate analysis. Small-scale quantitative studies may be less reliable because of the low quantity of data (Denscombe, 2010). This also affects the ability to generalize study findings to wider populations.
- Confirmation bias: The researcher might miss observing phenomena because of focus on theory or hypothesis testing rather than on the theory of hypothesis generation.
Advantages of Quantitative Research
- Scientific objectivity: Quantitative data can be interpreted with statistical analysis, and since statistics are based on the principles of mathematics, the quantitative approach is viewed as scientifically objective and rational (Carr, 1994; Denscombe, 2010).
- Useful for testing and validating already constructed theories.
- Rapid analysis: Sophisticated software removes much of the need for prolonged data analysis, especially with large volumes of data involved (Antonius, 2003).
- Replication: Quantitative data is based on measured values and can be checked by others because numerical data is less open to ambiguities of interpretation.
- Hypotheses can also be tested because of statistical analysis (Antonius, 2003).
Antonius, R. (2003). Interpreting quantitative data with SPSS . Sage.
Black, T. R. (1999). Doing quantitative research in the social sciences: An integrated approach to research design, measurement and statistics . Sage.
Braun, V. & Clarke, V. (2006). Using thematic analysis in psychology . Qualitative Research in Psychology , 3, 77–101.
Carr, L. T. (1994). The strengths and weaknesses of quantitative and qualitative research : what method for nursing? Journal of advanced nursing, 20(4) , 716-721.
Denscombe, M. (2010). The Good Research Guide: for small-scale social research. McGraw Hill.
Denzin, N., & Lincoln. Y. (1994). Handbook of Qualitative Research. Thousand Oaks, CA, US: Sage Publications Inc.
Glaser, B. G., Strauss, A. L., & Strutzel, E. (1968). The discovery of grounded theory; strategies for qualitative research. Nursing research, 17(4) , 364.
Minichiello, V. (1990). In-Depth Interviewing: Researching People. Longman Cheshire.
Punch, K. (1998). Introduction to Social Research: Quantitative and Qualitative Approaches. London: Sage
Further Information
- Designing qualitative research
- Methods of data collection and analysis
- Introduction to quantitative and qualitative research
- Checklists for improving rigour in qualitative research: a case of the tail wagging the dog?
- Qualitative research in health care: Analysing qualitative data
- Qualitative data analysis: the framework approach
- Using the framework method for the analysis of
- Qualitative data in multi-disciplinary health research
- Content Analysis
- Grounded Theory
- Thematic Analysis
Related Articles

Research Methodology
Qualitative Data Coding

What Is a Focus Group?

Cross-Cultural Research Methodology In Psychology

What Is Internal Validity In Research?

Research Methodology , Statistics
What Is Face Validity In Research? Importance & How To Measure

Criterion Validity: Definition & Examples
Research Writing and Analysis
- NVivo Group and Study Sessions
- SPSS This link opens in a new window
- Statistical Analysis Group sessions
- Using Qualtrics
- Dissertation and Data Analysis Group Sessions
- Defense Schedule - Commons Calendar This link opens in a new window
- Research Process Flow Chart
- Research Alignment Chapter 1 This link opens in a new window
- Step 1: Seek Out Evidence
- Step 2: Explain
- Step 3: The Big Picture
- Step 4: Own It
- Step 5: Illustrate
- Annotated Bibliography
- Literature Review This link opens in a new window
- Systematic Reviews & Meta-Analyses
- How to Synthesize and Analyze
- Synthesis and Analysis Practice
- Synthesis and Analysis Group Sessions
- Problem Statement
- Purpose Statement
- Conceptual Framework
- Theoretical Framework
- Quantitative Research Questions
- Qualitative Research Questions
- Trustworthiness of Qualitative Data
- Analysis and Coding Example- Qualitative Data
- Thematic Data Analysis in Qualitative Design
- Dissertation to Journal Article This link opens in a new window
- International Journal of Online Graduate Education (IJOGE) This link opens in a new window
- Journal of Research in Innovative Teaching & Learning (JRIT&L) This link opens in a new window
Jump to DSE Guide
Purpose statement overview.
The purpose statement succinctly explains (on no more than 1 page) the objectives of the research study. These objectives must directly address the problem and help close the stated gap. Expressed as a formula:

Good purpose statements:
- Flow from the problem statement and actually address the proposed problem
- Are concise and clear
- Answer the question ‘Why are you doing this research?’
- Match the methodology (similar to research questions)
- Have a ‘hook’ to get the reader’s attention
- Set the stage by clearly stating, “The purpose of this (qualitative or quantitative) study is to ...
In PhD studies, the purpose usually involves applying a theory to solve the problem. In other words, the purpose tells the reader what the goal of the study is, and what your study will accomplish, through which theoretical lens. The purpose statement also includes brief information about direction, scope, and where the data will come from.
A problem and gap in combination can lead to different research objectives, and hence, different purpose statements. In the example from above where the problem was severe underrepresentation of female CEOs in Fortune 500 companies and the identified gap related to lack of research of male-dominated boards; one purpose might be to explore implicit biases in male-dominated boards through the lens of feminist theory. Another purpose may be to determine how board members rated female and male candidates on scales of competency, professionalism, and experience to predict which candidate will be selected for the CEO position. The first purpose may involve a qualitative ethnographic study in which the researcher observes board meetings and hiring interviews; the second may involve a quantitative regression analysis. The outcomes will be very different, so it’s important that you find out exactly how you want to address a problem and help close a gap!
The purpose of the study must not only align with the problem and address a gap; it must also align with the chosen research method. In fact, the DP/DM template requires you to name the research method at the very beginning of the purpose statement. The research verb must match the chosen method. In general, quantitative studies involve “closed-ended” research verbs such as determine , measure , correlate , explain , compare , validate , identify , or examine ; whereas qualitative studies involve “open-ended” research verbs such as explore , understand , narrate , articulate [meanings], discover , or develop .
A qualitative purpose statement following the color-coded problem statement (assumed here to be low well-being among financial sector employees) + gap (lack of research on followers of mid-level managers), might start like this:
In response to declining levels of employee well-being, the purpose of the qualitative phenomenology was to explore and understand the lived experiences related to the well-being of the followers of novice mid-level managers in the financial services industry. The levels of follower well-being have been shown to correlate to employee morale, turnover intention, and customer orientation (Eren et al., 2013). A combined framework of Leader-Member Exchange (LMX) Theory and the employee well-being concept informed the research questions and supported the inquiry, analysis, and interpretation of the experiences of followers of novice managers in the financial services industry.
A quantitative purpose statement for the same problem and gap might start like this:
In response to declining levels of employee well-being, the purpose of the quantitative correlational study was to determine which leadership factors predict employee well-being of the followers of novice mid-level managers in the financial services industry. Leadership factors were measured by the Leader-Member Exchange (LMX) assessment framework by Mantlekow (2015), and employee well-being was conceptualized as a compound variable consisting of self-reported turnover-intent and psychological test scores from the Mental Health Survey (MHS) developed by Johns Hopkins University researchers.
Both of these purpose statements reflect viable research strategies and both align with the problem and gap so it’s up to the researcher to design a study in a manner that reflects personal preferences and desired study outcomes. Note that the quantitative research purpose incorporates operationalized concepts or variables ; that reflect the way the researcher intends to measure the key concepts under study; whereas the qualitative purpose statement isn’t about translating the concepts under study as variables but instead aim to explore and understand the core research phenomenon.
Best Practices for Writing your Purpose Statement
Always keep in mind that the dissertation process is iterative, and your writing, over time, will be refined as clarity is gradually achieved. Most of the time, greater clarity for the purpose statement and other components of the Dissertation is the result of a growing understanding of the literature in the field. As you increasingly master the literature you will also increasingly clarify the purpose of your study.
The purpose statement should flow directly from the problem statement. There should be clear and obvious alignment between the two and that alignment will get tighter and more pronounced as your work progresses.
The purpose statement should specifically address the reason for conducting the study, with emphasis on the word specifically. There should not be any doubt in your readers’ minds as to the purpose of your study. To achieve this level of clarity you will need to also insure there is no doubt in your mind as to the purpose of your study.
Many researchers benefit from stopping your work during the research process when insight strikes you and write about it while it is still fresh in your mind. This can help you clarify all aspects of a dissertation, including clarifying its purpose.
Your Chair and your committee members can help you to clarify your study’s purpose so carefully attend to any feedback they offer.
The purpose statement should reflect the research questions and vice versa. The chain of alignment that began with the research problem description and continues on to the research purpose, research questions, and methodology must be respected at all times during dissertation development. You are to succinctly describe the overarching goal of the study that reflects the research questions. Each research question narrows and focuses the purpose statement. Conversely, the purpose statement encompasses all of the research questions.
Identify in the purpose statement the research method as quantitative, qualitative or mixed (i.e., “The purpose of this [qualitative/quantitative/mixed] study is to ...)
Avoid the use of the phrase “research study” since the two words together are redundant.
Follow the initial declaration of purpose with a brief overview of how, with what instruments/data, with whom and where (as applicable) the study will be conducted. Identify variables/constructs and/or phenomenon/concept/idea. Since this section is to be a concise paragraph, emphasis must be placed on the word brief. However, adding these details will give your readers a very clear picture of the purpose of your research.
Developing the purpose section of your dissertation is usually not achieved in a single flash of insight. The process involves a great deal of reading to find out what other scholars have done to address the research topic and problem you have identified. The purpose section of your dissertation could well be the most important paragraph you write during your academic career, and every word should be carefully selected. Think of it as the DNA of your dissertation. Everything else you write should emerge directly and clearly from your purpose statement. In turn, your purpose statement should emerge directly and clearly from your research problem description. It is good practice to print out your problem statement and purpose statement and keep them in front of you as you work on each part of your dissertation in order to insure alignment.
It is helpful to collect several dissertations similar to the one you envision creating. Extract the problem descriptions and purpose statements of other dissertation authors and compare them in order to sharpen your thinking about your own work. Comparing how other dissertation authors have handled the many challenges you are facing can be an invaluable exercise. Keep in mind that individual universities use their own tailored protocols for presenting key components of the dissertation so your review of these purpose statements should focus on content rather than form.
Once your purpose statement is set it must be consistently presented throughout the dissertation. This may require some recursive editing because the way you articulate your purpose may evolve as you work on various aspects of your dissertation. Whenever you make an adjustment to your purpose statement you should carefully follow up on the editing and conceptual ramifications throughout the entire document.
In establishing your purpose you should NOT advocate for a particular outcome. Research should be done to answer questions not prove a point. As a researcher, you are to inquire with an open mind, and even when you come to the work with clear assumptions, your job is to prove the validity of the conclusions reached. For example, you would not say the purpose of your research project is to demonstrate that there is a relationship between two variables. Such a statement presupposes you know the answer before your research is conducted and promotes or supports (advocates on behalf of) a particular outcome. A more appropriate purpose statement would be to examine or explore the relationship between two variables.
Your purpose statement should not imply that you are going to prove something. You may be surprised to learn that we cannot prove anything in scholarly research for two reasons. First, in quantitative analyses, statistical tests calculate the probability that something is true rather than establishing it as true. Second, in qualitative research, the study can only purport to describe what is occurring from the perspective of the participants. Whether or not the phenomenon they are describing is true in a larger context is not knowable. We cannot observe the phenomenon in all settings and in all circumstances.
Writing your Purpose Statement
It is important to distinguish in your mind the differences between the Problem Statement and Purpose Statement.
The Problem Statement is why I am doing the research
The Purpose Statement is what type of research I am doing to fit or address the problem
The Purpose Statement includes:
- Method of Study
- Specific Population
Remember, as you are contemplating what to include in your purpose statement and then when you are writing it, the purpose statement is a concise paragraph that describes the intent of the study, and it should flow directly from the problem statement. It should specifically address the reason for conducting the study, and reflect the research questions. Further, it should identify the research method as qualitative, quantitative, or mixed. Then provide a brief overview of how the study will be conducted, with what instruments/data collection methods, and with whom (subjects) and where (as applicable). Finally, you should identify variables/constructs and/or phenomenon/concept/idea.
Qualitative Purpose Statement
Creswell (2002) suggested for writing purpose statements in qualitative research include using deliberate phrasing to alert the reader to the purpose statement. Verbs that indicate what will take place in the research and the use of non-directional language that do not suggest an outcome are key. A purpose statement should focus on a single idea or concept, with a broad definition of the idea or concept. How the concept was investigated should also be included, as well as participants in the study and locations for the research to give the reader a sense of with whom and where the study took place.
Creswell (2003) advised the following script for purpose statements in qualitative research:
“The purpose of this qualitative_________________ (strategy of inquiry, such as ethnography, case study, or other type) study is (was? will be?) to ________________ (understand? describe? develop? discover?) the _________________(central phenomenon being studied) for ______________ (the participants, such as the individual, groups, organization) at __________(research site). At this stage in the research, the __________ (central phenomenon being studied) will be generally defined as ___________________ (provide a general definition)” (pg. 90).
Quantitative Purpose Statement
Creswell (2003) offers vast differences between the purpose statements written for qualitative research and those written for quantitative research, particularly with respect to language and the inclusion of variables. The comparison of variables is often a focus of quantitative research, with the variables distinguishable by either the temporal order or how they are measured. As with qualitative research purpose statements, Creswell (2003) recommends the use of deliberate language to alert the reader to the purpose of the study, but quantitative purpose statements also include the theory or conceptual framework guiding the study and the variables that are being studied and how they are related.
Creswell (2003) suggests the following script for drafting purpose statements in quantitative research:
“The purpose of this _____________________ (experiment? survey?) study is (was? will be?) to test the theory of _________________that _________________ (compares? relates?) the ___________(independent variable) to _________________________(dependent variable), controlling for _______________________ (control variables) for ___________________ (participants) at _________________________ (the research site). The independent variable(s) _____________________ will be generally defined as _______________________ (provide a general definition). The dependent variable(s) will be generally defined as _____________________ (provide a general definition), and the control and intervening variables(s), _________________ (identify the control and intervening variables) will be statistically controlled in this study” (pg. 97).
Sample Purpose Statements
- The purpose of this qualitative study was to determine how participation in service-learning in an alternative school impacted students academically, civically, and personally. There is ample evidence demonstrating the failure of schools for students at-risk; however, there is still a need to demonstrate why these students are successful in non-traditional educational programs like the service-learning model used at TDS. This study was unique in that it examined one alternative school’s approach to service-learning in a setting where students not only serve, but faculty serve as volunteer teachers. The use of a constructivist approach in service-learning in an alternative school setting was examined in an effort to determine whether service-learning participation contributes positively to academic, personal, and civic gain for students, and to examine student and teacher views regarding the overall outcomes of service-learning. This study was completed using an ethnographic approach that included observations, content analysis, and interviews with teachers at The David School.
- The purpose of this quantitative non-experimental cross-sectional linear multiple regression design was to investigate the relationship among early childhood teachers’ self-reported assessment of multicultural awareness as measured by responses from the Teacher Multicultural Attitude Survey (TMAS) and supervisors’ observed assessment of teachers’ multicultural competency skills as measured by the Multicultural Teaching Competency Scale (MTCS) survey. Demographic data such as number of multicultural training hours, years teaching in Dubai, curriculum program at current school, and age were also examined and their relationship to multicultural teaching competency. The study took place in the emirate of Dubai where there were 14,333 expatriate teachers employed in private schools (KHDA, 2013b).
- The purpose of this quantitative, non-experimental study is to examine the degree to which stages of change, gender, acculturation level and trauma types predicts the reluctance of Arab refugees, aged 18 and over, in the Dearborn, MI area, to seek professional help for their mental health needs. This study will utilize four instruments to measure these variables: University of Rhode Island Change Assessment (URICA: DiClemente & Hughes, 1990); Cumulative Trauma Scale (Kira, 2012); Acculturation Rating Scale for Arabic Americans-II Arabic and English (ARSAA-IIA, ARSAA-IIE: Jadalla & Lee, 2013), and a demographic survey. This study will examine 1) the relationship between stages of change, gender, acculturation levels, and trauma types and Arab refugees’ help-seeking behavior, 2) the degree to which any of these variables can predict Arab refugee help-seeking behavior. Additionally, the outcome of this study could provide researchers and clinicians with a stage-based model, TTM, for measuring Arab refugees’ help-seeking behavior and lay a foundation for how TTM can help target the clinical needs of Arab refugees. Lastly, this attempt to apply the TTM model to Arab refugees’ condition could lay the foundation for future research to investigate the application of TTM to clinical work among refugee populations.
- The purpose of this qualitative, phenomenological study is to describe the lived experiences of LLM for 10 EFL learners in rural Guatemala and to utilize that data to determine how it conforms to, or possibly challenges, current theoretical conceptions of LLM. In accordance with Morse’s (1994) suggestion that a phenomenological study should utilize at least six participants, this study utilized semi-structured interviews with 10 EFL learners to explore why and how they have experienced the motivation to learn English throughout their lives. The methodology of horizontalization was used to break the interview protocols into individual units of meaning before analyzing these units to extract the overarching themes (Moustakas, 1994). These themes were then interpreted into a detailed description of LLM as experienced by EFL students in this context. Finally, the resulting description was analyzed to discover how these learners’ lived experiences with LLM conformed with and/or diverged from current theories of LLM.
- The purpose of this qualitative, embedded, multiple case study was to examine how both parent-child attachment relationships are impacted by the quality of the paternal and maternal caregiver-child interactions that occur throughout a maternal deployment, within the context of dual-military couples. In order to examine this phenomenon, an embedded, multiple case study was conducted, utilizing an attachment systems metatheory perspective. The study included four dual-military couples who experienced a maternal deployment to Operation Iraqi Freedom (OIF) or Operation Enduring Freedom (OEF) when they had at least one child between 8 weeks-old to 5 years-old. Each member of the couple participated in an individual, semi-structured interview with the researcher and completed the Parenting Relationship Questionnaire (PRQ). “The PRQ is designed to capture a parent’s perspective on the parent-child relationship” (Pearson, 2012, para. 1) and was used within the proposed study for this purpose. The PRQ was utilized to triangulate the data (Bekhet & Zauszniewski, 2012) as well as to provide some additional information on the parents’ perspective of the quality of the parent-child attachment relationship in regards to communication, discipline, parenting confidence, relationship satisfaction, and time spent together (Pearson, 2012). The researcher utilized the semi-structured interview to collect information regarding the parents' perspectives of the quality of their parental caregiver behaviors during the deployment cycle, the mother's parent-child interactions while deployed, the behavior of the child or children at time of reunification, and the strategies or behaviors the parents believe may have contributed to their child's behavior at the time of reunification. The results of this study may be utilized by the military, and by civilian providers, to develop proactive and preventive measures that both providers and parents can implement, to address any potential adverse effects on the parent-child attachment relationship, identified through the proposed study. The results of this study may also be utilized to further refine and understand the integration of attachment theory and systems theory, in both clinical and research settings, within the field of marriage and family therapy.
Was this resource helpful?
- << Previous: Problem Statement
- Next: Conceptual Framework >>
- Last Updated: May 16, 2024 8:25 AM
- URL: https://resources.nu.edu/researchtools

- Introduction
- Conclusions
- Article Information
DDS-17 indicates Diabetes Distress Scale–17; HbA 1c , glycated hemoglobin A 1c .
Trial Protocol and Statistical Analysis Plan
Data Sharing Statement
See More About
Sign up for emails based on your interests, select your interests.
Customize your JAMA Network experience by selecting one or more topics from the list below.
- Academic Medicine
- Acid Base, Electrolytes, Fluids
- Allergy and Clinical Immunology
- American Indian or Alaska Natives
- Anesthesiology
- Anticoagulation
- Art and Images in Psychiatry
- Artificial Intelligence
- Assisted Reproduction
- Bleeding and Transfusion
- Caring for the Critically Ill Patient
- Challenges in Clinical Electrocardiography
- Climate and Health
- Climate Change
- Clinical Challenge
- Clinical Decision Support
- Clinical Implications of Basic Neuroscience
- Clinical Pharmacy and Pharmacology
- Complementary and Alternative Medicine
- Consensus Statements
- Coronavirus (COVID-19)
- Critical Care Medicine
- Cultural Competency
- Dental Medicine
- Dermatology
- Diabetes and Endocrinology
- Diagnostic Test Interpretation
- Drug Development
- Electronic Health Records
- Emergency Medicine
- End of Life, Hospice, Palliative Care
- Environmental Health
- Equity, Diversity, and Inclusion
- Facial Plastic Surgery
- Gastroenterology and Hepatology
- Genetics and Genomics
- Genomics and Precision Health
- Global Health
- Guide to Statistics and Methods
- Hair Disorders
- Health Care Delivery Models
- Health Care Economics, Insurance, Payment
- Health Care Quality
- Health Care Reform
- Health Care Safety
- Health Care Workforce
- Health Disparities
- Health Inequities
- Health Policy
- Health Systems Science
- History of Medicine
- Hypertension
- Images in Neurology
- Implementation Science
- Infectious Diseases
- Innovations in Health Care Delivery
- JAMA Infographic
- Law and Medicine
- Leading Change
- Less is More
- LGBTQIA Medicine
- Lifestyle Behaviors
- Medical Coding
- Medical Devices and Equipment
- Medical Education
- Medical Education and Training
- Medical Journals and Publishing
- Mobile Health and Telemedicine
- Narrative Medicine
- Neuroscience and Psychiatry
- Notable Notes
- Nutrition, Obesity, Exercise
- Obstetrics and Gynecology
- Occupational Health
- Ophthalmology
- Orthopedics
- Otolaryngology
- Pain Medicine
- Palliative Care
- Pathology and Laboratory Medicine
- Patient Care
- Patient Information
- Performance Improvement
- Performance Measures
- Perioperative Care and Consultation
- Pharmacoeconomics
- Pharmacoepidemiology
- Pharmacogenetics
- Pharmacy and Clinical Pharmacology
- Physical Medicine and Rehabilitation
- Physical Therapy
- Physician Leadership
- Population Health
- Primary Care
- Professional Well-being
- Professionalism
- Psychiatry and Behavioral Health
- Public Health
- Pulmonary Medicine
- Regulatory Agencies
- Reproductive Health
- Research, Methods, Statistics
- Resuscitation
- Rheumatology
- Risk Management
- Scientific Discovery and the Future of Medicine
- Shared Decision Making and Communication
- Sleep Medicine
- Sports Medicine
- Stem Cell Transplantation
- Substance Use and Addiction Medicine
- Surgical Innovation
- Surgical Pearls
- Teachable Moment
- Technology and Finance
- The Art of JAMA
- The Arts and Medicine
- The Rational Clinical Examination
- Tobacco and e-Cigarettes
- Translational Medicine
- Trauma and Injury
- Treatment Adherence
- Ultrasonography
- Users' Guide to the Medical Literature
- Vaccination
- Venous Thromboembolism
- Veterans Health
- Women's Health
- Workflow and Process
- Wound Care, Infection, Healing
Get the latest research based on your areas of interest.
Others also liked.
- Download PDF
- X Facebook More LinkedIn
Banks J , Amspoker AB , Vaughan EM , Woodard L , Naik AD. Ascertainment of Minimal Clinically Important Differences in the Diabetes Distress Scale–17 : A Secondary Analysis of a Randomized Clinical Trial . JAMA Netw Open. 2023;6(11):e2342950. doi:10.1001/jamanetworkopen.2023.42950
Manage citations:
© 2024
- Permissions
Ascertainment of Minimal Clinically Important Differences in the Diabetes Distress Scale–17 : A Secondary Analysis of a Randomized Clinical Trial
- 1 Department of Management, Policy and Community Health, School of Public Health, University of Texas Health Science Center, Houston
- 2 Institute on Aging, University of Texas Health Science Center, Houston
- 3 Houston Center for Innovations in Quality, Safety, and Effectiveness, Michael E. DeBakey Veterans Administration Medical Center, Houston, Texas
- 4 Department of Internal Medicine, Baylor College of Medicine, Houston, Texas
- 5 Department of Internal Medicine, University of Texas Medical Branch, Galveston
- 6 Tilman J. Fertitta Family College of Medicine and Humana Integrated Health Systems Sciences Institute, University of Houston, Houston, Texas
- 7 Department of Internal Medicine, McGovern Medical School, University of Texas Health Science Center, Houston
Question What are the minimal clinically important differences (MCIDs) in the Diabetes Distress Scale–17 (DDS-17) and its 4 subscales?
Findings This secondary analysis using data from 248 participants in a randomized clinical trial comparing the Empowering Patients in Chronic Care (EPICC) intervention (123 participants) with enhanced usual care (EUC; 125 participants) found that the overall MCID value for DDS-17 was 0.25, and MCIDs were 0.38 for emotional and interpersonal distress subscales and 0.39 for physician and regimen distress subscales. Participants in the EPICC group were more likely to have significant improvements and less likely to have significant declines in DDS-17 compared with participants in EUC.
Meaning These findings suggest that MCID changes of 0.25 or greater were associated with clinically important improvements in diabetes distress.
Importance The Diabetes Distress Scale–17 (DDS-17) is a common measure of diabetes distress. Despite its popularity, there are no agreed-on minimal clinically important difference (MCID) values for the DDS-17.
Objective To establish a distribution-based metric for MCID in the DDS-17 and its 4 subscale scores (interpersonal distress, physician distress, regimen distress, and emotional distress).
Design, Setting, and Participants This secondary analysis of a randomized clinical trial used baseline and postintervention data from a hybrid (implementation-effectiveness) trial evaluating Empowering Patients in Chronic Care (EPICC) vs an enhanced form of usual care (EUC). Participants included adults with uncontrolled type 2 diabetes (glycated hemoglobin A 1c [HbA 1c ] level >8.0%) who received primary care during the prior year in participating Department of Veterans Affairs clinics across Illinois, Indiana, and Texas. Data collection was completed in November 2018, and data analysis was completed in June 2023.
Interventions Participants in EPICC attended 6 group sessions led by health care professionals based on collaborative goal-setting theory. EUC included diabetes education.
Main Outcomes and Measures The main outcome was distribution-based MCID values for the total DDS-17 and 4 DDS-17 subscales, calculated using the standard error of measurement. Baseline to postintervention changes in DDS-17 and its 4 subscale scores were grouped into 3 categories: improved, no change, and worsened. Multilevel logistic and linear regression models examined associations between treatment group and MCID change categories and whether improvement in HbA 1c varied in association with MCID category.
Results A total of 248 individuals with complete DDS-17 data were included (mean [SD] age, 67.4 [8.3] years; 235 [94.76%] men), with 123 participants in the EPICC group and 125 participants in the EUC group. The MCID value for DDS-17 was 0.25 and MCID values for the 4 distress subscales were 0.38 for emotional and interpersonal distress and 0.39 for physician and regimen distress. Compared with EUC, more EPICC participants were in the MCID improvement category on DDS-17 (63 participants [51.22%] vs 40 participants [32.00%]; P = .003) and fewer EPICC participants were in the worsened category (20 participants [16.26%] vs 39 participants [31.20%]; P = .008). There was no direct association of DDS-17 MCID improvement (β = −0.25; 95% CI, −0.59 to 0.10; P = .17) or worsening (β = 0.18; 95% CI, −0.22 to 0.59; P = .38) with HbA 1c levels among all participants.
Conclusions and Relevance In this secondary analysis of data from a randomized clinical trial, an MCID improvement or worsening of more than 0.25 on the DDS-17 was quantitatively significant and patients in the EPICC group were more likely to experience improvement than those in the EUC group.
Trial Registration ClinicalTrials.gov Identifier: NCT01876485
Clinical trials demonstrate lower morbidity and mortality in patients with type 2 diabetes by reducing hemoglobin A 1c (HbA 1c ) levels. 1 Because diabetes is a chronic condition, sustained reduction of HbA 1c requires patient activation, commitment to treatment planning, and self-management. 2 The lifestyle changes required to manage diabetes may carry an emotional burden that contributes to diabetes-associated distress. 3 Diabetes distress refers to the worries, fears, and threats arising from struggles with chronic diabetes care (ie, management, complications, and loss of function) 4 and is associated with changes in HbA 1c levels. 5 , 6 Patients with high distress have significantly higher HbA 1c levels and are less likely to maintain blood glucose levels within the reference range. 7
The Diabetes Distress Scale–17 (DDS-17) is an established, validated measure with 17 items to assess the level of distress in patients with diabetes. 8 - 10 Higher DDS-17 scores are associated with poor lifestyle choices, self-management, self-efficacy, self-care, and adherence to recommended treatment regimens, 11 - 13 while lower scores are associated with reductions in HbA 1c . 14 Prior DDS-17 validation studies have suggested severity thresholds as little or no distress, less than 2.0; moderate distress, 2.0 to 2.9; and high distress, greater than 3.0. 15 DDS-17 is often used as a dichotomous variable, with scores of 2.0 or greater signifying the presence of moderate diabetes distress. 11 , 13 , 15 However, cutpoints are limited by their inability to capture significant changes in DDS-17 scores that do not cross a cutpoint. For example, an individual whose DDS-17 score decreases from 2.8 to 2.1 may experience meaningful improvements in diabetes distress, but the moderate distress cutoff is unchanged. This limitation can be overcome through calculation of minimal clinically important differences (MCIDs). MCIDs are useful in interpreting the clinical relevance of observed changes at both individual and group levels. 9 , 10 Given that DDS-17 is scored on a continuous scale, distribution-based MCIDs are a useful alternative to dichotomous cutoff scores. Distribution-based MCIDs are defined as a numerical score that represents the smallest value of change anywhere along the entire range of a continuous measure that would be considered meaningful. 8 , 10
We previously developed Empowering Patients in Chronic Care (EPICC) and described its value in a series of studies. 16 - 24 EPICC is a goal-setting intervention that uses coaching and motivational interviewing to activate patients to explore what matters most to them about their health, 16 , 17 set outcome goals based on their priorities, 18 , 19 develop skills to communicate goals with clinicians, 20 and create action plans to achieve their goals. 21 , 22 EPICC has been successfully adopted into the routine primary care workflow using implementation strategies. 23 A 2022 multisite clinical trial 24 demonstrated the effectiveness of EPICC compared with enhanced usual care (EUC) at reducing HbA 1c and diabetes distress 4 months after the intervention in routine primary care practices. Diabetes distress was assessed in the EPICC trial using the DDS-17.
In this study, we establish the distribution-based MCIDs for DDS-17 and each of the 4 subscales of the DDS-17 using a quantitative calculation translated into 3 categories of change in DDS-17 scores: improvement, no change, and worsening. We then compare the percentage identified in each MCID category relative to the percentage of participants defined as changing based on crossing over the established DDS-17 cutpoint of 2.0. We also examined associations of MCID categories with participation in the EPICC treatment group and change in HbA 1c levels.
This secondary analysis of a randomized clinical trial was approved by the Department of Veterans Affairs (VA) central institutional review board, and each clinic-based research and development committee approved the protocol. All participants provided verbal informed consent by telephone. This study reports on secondary outcomes from a multisite, randomized clinical trial of the EPICC intervention conducted from July 1, 2015, through June 30, 2017, among participants with treated but uncontrolled diabetes. 24 , 25 The study conformed to the Consolidated Standards of Reporting Trials ( CONSORT ) reporting guideline. The trial protocol and statistical analysis plan are provided in Supplement 1 .
We previously described the intervention protocol and primary results of the EPICC study. 24 , 25 In that study, we used a hybrid (implementation-effectiveness) clinical trial design to randomize 280 participants to EPICC or EUC in VA primary care clinics across Illinois, Indiana, and Texas. The inclusion criterion was a diagnosis of uncontrolled diabetes with a mean HbA 1c level greater than 8.0% (to convert to proportion of total hemoglobin, multiply by 0.01) in the prior 6 months. EUC participants received routine care that included educational materials, nutrition counseling, medication management or weight loss support, a list of self-management resources routinely offered at their site (eg, traditional diabetes education). EPICC participants attended 6 bimonthly group sessions for 50 minutes each, followed by 10-minute 1-on-1 sessions based on collaborative goal setting and motivational interviewing theory for 3 months. The trial’s primary outcomes evaluated the clinical effectiveness of EPICC compared with EUC after the intervention. 24 , 25
Diabetes distress was measured in this study using the DDS-17. The DDS-17 consists of 17 items that measure patients’ perceptions in 4 general domains of distress: interpersonal, physician, regimen, and emotional. Interpersonal distress (3 items) reflects the psychological emotions and feelings of patients with diabetes during their interaction with people around them. Physician distress (4 items) portrays the distress that patients experience during interaction with their physician. Regimen distress (5 items) describes the distress felt by patients because of the need to adhere to a diabetes management plan. Emotional burden (5 items) describes the distress related to emotions associated with having diabetes. 26 Each individual item is measured on a Likert scale of 1 (no distress) to 6 (serious distress), and a mean composite score is also determined, with higher scores indicating greater distress. 27 , 28 The DDS-17 has been validated across a number of settings for assessing distress levels. 11 - 14 , 29 Both the total DDS-17 and its subscales demonstrate good internal consistency, reliability, and construct validity, given associations with depression measures, metabolic variables, and disease management, as well as lack of associations with sex, ethnicity, and education. 11 , 29 This study includes the 248 individuals from the EPICC trial who have DDS-17 and HbA 1c data at both baseline and postintervention (4 months after baseline) assessments.
We first used independent samples t tests and χ 2 tests to evaluate whether participants who completed DDS-17 at both baseline (248 participants) and the postintervention assessment differed from those who only completed the baseline assessment (32 participants). We then calculated descriptive statistics (means, SDs, frequencies) for demographic characteristics overall and separately for each treatment group. Race and ethnicity were collected through self-report and categorized as Hispanic, non-Hispanic Black, non-Hispanic White, and other (including American Indian and other race or ethnicity not specified). Race and ethnicity data were included in analyses to maximize data richness and minimize opportunities for researchers’ assumptions about participants’ identities.
MCIDs can be calculated using distribution-based approaches. Distribution-based approaches are based on statistical criteria from patient-reported outcome scores. 30 These approaches include fractions of the SD of patient-reported outcome scores, the effect size, 31 and the standard error of measurement (SEM) 8 , 32 as estimates for the MCID. A score change greater than or equal to the value of the SEM represents meaningful variation in the measured construct that is likely not due to measurement error. 10 This method produces MCIDs that are expressed in the same units of measurement as the patient-reported outcome score. 32 We used the SEM distribution-based method, which uses the SD and Cronbach α of baseline scores, SD × sqrt(1 − α) 8 to calculate the MCID for the DDS-17 and its 4 subscales.
Using the resulting DDS-17 MCID value, we determined whether change on the DDS-17 and each of 4 subscales from baseline to after the intervention indicated improvement (a decrease ≥ the MCID value), no change (stayed within ± the MCID value), or worsening (an increase ≥ the MCID value). Given prior validation of the DDS-17 cutpoint of 2 indicating moderate distress, 15 we evaluate 3 categories of change between baseline and after the intervention across this cutpoint: (1) participants who started with scores greater than 2 at baseline and crossed to less than 2, (2) participants who started with scores less than 2 at baseline and crossed to greater than 2, and (3) participants who did not cross the cutpoint from baseline to after the intervention.
Given participants were nested within cohorts that were also nested within sites, we calculated intraclass correlation coefficients (ICC) for the total DDS-17 as well as the 4 subscales to determine whether multilevel models accounting for dependency in the data were warranted. The degree of variance in the DDS-17 attributable to differences between both cohort and site (ie, ICCs >0.05), indicated that multilevel models accounting for the dependency of participants (level 1) within cohorts (level 2) within sites (level 3) were warranted. For the DDS-17 and each of the 4 subscales, 2 sets of multilevel logistic regression models were used to evaluate differences between EPICC and EUC participants in DDS-17 MCID categories. The first set consisted of an examination of treatment group (in which EPICC = 1 and EUC = 0) as a factor of whether a participant showed MCID improvement (with yes = 1 and no = 0, which collapsed no change and worsening) and the second set consisted of an examination of treatment group as a factor of whether a participant showed MCID worsening (with 1 = yes and 0 = no, which collapsed no change and improvement). For each set, 5 models were conducted: 1 for DDS-17 and the 4 subscales. Prior diabetes education was included as a covariate in all models examining differences between treatment groups, given differences between treatment groups in this variable.
Change in HbA 1c was calculated by subtracting baseline scores from postintervention scores, such that negative values indicated reduction (clinical improvement) in HbA 1c values. We first calculated descriptive statistics to evaluate mean change in HbA 1c by MCID improvement, worsening, and no change. We subsequently used a pair of multilevel linear regression models for each the DDS-17 and the 4 subscales to examine the effect of MCID category on change in HbA 1c values from baseline to after the intervention. The first set of models examined MCID improvement (with yes = 1 and no = 0) as a factor and the second set examined MCID worsening (with yes = 1 and no = 0) as a factor. Treatment group was included as a covariate in all models. Analyses were conducted using SAS version 9.4 (SAS Institute). Sample SAS code for our analyses is provided in the eMethods in Supplement 2 . P values were 2-tailed, and statistical significance was set at α = .05. Data collection was completed in November 2018, and data analysis was completed in June 2023.
A total of 248 individuals with complete DDS-17 data were included (mean [SD] age, 67.4 [8.3] years; 235 [94.76%] men), with 123 participants in the EPICC group and 125 participants in the EUC group ( Table 1 ). There were 28 Hispanic participants (11.30%), 94 non-Hispanic Black participants (37.90%), and 121 non-Hispanic White participants (48.79%). The 32 participants without postintervention DDS-17 data did not significantly differ on any demographics or baseline characteristics from the 248 participants with postintervention DDS-17 data. Therefore, we proceeded to calculate MCID values and subsequent analyses among the 248 participants with DDS-17 scores at both assessments ( Figure ). Most participants had an annual income of less than $40 000 (143 participants [62.17%]) and had at least some college education (185 participants [74.60%]).
The MCID for DDS-17 was 0.25, with subscale MCID values of 0.38 for emotional distress and interpersonal distress and 0.39 for physician distress and regimen distress ( Table 2 ). MCID captured a different degree of change compared with the DDS-17 cutoff level of 2.0. From baseline to postintervention, 103 participants (41.53%) experienced improvement (≥0.25 decrease in DDS-17), 59 participants (23.79%) experienced worsening (≥0.25 increase in DDS-17), and 86 participants (34.68%) had no change, ie, their change was less than 0.25 on the DDS-17. In comparison, only 49 participants (19.76%) of all participants with DDS-17 levels greater than 2 at baseline reported scores that decreased less than 2 after the intervention. Only 25 participants (10.08%) with DDS-17 levels less than 2 at baseline reported scores that increased to greater than 2 after the intervention. Most participants remained either above (102 participants [41.13%]) or below (72 participants [29.03%]) the DDS-17 cutoff of 2 during both study time points. For DDS-17 subscales, MCID improvements were reported by 107 participants (43.15%) for emotional distress, 62 participants (25.00%) for physician distress, 119 participants (47.98%) for regimen distress, and 65 participants (26.21%) for interpersonal distress among all participants.
A greater proportion of participants in the EPICC cohort reported an MCID improvement compared with participants in EUC (63 participants [51.22%] vs 40 participants [32.00%]) ( Table 3 ). EPICC participants were significantly more likely to be in the improved category for DDS-17 overall (odds ratio [OR], 2.24 [95% CI, 1.33 to 3.78]) and for emotional distress (OR, 2.24 [95% CI, 1.33 to 3.77]) and regimen distress (OR, 1.86 [95% CI, 1.11 to 3.12]) subscales compared with EUC participants. Treatment group was unrelated to DDS-17 MCID improvement for physician distress and interpersonal distress. Participants who received EPICC were significantly less likely to be in the MCID worsening category for DDS-17 overall (OR, 0.43 [95% CI, 0.23 to 0.80]), regimen distress (OR, 0.41 [95% CI, 0.22 to 0.77]), and interpersonal distress (OR, 0.46 [95% CI, 0.24 to 0.89) scores compared with EUC participants. Treatment group was unrelated to DDS-17 MCID worsening for emotional distress and physician distress ( Table 3 ).
Mean reduction in HbA 1c from baseline to after the intervention was higher among the total DDS-17 MCID improvement category (−0.44% [95% CI, −0.74% to −0.14%]), compared with the no change (−0.17% [95% CI, −0.39% to 0.05%]) and worsening (−0.06% [95% CI, −0.39% to 0.27%]) categories ( Table 4 ). However, neither DDS-17 MCID improvement nor worsening categories were associated with significant change in HbA 1c scores (improvement: β = −0.25 [95% CI, −0.59 to 0.10]; P = .17; worsening: β = 0.18 [95% CI, −0.22 to 0.59]; P = .38). There were no significant associations for DDS-17 MCID improvement or worsening categories on HbA 1c change among the overall sample.
This secondary analysis of a randomized clinical trial established an MCID value of 0.25 for the DDS-17, 0.38 MCID for emotional distress and regimen distress subscales, and 0.39 MCID for physician distress and regimen distress subscales. Distribution-based MCIDs are a numerical score that represents the smallest value of change that would be considered meaningful anywhere along the entire range of a continuous measure. These values provide ranges for defining significant improvement (≥0.25 decline in DDS-17), no change (DDS-17 change of ≤0.25), and significant worsening (≥0.25 increase in DDS-17) in diabetes distress levels. Participants in the EPICC intervention were significantly more likely to be in the improving category and less likely to be in the worsening category. MCID improvement in the DDS-17 was associated with mean HbA 1c reduction of 0.44%. However, no statistically significant associations were found between HbA 1c change and MCID improvement or worsening in the DDS-17. No subscale had statistically significant associations of MCID change with HbA 1c change. Previous research has provided evidence for an association among regimen distress, behavioral self-management, and glycemic control, positing that improvements in management and HbA 1c levels co-occur with improvements with regimen distress. 33 This prior work, coupled with our findings, provide support for addressing regimen distress in clinical care as part of diabetes management.
This study was the first, to our knowledge, to calculate the MCID for the DDS-17 and each of the 4 subscales of the DDS-17. A combination of both anchor- and distribution-based methods is typically perceived as the preferred method for calculating MCIDs. 34 The anchor-based option was not applicable for our calculation of MCID, since we did not ask participants to quantify the extent to which they felt their diabetes distress changed from baseline to after the intervention. The distribution-based MCID values calculated in this study (0.25 to 0.39) closely align with previous research defining the MCID for the 28-item T1-Diabetes Distress Scale and its subscales (0.19 to 0.50). 8 MCID values of the Type 2 Diabetes Distress Assessment have also recently been defined (0.25) and was similar to the DDS-17 MCID score calculated in this study, indicating consistency across similar diabetes distress scales. 35 In this study, we establish an MCID change of at least 0.25 as a quantitative metric for determining clinically important change in DDS-17 scores. This provides pragmatic guidance for intervention studies that complements the established DDS-17 cutoff score of 2.0 previously described in literature. 11 , 13 , 15
For the DDS-17 and its 4 subscales, we used 3 classifications to characterize change in scores from baseline to after the intervention: MCID improvement, no change, or MCID worsening. This approach adds to the binary (yes vs no) improvement concept by introducing the clinically important state of not worsening. Given the heterogeneous patterns of associations between DDS-17 MCID categories and treatment group, categorizing change in DDS-17 scores as improvement (yes vs no) or worsening (yes vs no) relative to their MCID value may indicate dual ways to frame response to a treatment: improvement or not worsening. Quantitative trends in HbA 1c change were observed among the MCID worsening, no change, and improvement categories. However, this association was not statistically significant. These findings suggest that significant change in HbA 1c may require greater than MCID levels of improvement in diabetes distress.
The study has limitations. Results may be limited to a population of largely male veterans seen in primary care clinics within the VA. However, MCID results used an established methodology found in prior studies calculating MCID for other diabetes distress scales with corresponding MCID values. MCID values were calculated using a distribution method only, which maybe limited without a corresponding anchor value that provides a subjective measure of change from a baseline. 36 , 37 Given that we did not ask participants how their diabetes distress changed from baseline to after the intervention (ie, worsened, no change, improved), an anchor-based method was not possible for us to use. In using the SEM distribution-based method, we did allow the MCIDs calculated to be better applied to diverse populations as the SEM is a property of the scale, not a property of a particular sample’s DDS-17 distribution. 8 Analyses were limited to data collected during a 4-month period using 2 assessments as part of a clinical trial. However, participants of the current study were recruited from a large, diverse, community sample of adults with diabetes across 3 states. Data from longitudinal cohort studies outside of an intervention trial may be needed to replicate and extend our findings.
This secondary analysis of a randomized clinical trial identified improvement or worsening of at least 0.25 on the DDS-17 scale as the MCID. This MCID value is an appropriate method for assessing significant change in the DDS-17 from baseline to after a treatment intervention, given the evidence for an association between MCID improvements in DDS-17 scores among EPICC participants. The MCID values identified in this study can be used to inform future research examining diabetes distress using the DDS-17. Further, MCID values for DDS-17 can potentially be used by clinicians to assess response to treatments in their patients.
Accepted for Publication: October 3, 2023.
Published: November 15, 2023. doi:10.1001/jamanetworkopen.2023.42950
Open Access: This is an open access article distributed under the terms of the CC-BY License . © 2023 Banks J et al. JAMA Network Open .
Corresponding Author: Jack Banks, PhD, The University of Texas Health Science Center at Houston, 1200 Pressler St, Project Room E-929, Houston, TX 77030 ( [email protected] ).
Author Contributions: Drs Amspoker and Naik had full access to all of the data in the study and take responsibility for the integrity of the data and the accuracy of the data analysis.
Concept and design: Banks, Amspoker, Woodard, Naik.
Acquisition, analysis, or interpretation of data: All authors.
Drafting of the manuscript: Banks, Amspoker, Vaughan.
Critical review of the manuscript for important intellectual content: Banks, Woodard, Naik.
Statistical analysis: Banks, Amspoker.
Obtained funding: Woodard, Naik.
Administrative, technical, or material support: Naik.
Supervision: Vaughan, Naik.
Conflict of Interest Disclosures: Dr Woodard reported receiving personal fees from Texas Medical Board Medical Record Review outside the submitted work. Dr Naik reported receiving grants from Houston Center for Innovations in Quality, Effectiveness and Safety at the Michael E. DeBakey VA Medical Center during the conduct of the study. No other disclosures were reported.
Funding/Support: This work was supported by grant No. CRE 12-426 (Drs Woodard, Naik, and Amspoker) from the VA Health Services Research and Development; by grant CIN 13-413 from the Department of Veterans Affairs (VA) Health Services Research and Development (Houston Center for Innovations in Quality, Effectiveness, and Safety at the Michael E. DeBakey VA Medical Center). Dr Vaughan was supported by the National Institutes of Health, National Institute of Diabetes and Digestive and Kidney Diseases (grant No. DK129474).
Role of the Funder/Sponsor: The funders had no role in the design and conduct of the study; collection, management, analysis, and interpretation of the data; preparation, review, or approval of the manuscript; and decision to submit the manuscript for publication.
Meeting Presentation: This paper was presented at the Annual Meeting of the American Geriatrics Society; May 5, 2023; Long Beach, California.
Data Sharing Statement: See Supplement 3 .
- Register for email alerts with links to free full-text articles
- Access PDFs of free articles
- Manage your interests
- Save searches and receive search alerts
- Open access
- Published: 17 May 2024
Quantitative analysis of th e effects of brushing, flossing, and mouthrinsing on supragingival and subgingival plaque microbiota: 12-week clinical trial
- Kyungrok Min 1 ,
- Mary Lynn Bosma 1 ,
- Gabriella John 1 ,
- James A. McGuire 1 ,
- Alicia DelSasso 1 ,
- Jeffery Milleman 2 &
- Kimberly R. Milleman 2
BMC Oral Health volume 24 , Article number: 575 ( 2024 ) Cite this article
Metrics details
Translational microbiome research using next-generation DNA sequencing is challenging due to the semi-qualitative nature of relative abundance data. A novel method for quantitative analysis was applied in this 12-week clinical trial to understand the mechanical vs. chemotherapeutic actions of brushing, flossing, and mouthrinsing against the supragingival dental plaque microbiome. Enumeration of viable bacteria using vPCR was also applied on supragingival plaque for validation and on subgingival plaque to evaluate interventional effects below the gingival margin.
Subjects with gingivitis were enrolled in a single center, examiner-blind, virtually supervised, parallel group controlled clinical trial. Subjects with gingivitis were randomized into brushing only (B); brushing and flossing (BF); brushing and rinsing with Listerine® Cool Mint® Antiseptic (BA); brushing and rinsing with Listerine® Cool Mint® Zero (BZ); or brushing, flossing, and rinsing with Listerine® Cool Mint® Zero (BFZ). All subjects brushed twice daily for 1 min with a sodium monofluorophosphate toothpaste and a soft-bristled toothbrush. Subjects who flossed used unflavored waxed dental floss once daily. Subjects assigned to mouthrinses rinsed twice daily. Plaque specimens were collected at the baseline visit and after 4 and 12 weeks of intervention. Bacterial cell number quantification was achieved by adding reference amounts of DNA controls to plaque samples prior to DNA extraction, followed by shallow shotgun metagenome sequencing.
286 subjects completed the trial. The metagenomic data for supragingival plaque showed significant reductions in Shannon-Weaver diversity, species richness, and total and categorical bacterial abundances (commensal, gingivitis, and malodor) after 4 and 12 weeks for the BA, BZ, and BFZ groups compared to the B group, while no significant differences were observed between the B and BF groups. Supragingival plaque vPCR further validated these results, and subgingival plaque vPCR demonstrated significant efficacy for the BFZ intervention only.
Conclusions
This publication reports on a successful application of a quantitative method of microbiome analysis in a clinical trial demonstrating the sustained and superior efficacy of essential oil mouthrinses at controlling dental plaque compared to mechanical methods. The quantitative microbiological data in this trial also reinforce the safety and mechanism of action of EO mouthrinses against plaque microbial ecology and highlights the importance of elevating EO mouthrinsing as an integral part of an oral hygiene regimen.
Trial registration
The trial was registered on ClinicalTrials.gov on 31/10/2022. The registration number is NCT05600231.
Peer Review reports
Changes in the structure of microbial communities within the dental plaque biofilm serve as a primary etiological factor in common oral diseases, such as caries and periodontitis [ 1 ]. In addition to toothbrushing, controlling the plaque biofilm relies on a variety of adjunctive methods that include mechanical flossing and chemotherapeutic mouthrinses.
Despite limited evidence of efficacy, flossing has been a long-standing recommendation [ 2 ] among dental professionals for the mechanical removal of interproximal plaque. In a systematic review and meta-analysis conducted by Worthington et al., there was “low-certainty evidence” to suggest “that flossing, in addition to toothbrushing, may reduce gingivitis (measured by gingival index (GI)) at one month (SMD -0.58, 95% confidence interval (CI) ‐1.12 to ‐0.04; 8 trials, 585 participants), three months or six months. The results for proportion of bleeding sites and plaque were [also] inconsistent (very low‐certainty evidence).” [ 3 ].
When used as an adjunct to daily mechanical oral hygiene, an alcohol-containing mouthrinse with a fixed combination of four essential oils (EOs) has a long history of demonstrated clinical reductions in plaque, gingivitis, and gingival bleeding [ 4 , 5 ] and has performed favorably when compared to flossing in two recent 3-month clinical trials [ 6 , 7 ]. An alcohol-free EO mouthrinse also performed similarly to an alcohol-containing mouthrinse in 6-month clinical trials [ 8 , 9 ]. The antimicrobial action of alcohol-containing EO mouthrinses has consistently demonstrated reductions of oral microbes in a variety of oral anatomic locations, including the tongue, cheek, and subgingival crevice [ 10 , 11 , 12 , 13 ]. These data were derived using well-established, although dated, methodologies, such as bacterial cell culture enumeration [ 14 , 15 ] and checkerboard DNA-DNA hybridization examining specific bacterial species [ 16 , 17 ].
More recently, advances in microbial profiling using high throughput DNA sequencing have revealed the presence of over 700 bacterial species in the human oral cavity [ 18 ]. These new methods enable highly detailed studies of the oral microbiome, which is essential to more fully understand the role of oral microbes in the pathogenesis of, and therefore the potential prevention of, a variety of oral diseases. Currently, however, there is only partial understanding of how certain mechanical and chemotherapeutic interventions impact the oral microbiome. There are limited quantifiable microbiome data describing time-resolved changes in absolute individual bacterial species abundances, spatiotemporal development of microbial communities, and their clinical relevance on various oral surfaces. This is particularly true of interproximal sites where plaque can remain relatively undisturbed and has a greater diversity of bacteria, including those associated with gingivitis, than more easily accessible areas of the mouth [ 19 , 20 ].
This clinical trial investigated how flossing and mouthrinses containing a fixed combination of EOs with and without alcohol impact plaque microbiota by generating absolute quantitative microbiome data using a new method of microbiome profiling analysis [ 21 ] and viable bacteria enumeration by vPCR. Plaque specimens were spiked with known amounts of exogenous control DNA to enable the quantification of bacterial cell numbers. Further, species identities were carefully annotated and categorized according to their clinical relevance using published literature evidence. The subjects recruited in this trial used floss once daily, mouthrinses twice daily, or a combination of both flossing and mouthrinsing for 12 weeks [ 22 ]. This mechanistic study is the first to provide a comprehensive quantification of oral care regimen impacts on the plaque microbiome using clinically relevant microbiological metrics.
Study design
This clinical trial was conducted between April 18, 2022 and July 21, 2022 at Salus Research, Inc. (Fort Wayne, Indiana, USA), an independent clinical research site qualified by the American Dental Association Seal of Acceptance Program. This examiner-blind, controlled, randomized, single-center, and parallel-group clinical trial was conducted in accordance with the principles of the International Council on Harmonization for Good Clinical Practice.
Periodontally healthy subjects and subjects with gingivitis were enrolled separately according to the inclusion and exclusion criteria. All subjects refrained from oral hygiene, food, beverages, and smoking for 8 to 18 h before oral examination of the hard and soft tissues, gingivitis, and plaque. Supragingival plaque was collected for microbiome analysis and subgingival plaque for viable bacteria count using PCR (vPCR) as secondary study endpoints before staining the whole mouth plaque with a disclosing dye. The periodontally healthy cohort participated only in one baseline visit, while subjects with gingivitis progressed through the trial after randomization into one of five intervention groups: [B] brushing only; [BF] brushing and flossing with Reach® Unflavored Waxed Dental Floss (Dr. Fresh LLC, Buena Park, California, USA); [BA] brushing and rinsing with Listerine® Cool Mint® Antiseptic (Johnson & Johnson Consumer Inc, New Jersey, USA); [BZ] brushing and rinsing with Listerine® Cool Mint® Zero Alcohol (Johnson & Johnson Consumer Inc, New Jersey, USA); and [BFZ] brushing, flossing, and rinsing with Listerine® Cool Mint® Zero Alcohol. Complete dental prophylaxis was administered to remove all accessible plaque and calculus. The subjects were given a fluoridated toothpaste (Colgate® Cavity Protection, Colgate-Palmolive Company, NY, USA) and brushed twice daily for 1 timed minute using a standard soft-bristled toothbrush (Colgate® Classic Toothbrush Full Head/Soft Bristles, Colgate-Palmolive Company, NY, USA). Subjects in the flossing groups rinsed their mouth with water after brushing and then flossed once daily. Subjects in the mouthrinse groups rinsed with 20 mL of their assigned mouthrinse for 30 timed seconds twice daily after brushing and flossing or brushing. Primary endpoints were based on clinical gingivitis and plaque assessments and secondary endpoints included supragingival and subgingival plaque microbiome assessments. Supragingival plaque microbiome assessments were completed at baseline before prophylaxis and after 4 and 12 weeks of product intervention, while subgingival plaque vPCR assessments were completed only after 12 weeks of intervention. To ensure compliance, all subjects received an initial training at the clinical site for the correct usage of their assigned products and were subsequently supervised virtually once daily during the weekdays through a video call. Subjects were unsupervised for their second daily use in the evening or on weekends, however, compliance for homecare regimen was monitored through individual diaries and by weighing their assigned toothpaste and mouthrinses at each visit.
Subject inclusion & exclusion
Healthy adults 18 years of age or older with a minimum of 20 natural teeth with scorable facial and lingual surfaces were included. Requirements for the periodontally healthy subjects were whole-mouth mean scores of: Modified Gingival Index (MGI) [ 23 ] ≤ 0.75, Expanded Bleeding Index (EBI) [ 24 ] < 3%, and no teeth with periodontal pocket depth (PPD) exceeding 3 mm [ 25 , 26 , 27 ]. Requirements for the randomized subjects with gingivitis were evidence of some gingivitis (mild to severe), minimum of 10% bleeding sites based on the EBI, no more than three sites having PPD of 5 mm or any sites exceeding 5 mm, and absence of significant oral soft tissue pathology, advanced periodontitis, and oral appliances, which may interfere with flossing.
Key exclusion criteria included the use of chemotherapeutic oral care products containing triclosan, EOs, cetylpyridinium chloride, stannous fluoride, or chlorhexidine; professional dental prophylaxis 4 weeks before the baseline; use of probiotics within 1 week before baseline or during the study, antibiotics, anti-inflammatory, or anticoagulant therapy within 1 month before baseline or during the study; use of intraoral devices; substance abuse (alcohol, drugs, or tobacco); history of significant adverse effects; allergies or sensitivity against oral hygiene products; pregnancy; significant medical conditions; and participation in any clinical trials within 30 days of the trial.
Sample size, randomization, and blinding
The sample size for this study was based on power to detect differences based on plaque and gingivitis endpoints. The planned sample size of 50 completed subjects per randomized intervention group provides 95% power to detect a difference between BA or BZ and BF means of 0.34 for Interproximal Mean MGI, given a standard deviation of 0.43, based on a two-sided test at the 2.5% significance level. This sample size also provides greater than 99% power to detect a difference between BA or BZ and BF means of 0.54 for Interproximal Mean Turesky Plaque Index (TPI) [ 28 ], given a standard deviation of 0.38. The standard deviation estimates were based on previous three-month studies using the examiners for the current study, and the differences between means are conservative estimates based on previous studies of this type. Sample sizes were estimated using PASS version 14.0.4 (NCSS, LLC, Kaysville, UT, USA). Assuming a 5% drop-out rate, the trial recruited 54 subjects per group or 270 subjects with gingivitis to ensure that the trial would be completed with at least 250 subjects in the randomized intervention groups. An additional 30 subjects, representing the non-randomized and periodontally healthy reference group, were recruited for a baseline assessment only.
The randomization schedule for subjects with moderate gingivitis was generated using a validated program created by the Biostatistics Department at Johnson & Johnson Consumer Inc. (Skillman, NJ, USA). The subjects with gingivitis were randomized in an equal allocation using a block size of ten and were assigned a unique randomization number that determined the sequential assignment of intervention products at the baseline visit. To minimize bias, the principal investigator and examiners were blinded to the administered intervention products, while the clinical personnel dispensing them were excluded from subject examinations.
Oral examination
All clinical assessments in this trial were performed by the same dental examiners. One examiner performed the oral hard and soft tissue assessments, MGI grading, and selection of teeth (as described below) to be sampled. Another examiner performed EBI and TPI grading. Both examiners were trained and calibrated with the visual assessment of gingival inflammation, supragingival plaque, and gingival bleeding as measured using the MGI, TPI, and EBI. All examinations were conducted in the following order: an oral hard and soft tissue assessment, MGI, supragingival and subgingival plaque sampling, EBI, and TPI.
Plaque sample collection
Plaque samples were collected by the same dental hygienist from the same four teeth selected at baseline, which met the inclusion and exclusion criteria for periodontally healthy subjects or subjects with gingivitis. The preferential teeth numbers were 3, 7, 18, and 23. Adjacent teeth that met the selection criteria were substituted for missing teeth.
Supragingival plaque for microbiome analysis was collected at all visits by moving a sterile curette five strokes supragingivally from the mesiobuccal line angle to follow the gingival margin to interproximal, from the distobuccal line angle to interproximal, and then repeating on the lingual side. Subgingival plaque for vPCR analysis was collected at week 12, during the last visit, using a sterile 204-sickle scaler to enter the interproximal subgingival space, removing plaque within one stroke, and repeating on all buccal and lingual interproximal surfaces. For each individual subject, the supragingival plaque and subgingival plaque samples were pooled, placed separately in 250 µL of sterile ultrapure grade phosphate-buffered saline with pH 7.2, and stored at -80 o C.
Shotgun metagenomic sequencing
Microbiome analysis of supragingival plaque was performed using next-generation DNA sequencing at CosmosID, Inc. (Germantown, Maryland, USA). DNA isolation, library preparation, and sequencing were carried out according to vendor-optimized protocol. Briefly, ZymoBIOMICS Spike-in Control II (Zymo Research, Irvine, CA) was added to plaque specimens to enable bacterial cell number quantification. To enhance cell lysis, plaque samples were incubated with MetaPolyzyme at 35 °C for 12 h, and DNA was extracted using ZymoBIOMICS DNA MicroPrep with bead-beating according to the manufacturer’s instructions. DNA concentrations were determined using the Qubit dsDNA HS assay and Qubit 4 fluorometer (ThermoFisher Scientific, Waltham, MA). DNA libraries were prepared using 1 ng of input genomic DNA that was fragmented, amplified, and indexed employing the Nextera XT DNA Library Preparation and Nextera Indexing Kit (Illumina, San Diego, CA). DNA libraries were purified using AMPure magnetic beads (Beckman Coulter, Brea, CA) and then normalized for equimolar pooling. Sequencing was performed using a HiSeq sequencer (Illumina), targeting a coverage of 3 − 4 million paired-end 2 × 150 bp reads.
Viability qPCR
Quantification of live bacteria from supragingival and subgingival plaque samples was performed at week 12 using vPCR at Azenta Life Sciences, Inc. (South Plainfield, NJ). Plaque samples were treated with PMAxx™ dye (Biotium, San Francisco, CA) soon after their collection to a final concentration of 100 µM, followed by photolysis with blue light for 15 min to inactivate dead bacterial cell DNA. Excess dye was neutralized using Tris-Cl buffer to a final concentration of 5 mM, followed by another cycle of photolysis. After standard DNA extraction, vPCR was performed using a vendor-optimized protocol based on SYBR GREEN chemistry. Target detection included total bacteria using the 16S rRNA universal primer pair 5’-GTGSTGCAYGGYTGTCGTCA-3’ and 5’-ACGTCRTCCMCACCTTCCTC-3’; Actinomyces oris , using the 16S rRNA primer pair 5’-TCGACCTGATGGACGTTTCGC-3’ and 5’-ACGGTTGGCATCGTCGTGTT-3’; Fusobacterium nucleatum , using the RpoB primer pair 5’-GGTTCAGAAGTAGGACCGGGAGA-3’ and 5’-ACTCCCTTAGAGCCATGAGGCAT-3’; and Porphyromonas gingivalis , using RpoB primer pair 5’-TTGCTGGTTCTGGATGAGTG-3’ and 5’-CAGGCACAGAATATCCCGTATTA-3’.
Microbiome computational analysis
Raw DNA sequence reads were processed and quality filtered by CosmosID. Bacterial diversity analyses were performed using R statistical programming language version 3.6.1 [ 29 ]. Alpha-diversity was assessed using the vegan package version 2.5.6 [ 30 ] and included observed richness and Shannon-Weaver diversity indices at the species taxonomic level. Statistical comparisons between the treatment groups were evaluated using mixed effects model for repeated measures with baseline covariate and terms for treatment, visit, treatment-by-visit, and baseline-by-visit, and unstructured within-subject covariance. Based on this model, pair-wise comparisons were tested, each at the 5% significance level, two-sided, between each mouthrinse containing group and floss containing group with B and between each mouthrinse containing group with BF. Statistical significance between the healthy and gingivitis cohorts was tested at the 5% significance level, two-sided, using two-sample t -test assuming unequal variance.
Beta-diversity analysis was performed using the phyloseq package version 1.28.0 [ 31 ] to calculate the phylogenetic distance matrix by weighted UniFrac [ 32 ] and ordination using principal coordinate analysis. The input phylogenetic tree was constructed using GenBank Common Tree based on the data taxonomy table. Significance testing of factors and interactions that affect bacterial compositions was performed with permutational multivariate analysis of variance (PERMANOVA) [ 33 ] using adonis in the vegan package [ 30 ].
For bacterial abundance quantification, standard calibration curves of reference control DNA were evaluated for individual samples [ 21 ]. The DNA amounts of bacterial species were calculated using the linear regression of added amounts of reference control DNA vs. output relative abundances and genome molecular weights specific for each bacterial species from GenBank [ 34 ]. The resulting bacterial abundances were expressed in units of calculated microbial units (CMUs) and represented in base 10 log where appropriate.
For the quantitative assessment of product intervention, bacterial species were classified into specific categories based on their association with oral conditions. These included commensal, malodor, gingivitis, and acidogenic bacterial groups. The classification was based on a review of the primary scientific literature, including journal research articles and clinical research reports as well as annotations from the Human Oral Microbiome Database [ 35 ]. The abundance of bacterial species associated with these different categories was log10-transformed and aggregated per sample basis, and the means of log10 values from all samples were reported.
Study group characteristics
A summary of subject recruitment and a list of baseline demographic and oral health parameters are presented in Fig. 1 ; Table 1 . This trial enrolled 300 generally healthy adults, of which 16 discontinued. For full data analysis, 288 subjects were evaluated including those that partially completed the study with primary and secondary evaluations performed at baseline and at least one post-baseline visit: 30 subjects were in good periodontal health, whereas 256 had gingivitis and were randomized into five treatment arms: 53 in the brushing only group (B); 50 in the brushing and flossing group (BF); 51 in the brushing and rinsing with Listerine® Cool Mint® Antiseptic group (BA); 52 in the brushing and rinsing with Listerine® Cool Mint® Zero Alcohol group (BZ); and 52 in the brushing, flossing, and rinsing with Listerine® Cool® Mint Zero Alcohol group (BFZ). All treatments in this trial were well tolerated. The mean (SD) ages of the healthy subjects and subjects with gingivitis were 52.0 (16.2) years and 43.5 (14.0) years, respectively, with the majority of study participants being females (78.6%), Caucasian (88.2%), and non-smokers (97.5%). The whole-mouth and interproximal baseline oral health parameters were significantly distinct between the healthy and gingivitis cohorts, as expected based on the subject inclusion criteria, with approximately 0.742 vs. 2.675 for the MGI, 2.592 vs. 3.107 for the TPI, 0.012 vs. 0.326 for the EBI, and 0.869 vs. 2.186 for the PPD ( p- values < 0.001).

Study design flow chart and subject recruitment
Bacterial profiling of supragingival plaque
Metagenomic sequencing of supragingival plaque identified a total of 574 unique taxa at the species level (Table 2 ). Extensive clinical and scientific literature reviews of species identities helped to classify these taxa with clinical relevance (Additional File 1). At the study level, 236 species were identified as belonging to the human oral cavity, 228 were identified as transient or extraoral, and the remaining 109 were unknown or unclassified. At the individual subject level, there were, on average, 155 distinct species, of which 120 were identified as oral residents, nine were found to be transient or extraoral, and 26 were unknown or unclassified. While certain oral bacterial species overlapped across different categories, approximately 91 were commensal, whereas 28 were associated with gingivitis, 16 with malodor, and six with acidogenesis. No statistically significant differences in the species classification were observed between the healthy and gingivitis cohorts (Table 2 , p - values > 0.512).
Healthy vs. gingivitis supragingival plaque microbiota
Despite significant differences in the mean demographic age ( p = 0.012) and clinical oral health parameters between the periodontally healthy and gingivitis cohorts (Table 1 ), microbiome analysis of supragingival plaque at subject recruitment showed no statistically significant differences in α-diversity measures, such as the Shannon-Weaver Diversity Index (Fig. 2 b, p = 0.336) or observed species richness (Fig. 2 c, p = 0.147), as well as β-diversity using weighted UniFrac PCoA analysis (Fig. 3 Baseline Visit). This compositional similarity coincided with the baseline whole-mouth and interproximal mean TPI scores showing the least amount of differentiation (Table 1 , Δ = 0.5) compared to MGI or EBI (Table 1 , Δ = 2 or 3). Quantification of total plaque bacteria, however, showed that healthy subjects had significantly lower abundances compared to subjects with gingivitis (Fig. 2 a, p = 0.012). A detailed low-level comparison of individual bacteria demonstrated that 36 species were significantly more abundant in subjects with gingivitis than in healthy subjects (Table 3 ).
Impact of the oral care regimen on supragingival plaque
Quantitative analysis of supragingival plaque collected from subjects with gingivitis revealed significant differences between the mechanical and chemotherapeutic actions of oral care regimen after 4 weeks and 12 weeks. Specifically, compared to B, BF had no effects on Shannon-Weaver Diversity, observed species richness, total bacteria abundance, and β-diversity assessed by weighted UniFrac, showing lack of antimicrobial control against supragingival plaque (Figs. 2 and 3, BF vs. B). Further detailed analyses demonstrated that BF had no effects against commensal, gingivitis, malodor, or acidogenic groups of bacteria (Fig. 4 , BF vs. B). Moreover, at the individual species level, there were no significant differences in bacterial abundances between the BF and B groups except for 11 commensal species, which increased in abundance after 12 weeks (Table 4 , BF vs. B). The clinical endpoint measures for plaque also showed no statistically significant differences between B and BF [ 22 ] using interproximal mean TPI at week 4 ( p = 0.696) and at week 12 ( p = 0.164) and whole-mouth mean TPI at week 4 ( p = 0.430) and at week 12 ( p = 0.229).

Microbiome assessment of supragingival plaque. The means of ( a ) total oral bacteria abundance in log10 CMU, ( b ) Shannon-Weaver diversity index, and ( c ) observed species richness are shown. Dots represent individual samples. ns = not significant, * p < 0.05, ** p < 0.01, *** p < 0.001

Weighted UniFrac principal coordinate analysis demonstrating time-resolved changes in the beta-diversity of the supragingival plaque microbiome after 4 weeks and 12 weeks of oral care regimen

Impact of the oral care regimen on the supragingival plaque microbiome. The mean abundances of bacterial species that are ( a ) oral commensal, ( b ) associated with gingivitis, ( c ) producing volatile sulfur compounds, and ( d ) acidogenic are shown. Error bars represent the standard error of the mean. ns = not significant, * p < 0.05, ** p < 0.01, *** p < 0.001
In contrast, however, the mouthrinse containing BA, BZ, and BFZ groups had significant reductions in Shannon-Weaver Diversity, observed species richness, and total bacteria compared to the B or BF groups (Figs. 2 and 3, BA, BZ, BFZ). Complete eradication of the supragingival plaque microbiota was not observed, but the results showed attenuated α-diversity and bacterial abundances consistent with microbial ecology curtailed of biomass accumulation. Amongst the mouthrinsing groups, impact assessment against clinically relevant groups of bacteria revealed that the BA group had greater bacterial reductions than the BZ and BFZ groups, likely arising from differences in formulations (Fig. 4 ). Comparisons versus the BF group showed that, after 4 and 12 weeks, BA significantly reduced bacterial abundances by 82.0% and 75.4% for commensal species, 93.6% and 91.3% for gingivitis species, and 88.5% and 85.2% for malodor species, respectively. BZ, on the other hand, significantly reduced bacterial abundances by 58.2% and 46.6% for commensal species, 85.8% and 80.2% for gingivitis species, and 68.5% after 4 weeks for malodor species after 4 and 12 weeks, respectively. While there were no statistically significant differences between the BZ and BFZ groups, comparisons versus the BF group showed that BFZ significantly reduced bacterial abundances for commensal species by 52.6% after 4 weeks; 84.5% and 75.9% for gingivitis species after 4 weeks and 12 weeks, respectively; and 60.7% for malodor species after 4 weeks. A detailed list of the individual bacterial species significantly impacted by the oral care regimen is presented in Table 4 . No effects were observed against acidogenic bacteria (Fig. 4 d), which were poorly represented in the collected specimens (Table 4 , acidogenic species), likely owing to the trial exclusion of subjects with active caries or significant carious lesions. The clinical endpoint measures for plaque showed statistically significant reductions for the mouthrinse containing BA, BZ, BFZ groups after 4 weeks and 12 weeks when compared to B using interproximal mean and whole-mouth mean TPI scores ( p < 0.001) with BA showing the largest degree of reduction while BZ and BFZ showed similar reductions [ 22 ].
Enumeration of viable bacteria on supragingival and subgingival plaque
Live bacteria that remained in the plaque were quantified using vPCR targeting total bacteria and three indicator species for precise comparisons of the oral care regimen after 12 weeks (Fig. 5 ). While very low abundances of live P. gingivalis were detected throughout, the results showed marked differences in antimicrobial control based on the plaque location and mechanical and chemotherapeutic actions of the oral care regimen. In supragingival plaque, BF had no effects, while BA, BZ, and BFZ significantly reduced total bacteria and indicator species similarly to metagenome sequencing results (Fig. 5 a; Table 4 ). A synergistic effect of combining flossing and rinsing (BFZ) was observed against F. nucleatum and P. gingivalis (Fig. 5 a, BFZ). In subgingival plaque, flossing (BF) and mouthrinsing (BA, BZ) by themselves generally had no effects against total bacteria and indicator species, except for flossing (BF) against P. gingivalis (Fig. 5 b). However, synergy was observed for the combined flossing and rinsing regimen (BFZ) against total bacteria, F. nucleatum , and P. gingivalis (Fig. 5 b, BFZ). While the supragingival vPCR results provided support for the quantitative microbiome analysis, the subgingival vPCR results also showed the same trend in clinical endpoint measures for the whole-mouth mean and interproximal mean EBI and MGI scores [ 22 ]. The clinical scores showed BF and mouthrinse containing BA, BZ and BFZ groups significantly reduced bleeding and inflammation after 4 weeks ( p < 0.001) and 12 weeks ( p < 0.001) with BFZ showing the largest degree of reduction reflecting the synergistic antimicrobial effect against F. nucleatum and P. gingivalis subgingivally.

Viability qPCR results demonstrating the impact of the oral care regimen on total oral bacteria and select indicator species. The means of log10 abundance from ( a ) supragingival plaque and ( b ) subgingival plaque are shown. The dots represent individual samples. ns = not significant, * p < 0.05, ** p < 0.01, *** p < 0.001
This 12-week clinical trial investigated the effects of brushing with a sodium monofluorophosphate toothpaste, plus virtually supervised flossing, and/or using EO-containing mouthrinse regimens [ 22 ] on the microbiota of supragingival and subgingival plaque. While clinical reports of superior plaque control by mouthrinses compared to flossing are on the rise [ 6 , 7 , 36 , 37 , 38 , 39 ], there is paucity of information on how plaque biofilms are affected by mechanical and chemotherapeutic means of intervention, including how constituent bacterial species and their microbial ecology respond over time.
In this trial, subjects with mild gingivitis used specific oral care regimens for 4 weeks and 12 weeks and returned to the clinic for oral and microbiome evaluations 8–18 h after the last intervention. Subjects in good periodontal and general health were also included at the baseline visit in an observational capacity to determine if different signatures of supragingival plaque microbiome exist compared to the mild gingivitis cohort. While large differences were noted in the whole-mouth and interproximal mean clinical scores for MGI and EBI, TPI showed the least amount of differentiation (Table 1 ) between these cohorts at recruitment and no significant high-level differences were noted in their microbiome compositions using the α- and β- diversity results (Fig. 2 b, c and 3 baseline visit). Total bacterial abundance results, however, showed the mild gingivitis subjects significantly had 44% higher overall abundance compared to the healthy cohort (Fig. 2 A baseline, Δ = 0.25, p = 0.012) with detailed low-level comparisons showing the presence of 36 species that were more abundant in gingivitis subjects (Table 3 ). There were no clearly differentiated microbial clusters of health vs. disease recognizable of Socransky’s subgingival plaque microbial complexes [ 17 ] or Kolenbrander’s coaggregation-based ecological succession [ 40 ] observed in this study population. However, these results demonstrate the importance of biomass accumulation in mild gingivitis subjects which is seldom investigated using relative abundance analysis offered by conventional next-generation DNA sequencing-based approach and point to the presence of different grades of periodontally healthy and early gingivitis states that show large degree of similarity in qualitative microbial diversity assessments.
The plaque microbiota represented in this mild gingivitis population exhibited both long-term accumulated product intervention effects and a short period of bacterial regrowth and recolonization. The quantitative results of supragingival plaque confirmed that daily brushing and flossing alone were insufficient to effectively manage plaque above the gingival margin (Figs. 2, 3 and 5 a and a). These supragingival plaque microbiome results closely mirrored the clinical endpoint measures of interproximal mean and whole-mouth mean TPI scores [ 22 ]. Notably, the mechanical removal of supragingival plaque by brushing or flossing is likely unable to achieve sustained plaque reductions due to the rapid recolonization of plaque bacteria [ 41 ] seeded from unaffected areas of the mouth. The results of the current trial, which showed a lack of significant differences in the microbiome diversity, species richness, and total and individual bacterial abundances between brushing only and brushing and flossing regimens, support this hypothesis (B vs. BF in Figs. 2, 3 and 5 a and a; Table 4 ).
Alcohol and non-alcohol EO-containing mouthrinses demonstrated effective and sustained chemotherapeutic means of managing supragingival plaque by maintaining reduced levels of microbiome diversity and bacterial abundances (BA, BZ, BFZ in Figs. 2, 3 and 5 a and a; Table 4 ). This result is consistent with historically published randomized controlled trials with clinical endpoints of plaque and gingivitis efficacy [ 4 , 5 , 38 , 42 ]. Given the results observed in this trial and the evidence base in the literature to date, we propose the following hypothesis regarding a sequence of three distinct mechanistic actions taking place against the supragingival plaque microbiome. First, 99.9% of plaque bacteria are killed within 30 s of contact [ 43 , 44 , 45 ], as EOs are able to penetrate thick layers of biofilms [ 46 ]. This bactericidal effect, however, is not permanent, since no complete eradication of plaque microbiota is achieved, consistent with total bacteria abundance results from the present trial and the published body of bacterial colony counting data from past clinical studies [ 5 , 11 , 13 , 38 ]. Second, given the different antimicrobial properties of EOs compared to cationic antimicrobials that have substantivity, such as chlorhexidine gluconate or cetylpyridinium chloride [ 47 , 48 , 49 , 50 ], there is an attenuated level of bacterial re-seeding taking place from other areas of the mouth that facilitates plaque recolonization within a few hours. This nascent plaque is enriched with commensal bacteria, while pathogenic species associated with gingivitis or malodor are impeded due to their slow growth rates [ 51 , 52 ]. The late-colonizing pathogenic species have specific requirements for metabolic and structural support from secondary and tertiary coaggregating partner species during dental plaque biofilm development [ 17 , 53 , 54 , 55 ]. Our study results corroborate a large presence of commensal bacteria compared to gingivitis or malodor associated bacteria after mouthrinsing regimens (Fig. 4 , cca. 0.3–1.1 × 10 8 commensal versus cca. 1.5–3.8 × 10 6 for gingivitis or malodor associated bacteria). Third, repeated twice-daily usage of EO mouthrinses helps to continually curtail plaque build-up, which prevents the maturation of biofilm and proliferation of pathogenic species associated with gingivitis and malodor, and lowers the total bacterial bioburden contributing to the maintenance of a health-associated stable oral microbial community or eubiosis (Table 4 ; Fig. 2 a).
The analysis of subgingival plaque in this study indicated a potentially important contribution of mechanical flossing in oral health maintenance. Viable bacteria enumeration by vPCR showed that flossing can act synergistically with mouthrinsing to reduce total bacteria and F. nucleatum below the gingival margin (Fig. 5 b, BFZ) and can selectively exert significant control against P. gingivalis (Fig. 5 b, BF). Interestingly, these subgingival plaque vPCR results were also observed in the clinical endpoint measures of bleeding and inflammation as assessed using the interproximal and whole-mouth mean EBI and MGI scores [ 22 ] which provides support for the importance of mechanical flossing controlling subgingival plaque in synergy with mouthrinsing. This finding also supports other previous studies that demonstrated clinical improvements in gingival inflammation and bleeding scores despite poor plaque reduction by flossing [ 6 , 7 , 36 , 37 , 38 , 39 ] and sheds light on how specific oral care regimens differentially affect distinct communities of the oral microbiome. Further quantitative research is required to understand the ability of different oral care regimens and products to reach not only subgingival plaque but also other oral surfaces, such as the gingiva, cheeks, tongue, oropharynx, and saliva. In addition, immunological evaluation of pro- and anti-inflammatory cytokines with respect to the microbial community clusters that exist during the progression of different gradation of periodontal health and disease are important considerations for future studies to better understand the dynamic nature of microbial recolonization. Such a detailed assessment of microbial ecology is of significant interest for public health, as many oral bacterial species are implicated in various systemic health or disease conditions.
The results of this 12-week randomized clinical trial provide numerical details of how mechanical and chemotherapeutic oral care regimens affect supragingival and subgingival microbiota. Brushing with a sodium monofluorophosphate toothpaste and flossing with a non-antimicrobial waxed dental floss alone do not appear to provide adequate control of plaque above and below the gingival margin, as constituent bacteria were unaffected, and there were no significant differences in bacterial abundances compared to the brushing control (Figs. 2 , 4 and 5 ; Table 4 , BF vs. B). However, alcohol and non-alcohol EO mouthrinses effectively managed supragingival plaque via a quick chemotherapeutic bactericidal mechanism of action, which appeared to be short-termed and allowed attenuated plaque regrowth enriched with commensal species (Figures, 2, 4, 5a, Table 4 , BA, BZ). Furthermore, analysis of subgingival plaque when flossing is used in combination with mouthrinsing seemed to implicate a role for mechanical flossing in enabling the antimicrobial effectiveness of EO mouthrinses below the gingival margin (Fig. 5 b, BFZ). In conclusion, this trial highlights the superior efficacy of EO mouthrinses at controlling plaque without adversely affecting its microbial ecology and elevates the role of alcohol and non-alcohol EO-containing mouthrinses beyond flossing, in conjunction with toothbrushing.
Data availability
Shotgun metagenomic sequence data and sample metadata information are available in the NCBI BioProject database under accession number PRJNA984617.
Abbreviations
Brushing only
Brushing and flossing
Brushing and rinsing with Listerine® Cool Mint® Antiseptic
Brushing, flossing, and rinsing with Listerine® Cool Mint® Zero Alcohol
Brushing and rinsing with Listerine® Cool Mint® Zero Alcohol
Expanded bleeding index
Essential oil
Modified gingival index
Not significant
Principal coordinate analysis
- Propidium monoazide
Periodontal pocket depth
Turesky Plaque Index
Viability polymerase chain reaction
Valm AM. The structure of Dental Plaque Microbial communities in the transition from Health to Dental Caries and Periodontal Disease. J Mol Biol. 2019;431(16):2957–69.
Article CAS PubMed PubMed Central Google Scholar
National Dental Association - Minutes of the Executive Council. Report of the special committee on revision of the hygiene report - the mouth and the teeth. Transactions of the National Dental Association. Philadelphia: Press of the ‘Dental Cosmos’; 1909. pp. 17–9.
Google Scholar
Worthington HV, MacDonald L, Poklepovic Pericic T, Sambunjak D, Johnson TM, Imai P, Clarkson JE. Home use of interdental cleaning devices, in addition to toothbrushing, for preventing and controlling periodontal diseases and dental caries. Cochrane Database Syst Rev. 2019;4(4):CD012018.
PubMed Google Scholar
Araujo MWB, Charles CA, Weinstein RB, McGuire JA, Parikh-Das AM, Du Q, Zhang J, Berlin JA, Gunsolley JC. Meta-analysis of the effect of an essential oil-containing mouthrinse on gingivitis and plaque. J Am Dent Assoc. 2015;146(8):610–22.
Article PubMed Google Scholar
Sharma N, Charles CH, Lynch MC, Qaqish J, McGuire JA, Galustians JG, Kumar LD. Adjunctive benefit of an essential oil-containing mouthrinse in reducing plaque and gingivitis in patients who brush and floss regularly: a six-month study. J Am Dent Assoc. 2004;135(4):496–504.
Article CAS PubMed Google Scholar
Bosma ML, McGuire JA, Sunkara A, Sullivan P, Yoder A, Milleman J, Milleman K. Efficacy of Flossing and Mouthrinsing regimens on Plaque and Gingivitis: a randomized clinical trial. J Dent Hyg. 2022;96(3):8–20.
Milleman J, Bosma ML, McGuire JA, Sunkara A, McAdoo K, DelSasso A, Wills K, Milleman K. Comparative effectiveness of Toothbrushing, Flossing and Mouthrinse regimens on Plaque and Gingivitis: a 12-week virtually supervised clinical trial. J Dent Hyg. 2022;96(3):21–34.
Lynch MC, Cortelli SC, McGuire JA, Zhang J, Ricci-Nittel D, Mordas CJ, Aquino DR, Cortelli JR. The effects of essential oil mouthrinses with or without alcohol on plaque and gingivitis: a randomized controlled clinical study. BMC Oral Health. 2018;18(1):6.
Article PubMed PubMed Central Google Scholar
Cortelli SC, Cortelli JR, Shang H, McGuire JA, Charles CA. Long-term management of plaque and gingivitis using an alcohol-free essential oil containing mouthrinse: a 6-month randomized clinical trial. Am J Dent. 2013;26(3):149–55.
Fine DH, Furgang D, Barnett ML, Drew C, Steinberg L, Charles CH, Vincent JW. Effect of an essential oil-containing antiseptic mouthrinse on plaque and salivary Streptococcus mutans levels. J Clin Periodontol. 2000;27(3):157–61.
Fine DH, Furgang D, Sinatra K, Charles C, McGuire A, Kumar LD. In vivo antimicrobial effectiveness of an essential oil-containing mouth rinse 12 h after a single use and 14 days’ use. J Clin Periodontol. 2005;32(4):335–40.
Fine DH, Markowitz K, Furgang D, Goldsmith D, Charles CH, Lisante TA, Lynch MC. Effect of an essential oil-containing antimicrobial mouthrinse on specific plaque bacteria in vivo. J Clin Periodontol. 2007;34(8):652–7.
Fine DH, Markowitz K, Furgang D, Goldsmith D, Ricci-Nittel D, Charles CH, Peng P, Lynch MC. Effect of rinsing with an essential oil-containing mouthrinse on subgingival periodontopathogens. J Periodontol. 2007;78(10):1935–42.
Fine JB, Harper DS, Gordon JM, Hovliaras CA, Charles CH. Short-term microbiological and clinical effects of subgingival irrigation with an antimicrobial mouthrinse. J Periodontol. 1994;65(1):30–6.
Minah GE, DePaola LG, Overholser CD, Meiller TF, Niehaus C, Lamm RA, Ross NM, Dills SS. Effects of 6 months use of an antiseptic mouthrinse on supragingival dental plaque microflora. J Clin Periodontol. 1989;16(6):347–52.
Socransky SS, Haffajee AD, Smith C, Martin L, Haffajee JA, Uzel NG, Goodson JM. Use of checkerboard DNA-DNA hybridization to study complex microbial ecosystems. Oral Microbiol Immunol. 2004;19(6):352–62.
Socransky SS, Haffajee AD, Cugini MA, Smith C, Kent RL Jr. Microbial complexes in subgingival plaque. J Clin Periodontol. 1998;25(2):134–44.
Aas JA, Paster BJ, Stokes LN, Olsen I, Dewhirst FE. Defining the normal bacterial flora of the oral cavity. J Clin Microbiol. 2005;43(11):5721–32.
Carda-Dieguez M, Bravo-Gonzalez LA, Morata IM, Vicente A, Mira A. High-throughput DNA sequencing of microbiota at interproximal sites. J Oral Microbiol. 2020;12(1):1687397.
Zaura E, Keijser BJ, Huse SM, Crielaard W. Defining the healthy core microbiome of oral microbial communities. BMC Microbiol. 2009;9:259.
Min K, Glowacki AJ, Bosma ML, McGuire JA, Tian S, McAdoo K, DelSasso A, Fourre T, Gambogi RJ, Milleman J, et al. Quantitative analysis of the effects of essential oil mouthrinses on clinical plaque microbiome: a parallel-group, randomized trial. Johnson & Johnson Consumer Inc; 2024.
Bosma ML, McGuire JA, DelSasso A, Milleman J, Milleman K. Efficacy of flossing and mouth rinsing regimens on plaque and gingivitis: a randomized clinical trial. BMC Oral Health. 2024;24(1):178.
Lobene RR, Weatherford T, Ross NM, Lamm RA, Menaker L. A modified gingival index for use in clinical trials. Clin Prev Dent. 1986;8(1):3–6.
CAS PubMed Google Scholar
Ainamo J, Bay I. Problems and proposals for recording gingivitis and plaque. Int Dent J. 1975;25(4):229–35.
Chilton NW. Studies in the design and analysis of dental experiments. II. A four-way analysis of variance. J Dent Res. 1960;39:344–60.
Saxton CA, van der Ouderaa FJ. The effect of a dentifrice containing zinc citrate and Triclosan on developing gingivitis. J Periodontal Res. 1989;24(1):75–80.
Van der Weijden GA, Timmerman MF, Nijboer A, Reijerse E, Van der Velden U. Comparison of different approaches to assess bleeding on probing as indicators of gingivitis. J Clin Periodontol. 1994;21(9):589–94.
Turesky S, Gilmore ND, Glickman I. Reduced plaque formation by the chloromethyl analogue of victamine C. J Periodontol. 1970;41(1):41–3.
Team RDC. R: A language and environment for statistical computing. In. Vienna, Austria: R Foundation for Statistical Computing; 2021.
Oksanen JB, Friendly FG, Kindt M, Legendre R, McGlinn P, Minchin D, O’Hara PR, Simpson RB, Solymos GL, Stevens P, Szoecs HH, Wagner E. Vegan: Community Ecology Package. In. 2020;2:5–6.
McMurdie PJ, Holmes S. Phyloseq: an R package for reproducible interactive analysis and graphics of microbiome census data. PLoS ONE. 2013;8(4):e61217.
Lozupone C, Lladser ME, Knights D, Stombaugh J, Knight R. UniFrac: an effective distance metric for microbial community comparison. ISME J. 2011;5(2):169–72.
Anderson MJ. A new method for non-parametric multivariate analysis of variance. Austral Ecol. 2001;26(1):32–46.
Sayers EW, Cavanaugh M, Clark K, Pruitt KD, Schoch CL, Sherry ST. Karsch-Mizrachi I: GenBank. Nucleic Acids Res. 2021;49(D1):D92–6.
Dewhirst FE, Chen T, Izard J, Paster BJ, Tanner AC, Yu WH, Lakshmanan A, Wade WG. The human oral microbiome. J Bacteriol. 2010;192(19):5002–17.
Arora V, Tangade P, Tirth TLR, Pal A, Tandon S. Efficacy of dental floss and chlorhexidine mouth rinse as an adjunct to toothbrushing in removing plaque and gingival inflammation - a three way cross over trial. J Clin Diagn Res. 2014;8(10):ZC01–04.
PubMed PubMed Central Google Scholar
Luis HS, Luis LS, Bernardo M, Dos Santos NR. Randomized controlled trial on mouth rinse and flossing efficacy on interproximal gingivitis and dental plaque. Int J Dent Hyg. 2018;16(2):e73–8.
Sharma NC, Charles CH, Qaqish JG, Galustians HJ, Zhao Q, Kumar LD. Comparative effectiveness of an essential oil mouthrinse and dental floss in controlling interproximal gingivitis and plaque. Am J Dent. 2002;15(6):351–5.
Zimmer S, Kolbe C, Kaiser G, Krage T, Ommerborn M, Barthel C. Clinical efficacy of flossing versus use of antimicrobial rinses. J Periodontol. 2006;77(8):1380–5.
Kolenbrander PE. Intergeneric coaggregation among human oral bacteria and ecology of dental plaque. Annu Rev Microbiol. 1988;42:627–56.
Wake N, Asahi Y, Noiri Y, Hayashi M, Motooka D, Nakamura S, Gotoh K, Miura J, Machi H, Iida T, et al. Temporal dynamics of bacterial microbiota in the human oral cavity determined using an in situ model of dental biofilms. NPJ Biofilms Microbiomes. 2016;2:16018.
Bauroth K, Charles CH, Mankodi SM, Simmons K, Zhao Q, Kumar LD. The efficacy of an essential oil antiseptic mouthrinse vs. dental floss in controlling interproximal gingivitis: a comparative study. J Am Dent Assoc. 2003;134(3):359–65.
Fine DH, Letizia J, Mandel ID. The effect of rinsing with listerine antiseptic on the properties of developing dental plaque. J Clin Periodontol. 1985;12(8):660–6.
Kubert D, Rubin M, Barnett ML, Vincent JW. Antiseptic mouthrinse-induced microbial cell surface alterations. Am J Dent. 1993;6(6):277–9.
Pan P, Barnett ML, Coelho J, Brogdon C, Finnegan MB. Determination of the in situ bactericidal activity of an essential oil mouthrinse using a vital stain method. J Clin Periodontol. 2000;27(4):256–61.
Ouhayoun JP. Penetrating the plaque biofilm: impact of essential oil mouthwash. J Clin Periodontol. 2003;30(Suppl 5):10–2.
Jenkins S, Addy M, Wade W, Newcombe RG. The magnitude and duration of the effects of some mouthrinse products on salivary bacterial counts. J Clin Periodontol. 1994;21(6):397–401.
Mandel ID. Chemotherapeutic agents for controlling plaque and gingivitis. J Clin Periodontol. 1988;15(8):488–98.
Marchetti E, Mummolo S, Di Mattia J, Casalena F, Di Martino S, Mattei A, Marzo G. Efficacy of essential oil mouthwash with and without alcohol: a 3-day plaque accumulation model. Trials. 2011;12:262.
Tomas I, Cousido MC, Garcia-Caballero L, Rubido S, Limeres J, Diz P. Substantivity of a single chlorhexidine mouthwash on salivary flora: influence of intrinsic and extrinsic factors. J Dent. 2010;38(7):541–6.
Kolenbrander PE, London J. Adhere today, here tomorrow: oral bacterial adherence. J Bacteriol. 1993;175(11):3247–52.
Periasamy S, Kolenbrander PE. Central role of the early colonizer Veillonella sp. in establishing multispecies biofilm communities with initial, middle, and late colonizers of enamel. J Bacteriol. 2010;192(12):2965–72.
Hojo K, Nagaoka S, Ohshima T, Maeda N. Bacterial interactions in dental biofilm development. J Dent Res. 2009;88(11):982–90.
Kolenbrander PE, Palmer RJ Jr., Periasamy S, Jakubovics NS. Oral multispecies biofilm development and the key role of cell-cell distance. Nat Rev Microbiol. 2010;8(7):471–80.
Kolenbrander PE, Andersen RN, Blehert DS, Egland PG, Foster JS, Palmer RJ Jr. Communication among oral bacteria. Microbiol Mol Biol Rev. 2002;66(3):486–505. table of contents.
Download references
Acknowledgements
The authors gratefully acknowledge Michael Lynch and Marsha Tharakan for manuscript writing support and review, Kathleen Boyle for manuscript submission, and Kaylie Wills, BSDH for clinical trial coordination.
This trial was funded by Johnson & Johnson Consumer, Inc. (JJCI; Skillman, NJ, USA).
Author information
Authors and affiliations.
Johnson & Johnson Consumer Inc, 199 Grandview Rd, Skillman, NJ, USA
Kyungrok Min, Mary Lynn Bosma, Gabriella John, James A. McGuire & Alicia DelSasso
Salus Research, Inc, 1220 Medical Park Drive, Building 4, Fort Wayne, IN, USA
Jeffery Milleman & Kimberly R. Milleman
You can also search for this author in PubMed Google Scholar
Contributions
MLB, GJ, KM, and JAM contributed to the study conception and design. JM and KRM executed the clinical trial. ADS contributed to clinical protocol writing, trial management, and supervision. KM carried out bioinformatic processing of microbiome data. KM and JAM performed data analysis and interpretation. JAM performed statistical analysis. KM wrote the manuscript. All co-authors reviewed the manuscript.
Corresponding author
Correspondence to Kyungrok Min .
Ethics declarations
Consent for publication.
Not applicable.
Competing interests
This trial was sponsored by Johnson & Johnson Consumer Inc., (JJCI; Skillman, NJ, USA). KM, MLB, GJ, JAM, and AD contributed to the study while employed by JJCI. JM and KRM are directors at Salus Research, Inc. (Fort Wayne, IN, USA), an independent research site approved by the American Dental Association. JM and KRM received grants from JJCI and conducted the trial on behalf of JJCI. JM and KRM declare no conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval and consent to participate
The study protocol, informed consent documents, and study materials were reviewed and approved by Veritas IRB, Inc. (Quebec, Canada), an independent third-party research ethics committee, on April 04, 2022, reference number 2022-3010-10278-1. Written informed consent was obtained from all subjects. The CONSORT statement was followed for the reporting of this randomized clinical trial.
JM and KRM are directors at Salus Research, Inc. (Fort Wayne, IN, USA), an independent research site approved by the American Dental Association. JM and KRM received grants from JJCI and conducted the trial on behalf of JJCI. JM and KRM declare no conflicts of interest with respect to the research, authorship, and/or publication of this article.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Min, K., Bosma, M.L., John, G. et al. Quantitative analysis of th e effects of brushing, flossing, and mouthrinsing on supragingival and subgingival plaque microbiota: 12-week clinical trial. BMC Oral Health 24 , 575 (2024). https://doi.org/10.1186/s12903-024-04362-y
Download citation
Received : 23 August 2023
Accepted : 10 May 2024
Published : 17 May 2024
DOI : https://doi.org/10.1186/s12903-024-04362-y
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Oral microbiome
- Dental plaque
BMC Oral Health
ISSN: 1472-6831
- Submission enquiries: [email protected]
- General enquiries: [email protected]
- Open access
- Published: 06 May 2024
Identification and characterization of whole blood gene expression and splicing quantitative trait loci during early to mid-lactation of dairy cattle
- Yongjie Tang 1 ,
- Jinning Zhang 1 ,
- Wenlong Li 1 ,
- Xueqin Liu 1 ,
- Siqian Chen 1 ,
- Siyuan Mi 1 ,
- Jinyan Yang 1 ,
- Jinyan Teng 3 ,
- Lingzhao Fang 2 &
- Ying Yu 1
BMC Genomics volume 25 , Article number: 445 ( 2024 ) Cite this article
302 Accesses
Metrics details
Characterization of regulatory variants (e.g., gene expression quantitative trait loci, eQTL; gene splicing QTL, sQTL) is crucial for biologically interpreting molecular mechanisms underlying loci associated with complex traits. However, regulatory variants in dairy cattle, particularly in specific biological contexts (e.g., distinct lactation stages), remain largely unknown. In this study, we explored regulatory variants in whole blood samples collected during early to mid-lactation (22–150 days after calving) of 101 Holstein cows and analyzed them to decipher the regulatory mechanisms underlying complex traits in dairy cattle.
We identified 14,303 genes and 227,705 intron clusters expressed in the white blood cells of 101 cattle. The average heritability of gene expression and intron excision ratio explained by cis -SNPs is 0.28 ± 0.13 and 0.25 ± 0.13, respectively. We identified 23,485 SNP-gene expression pairs and 18,166 SNP-intron cluster pairs in dairy cattle during early to mid-lactation. Compared with the 2,380,457 cis -eQTLs reported to be present in blood in the Cattle Genotype-Tissue Expression atlas (CattleGTEx), only 6,114 cis -eQTLs ( P < 0.05) were detected in the present study. By conducting colocalization analysis between cis -e/sQTL and the results of genome-wide association studies (GWAS) from four traits, we identified a cis -e/sQTL (rs109421300) of the DGAT1 gene that might be a key marker in early to mid-lactation for milk yield, fat yield, protein yield, and somatic cell score (PP4 > 0.6). Finally, transcriptome-wide association studies (TWAS) revealed certain genes (e.g., FAM83H and TBC1D17 ) whose expression in white blood cells was significantly ( P < 0.05) associated with complex traits.
Conclusions
This study investigated the genetic regulation of gene expression and alternative splicing in dairy cows during early to mid-lactation and provided new insights into the regulatory mechanisms underlying complex traits of economic importance.
Peer Review reports
Thousands of genetic variants were discovered to be associated with complex traits in cattle through genome-wide association studies (GWAS) [ 1 ]. However, most of these variants are not coding variants; therefore, understanding the molecular mechanisms behind these GWAS loci is challenging [ 2 ]. Previous studies have shown that genetic variation can affect gene expression and splicing, often termed gene expression quantitative trait loci (eQTL) and splicing QTL (sQTL). This has led to a focus on two important classes of regulatory variants [ 3 ]. Identification of eQTL and sQTL is important for understanding the relationship between regulatory variants and complex traits and has acquired progress in bovine studies. FarmGTEx consortium built a Cattle Genotype-Tissue Expression atlas (CattleGTEx) which included numerous eQTLs and sQTLs associated with complex traits in different tissues [ 4 ]. Additionally, the eQTL and sQTL explained a large proportion of the heritability of complex traits in cattle [ 5 ]. However, little is known about how allelic variation affects regulatory interactions during early to mid-lactation in dairy cattle.
Critically, the genetic effect of regulatory variants is highly context-dependent [ 6 , 7 ], consistent with transcriptional surveys of dairy cow lactation that show prominent temporal changes in gene expression [ 8 , 9 ]. Early to mid-lactation is the key period in the dynamic lactation process of dairy cows, and determines milk production and health performance [ 10 , 11 ], thus highlighting the need to identify regulatory variation within this critical time point. As whole blood is the most easily obtained specimen, it is widely used to comprehensively study the mechanisms of complex traits. Whole blood can reflect the physiological conditions of cows as it is responsible for transporting various substances used in milk production [ 12 ]. Some studies have shown that individuals with different milk production performances have different gene expression levels, and potential molecular biomarkers in the blood transcriptome related to milk performance traits have been identified [ 12 , 13 ]. In addition, blood leukocytes are widely used as immune cells in transcriptional surveys of health traits, such as mastitis [ 14 ] and ketosis [ 15 ]. Notably, the identification of regulatory QTLs using whole blood has also revealed a correlation between the genetic effects of blood and other tissues [ 2 , 16 ]. The genetic effect of some regulatory QTLs is shared among different tissues [ 3 , 17 , 18 , 19 ].
Therefore, the aim of this study was to identify eQTL and sQTL in the early to mid-lactation period of dairy cows using whole blood and to explore their association with complex traits. We hope that this study will provide insight into changes observed in the effects of genes on complex traits during lactation from the perspective of the regulatory roles that some variants play in gene expression and splicing.
Identification of factors affecting gene expression and intron excision ratio
In this study, whole blood leukocytes from 104 Holstein cattle in early to mid-lactation (22–150 days after calving) were genotyped and RNA-Seq was performed. After quality control and normalization of gene expression and genotypes, 95,799 SNPs, 14,303 genes and 227,705 intron clusters from 101 individuals were obtained for eQTL and sQTL identification and characterization [Additional file 2, Figure S1 ].
As an intermediate molecular phenotype, transcripts are affected by confounding factors such as batch effects and biological and technical factors [ 4 , 6 ]. The results suggested that the week of lactation, parity and RIN showed stronger correlations with gene expression principal components (EPCs) and intron excision ratio principal components (SPCs) than blood cell counts [Additional file 2, Figure S2 ]. In addition to the above-mentioned known factors affecting transcription level changes, the PEER software was used to identify unknown confounding factors (PEER factors) [ 4 , 20 ]. The factor weight variances near zero when the number of hidden PEER factors inferred from gene expression and intron cluster expression reached 10 and 8, respectively [Additional file 2, Figure S3 ]. Therefore, the top ten PEER factors were removed from the eQTL discovery, and the top eight PEER factors were removed from sQTL discovery.
Heritability of gene expression and intron excision ratios
Gene expression and intron excision ratios with heritability ( h 2 ) > 0 and P < 0.05, respectively, were considered heritable. There are 4,604 genes whose expression with heritability that can be explained by cis -SNPs ( h 2 > 0, P < 0.05), and the heritability was 0.28 ± 0.13 (mean ± standard deviations). Meanwhile, there are 21,983 intron excision ratios with heritability that can be explained by cis -SNPs ( h 2 > 0, P < 0.05), and the heritability was 0.25 ± 0.13 [Additional file 2, Figure S4 ].
Identification of cis -eQTLs and cis -sQTLs during early to mid-lactation of dairy cows
FastQTL was used to identify cis -eQTL and cis -sQTL, adjusting for known (week of lactation, parity, RIN, and genotype PCs) and inferred covariates (PEER factors). This resulted in 23,485 SNP-gene expression pairs ( FDR < 0.05) [Additional file 1, Table S1 ] and 18,166 SNP-intron cluster pairs ( FDR < 0.05) [Additional file 1, Table S2 ]. Among them, 3,419 genes had significant eQTL and 3,127 genes had significant sQTL, hereafter referred to as eGenes and sGenes respectively.
Differences in genomic features between eQTLs and sQTLs
The overlap of eQTLs with sQTLs was further analyzed, as well as for eGenes and sGenes. The results suggested that nearly half of the sQTLs (approximately 49.1%) were not eQTL and approximately 62.5% of the eQTLs were independent (Fig. 1 a). In addition, only 34.4% of the eGenes were also sGenes and 37.6% of the sGenes were also eGenes (Fig. 1 b). Even when the eGene was also an sGene, the lead QTL SNPs distances were mostly between 10 kb and 1 Mb [Additional file 2, Figure S5 a] and in low linkage disequilibrium (LD) r 2 [Additional file 2, Figure S5 b].

Comparison of cis -eQTLs and cis -sQTLs characterization. ( a ) Overlap of eQTLs and sQTLs. ( b ) Overlap of eGenes and sGenes. ( c ) Distance of eQTL in early-mid lactation dairy cows relative to TSS of eGene. Each point represents an eVariant-eGene pair ( FDR < 0.05). ( d ) Distance of sQTL relative to splice junction of targeted intron cluster. Each point represents an sVariant-sGene pair. ( FDR < 0.05). ( e ) Enrichment (Fisher’s exact test) of eQTLs and sQTLs with 13 chromatin states in the spleen, respectively. The point and error bars indicate the odds ratio and 95% CI. ( f) Enrichment (Fisher’s exact test) of eQTLs and sQTLs with Ensembl VEP-predicted SNP effects, respectively. The point and error bars indicate the odds ratio and 95% CI
Next, the results suggest that most of the eQTLs were located near the TSS and were more significant than others (Fig. 1 c), whereas the sQTLs tended to be located near the splice junction (Fig. 1 d). Therefore, the results suggest that genetic variation near the TSS (promoter, etc.) has a large effect on cognate gene expression, whereas genetic variation near the splice junction is more likely to affect gene alternative splicing. Furthermore, enrichment analysis (Fisher’s exact test) was conducted comparing the 13 chromatin states of cow spleen with eQTLs and sQTLs. It was found that eQTLs tend to be more enriched in transcriptional regulatory elements such as active enhancer and TSS compared to sQTLs (Fig. 1 e). Additionally, enrichment analysis (Fisher’s exact test) was separately performed on eQTLs and sQTLs using Ensembl VEP-predicted SNP effects, revealing that sQTLs tend to be more enriched in splicing-related regions compared to eQTLs (Fig. 1 f).
Specificity of eQTL during early to mid-lactation of dairy cows
To identify eQTLs and eGenes specific for early to mid-lactation in Holstein cows, the cis -eQTLs and eGenes were compared with the population in cGTEx. The results suggested that there were 24,075 common eQTLs and 6,114 specific eQTLs in the early to mid-lactation ( P < 0.05; Fig. 2 a). In terms of eGenes, the shared number of eGenes is 10,974, and the number of specific eGenes in early-mid lactation is 286 ( P < 0.05; Fig. 2 b). These 286 genes were enriched in metabolic pathways related to sodium, calcium and glucose transport ( P < 0.01; Fig. 2 c).

Comparison of eQTLs and eGenes in this study and GTEx. ( a ) Comparison of cis -eQTLs in early-mid lactation and cGTEx ( P < 0.05). ( b ) Comparison of eGenes in early-mid lactation and cGTEx. ( c ) GO enrichment analysis of eGenes specific to early-mid lactation in this study
Gene co-expression network of eGenes during early to mid-lactation cows
To explore the biological functions of all eGenes during early to mid-lactation cows in this study, 3,419 eGenes (Fig. 1 e, FDR < 0.05) were used to construct a gene co-expression network, and 18 co-expression modules of eGenes in early to mid-lactation blood were identified (Fig. 3 a). Next, 18 modules were tested for association with phenotypic traits (parity, somatic cell count, somatic cell score, milk production, percentage of milk fat, percentage of milk protein, urea nitrogen, percentage of lactose, leukocyte count, and neutrophil, lymphocyte, monocyte, eosinophil, and basophil ratios). The results suggested that different modules were significantly associated with known phenotypes ( P < 0.05; Fig. 3 a).

Characterizing the function of gene expression modules. ( a ) Association between eGene co-expression module and individual phenotype of trait. ( b ) GO analysis of phenotype of trait significant association module genes. GO terms of modules related to function of immune (module 17,2,16,13 and 11), metabolic (module 7), parity (module 10) and gene regulation (module 5,6 and 10). SCC: somatic cell counts. SCS: somatic cell score
Genes in the identified modules were enriched in GO terms corresponding to the biological features of the phenotype (Fig. 3 b). Five modules (modules 2, 11, 13, 16, and 17) that were significantly correlated with SCC, SCS, and blood parameters were enriched for immune-relevant GO terms, such as response to acute inflammatory response, lipopolysaccharide binding, and regulation of autophagy (Fig. 3 b). One module (module 7) was significantly correlated with the milk fat rate and lactose rate, which is enriched for metabolism relevant GO terms, such as tricarboxylic acid cycle and response to glucose (Fig. 3 b). One module (module 10) was significantly correlated with parity and was enriched for longevity and development-relevant GO terms, such as replicative senescence (Fig. 3 b). In addition, modules 5, 6, and 12 were not found to be significantly associated with known phenotypes, but these modules play a role in regulating functions such as sequence-specific mRNA (Fig. 3 b).
Colocalization analysis of eQTL and sQTL with GWAS locus
The eQTL and sQTL identified in this study were co-localized with three production traits (milk yield, milk protein yield, and milk fat yield) and one health trait (somatic cell score) GWAS loci in 27,214 dairy cows [ 21 ]. The results suggest that SNP rs109421300, which was significantly associated with milk yield, milk protein yield, milk fat yield, and somatic cell score, was also an eQTL and sQTL of DGAT1 (Fig. 4 ). The DGAT1 gene is known to be an important gene for production traits in dairy cows and plays a key role in regulating milk fat production. Previous study has reported the known K232A coding mutation (rs109234250 and rs109326954) in DGAT1 [ 22 ]. Through linkage disequilibrium analysis, it was found that rs109421300 is highly linked with the K232A coding mutation (Figure S6 a). Meanwhile, conditional analysis of DGAT1 gene expression with rs109421300 as a covariate still revealed an independent eQTL (Figure S6 b). Therefore, the biological effects of SNPs related to the DGAT1 gene need further validation. SNP rs109421300 may be a key marker related to DGAT1 gene expression, alternative splicing, and individual phenotypic traits.

GWAS signals of DGAT1 gene co-localized with eQTL and sQTL in four traits. ( a-d ) are GWAS Manhattan plots of milk yield, somatic cell score, milk fat and milk protein respectively. ( e ) Manhattan plot of eQTL. ( f ) The allele of eQTL rs109421300 corresponds to the expression level of DGAT1 gene. The selected genome range of Manhattan plot is consistent: Chr14:1.4-2.4 Mb. The reference genome is UMD3.1
To explore the association between gene expression and complex traits, we integrated the SNP genotyping, gene expression, and GWAS summary data. These results suggest that FAM83H gene expression was significantly associated with milk fat yield, milk yield, milk protein yield, and SCS traits ( P < 0.05; Fig. 5 a) [Additional file 1, Table S 3]. The effect of FAM83H gene expression level on milk fat yield was the opposite of that on milk yield, milk protein yield, and somatic cell count (Fig. 5 b). Genes TBC1D17 associated with sire calving ease, and CRACR2B associated with sire stillbirth, were also identified ( P < 0.05).

TWAS. ( a ) Gene-level Manhattan plot showing P -value results from TWAS. ( b ) Z -scores showing the direction of genetic effect for the genotype-inferred expression of transcripts. Sire_Calv_Ease: Sire calving ease; Sire_Still_Birth: Sire stillbirth. The reference genome is ARS.UCD.1.2
Here, we reveal a part of the genetic control pattern of gene expression and splicing in dairy cows during early to mid-lactation, and highlight the impact of regulatory variation on complex traits.
Transcripts, as molecular phenotypes, are susceptible to confounding factors, such as biological and technical factors [ 23 ]. Therefore, this study systematically evaluated the influence of confounding factors to ensure the robustness and reproducibility of the eQTLs and sQTLs. Previous studies have showed that the lactation stage [ 9 ] and parity [ 24 ] of dairy cattle, as well as RIN [ 25 ] and cell type composition [ 26 ], affect transcript expression. Similarly, this study also found that lactation stage, parity, and RIN value need to be considered as covariates in the association analysis of blood.
In this study, most of the eQTLs and sQTLs identified during early to mid-lactation of dairy cows, as well as the eGenes and sGenes, were independent. This indicates that there are similarities and differences in the regulation of gene expression and alternative splicing mechanisms by molecular QTL. A recent study showed that the overlap ratio of detected eGenes and sGenes positively correlated with the number of samples [ 27 ]. However, even if a gene is both an eGene and sGene, most of the corresponding eQTLs and sQTLs are far away from each other and have a low degree of linkage. It is worth noting that limited to the short read length of next-generation sequencing, we do not have effective analysis methods to completely identify each alternatively spliced isoform and to understand the regulatory mechanism of sQTL.
Early to mid-lactation is an important period for dairy cattle production. By comparing eQTLs and eGenes in early-mid lactation with cGTEx, some eQTLs and eGenes with specific effects during early to mid lactation were found. GO terms enriched by these specific eGenes are interesting, for example, glucose can affect milk protein synthesis [ 28 ], and calcium is essential for milk synthesis [ 29 ]. However, it should be noted that the number of SNPs, sample size, composition of breeds, and other information used in this study and in cGTEx for eQTL identification differ. Therefore, this study focuses on the specific eQTLs and eGenes in the early and mid-lactation periods of Holstein cows. In addition, WGCNA analysis of eGenes in early to mid-lactation showed that the eGene expression module was enriched in the biological function module, corresponding to the individual phenotype. Although blood may not be the main tissue for functions other than immunity, it potentially contains genetic regulatory information on various tissues and organs in an individual [ 30 , 31 ]. Because the effects of eQTLs detected in blood may be shared across multiple tissues, the contribution of these eQTLs to the phenotype of complex traits is completed through gene expression control in multiple tissues [ 3 , 4 , 32 ].
Colocalization is an effective method for integrating molecular QTLs with GWAS signals of complex traits to identify possible causal mutations. In this study, rs109421300 was a key marker obtained by co localization of eQTL and sQTL of DGAT1 with GWAS signals. Meanwhile, rs109421300 is also a cis -eQTL for DGAT1 in the blood, liver, macrophages, mammary glands, monocytes, pituitary glands, and uterus of the cGTEx atlas but not cis -sQTL [ 4 ]. This indicated that the eQTL effect of rs109421300 may not be limited to early-mid lactation, but that the sQTL effect may be specific to early-mid lactation. DGAT1 is important for lactation in dairy cows [ 33 , 34 ]. Knockdown of DGAT1 expression in mammary epithelial cells significantly reduced intracellular triglyceride content [ 35 ]. Regarding for the SNP effect, among the A and G alleles of rs109421300, the G allele resulted in extreme antagonistic pleiotropy between positive milk fat yield, negative milk yield, and milk protein yield [ 36 ]. However, the effect of rs109421300 is based on association analysis, which could potentially be influenced by linkage disequilibrium. As a result, further validation through FLGA [ 37 ] and dual-luciferase reporter assay systems is needed to confirm its biological effects.
It is worth noting that rs109421300 is located 1,149 bp upstream of the reported K232A causal mutation of DGAT1 . K232A affects the activity of DGAT1 enzyme and alternative splicing of DGAT1 [ 22 , 38 ], while rs109421300 is located in a non-coding region, which is mainly observed to be associated with gene expression and alternative splicing. We hypothesize that non-coding variants and K232A coding mutation may be different biological factors affecting DGAT1 gene. However, due to the limitation of the SNP beadchip lacking information on the K232A coding mutation, further study is needed to investigate the differential impact of both rs109421300 and K232A on DGAT1 gene expression and alternative splicing. Given the high linkage of SNPs around the DGAT1 gene and the complexity of its regulatory network, as well as the importance of DGAT1 in dairy cow production, future studies should systematically analyze the regulation of genomic variations on target genes through epigenetic regulatory elements, three-dimensional genomics, luciferase reporter gene assays, and gene editing (e.g. CRISPR-Cas9) [ 39 ].
The TWAS is an important method for inferring the causal relationship between gene expression and the phenotypes of complex traits [ 40 ]. We found that FAM83H was significantly associated with milk fat yield, milk yield, milk protein yield, and SCS. FAM83H was also found to be regulated by eQTL in other blood samples from dairy cows [ 4 , 41 ]. Interestingly, the direction of the effect of FAM83H expression on milk fat yield, milk protein yield, milk yield, and SCS was similar to that of DGAT1 , and their effects on the phenotypes of complex traits may be genetically linked. In addition, dairy cattle are involved in pregnancy events during early to mid-lactation; therefore, the development of early embryos and reproductive organs may be related to sire calving ease and sire stillbirth. TBC1D17 associated with sire calving ease is a member of the TBC1 domain family, and studies have shown that TBC1D2 can be used as a diagnostic tool for human endometrial receptivity [ 42 ]. TBC1D8 is expressed in the embryo and endometrium of Holstein cattle [ 43 ]. CRACR2B is related to sire stillbirths. It is a regulator of the calcium release activation channel and belongs to the calcium-ion binding signaling pathway. Abortion in dairy cows is closely related to the calcium signaling pathways. Calcium ions are important messengers involved in the normal development and function of the placenta [ 44 ].
As the first detailed analysis of cis -e/sQTL during early to mid-lactation in dairy cattle, our study has certain limitations. The number of samples and the density of SNPs need to be increased to improve the detection power and number of e/sQTLs. Meanwhile, the identification of molecular QTLs in bulk tissue will mask the effects of some QTLs, and analyzing molecular QTLs at the single-cell level will help us better understand the impact of regulatory variation on complex traits.
This study demonstrated the importance of considering the lactation stage of blood expression when using eQTL and sQTL data to interpret complex trait-associated variants in dairy cattle. Blood samples can help us understand the regulatory mechanism of eQTL and sQTL on the complex traits of dairy cattle in early to mid-lactation, and the identified important SNPs and genes can provide reference for downstream molecular experimental verification and application.
Materials and methods
Sample collection and phenotyping.
A total of 104 blood samples of Holstein cows in early to mid-lactation (22–150 days after calving and parity ≤ 3) were collected from the tail vein and stored in EDTA vacutainers for blood routine testing, genotyping and RNA-Seq. Milk was collected three times daily at a ratio of 4:3:3, with each collection consisting of a mixed sample from the four milk quarters of the cow. This was then stored in a tube with preservatives at 4℃ for determination of milk quality. All procedures involving experimental animals were approved by the Animal Welfare Committee of the China Agricultural University, Beijing, China. All efforts were made to minimize suffering and discomfort of the experimental animals.
RNA extraction, sequencing, and quality control
The white blood cell layer was separated from fresh anticoagulated blood and centrifuged at 3,500 rpm for 15 min. Total RNA was isolated from peripheral blood leukocytes using TRIzol (Thermo Fisher Scientific, Waltham, MA, USA) according to the manufacturer’s instructions. RNA quality was checked using a 1% agarose gel and a NanoDrop. The integrity of RNA (RIN) was tested using an Agilent 2100, and quantification was performed using a Qubit 2.0. Sequencing was completed on an Illumina NovaSeq-6000 platform, and 150-bp paired-end reads were produced. Trimmomatic (v0.39) [ 45 ] was used to perform quality control of raw reads using the following parameters: adapters: TruSeq3-PE.fa:2:30:10 LEADING:3 TRAILING:3 SLIDINGWINDOW:4:15 MINLEN:36.
DNA genotyping and quality control
Individuals were genotyped using a GGP bovine 150 K BeadChip (Neogen, Lansing, MI, USA). SNPs with a minor allele frequency < 0.05, Hardy-Weinberg equilibrium exact test P -value less than 1 × 10 − 5 , missing genotype rates per-variant > 0.05 and missing genotype rates per-sample > 0.1 were filtered from analysis. The SNPs coordinates of the 150 K BeadChip were transferred from UMD3.1 to ARS.UCD.1.2, based on the SNP rsid. Ultimately, 101 individuals and 95,799 SNPs were included in the analysis.
Quantification of gene expression and alternative splicing
Qualified RNA-seq reads were aligned to the ARS.UCD.1.2 genome [ 46 ] using STAR (v2.7.9a) [ 47 ]. Mapped reads were used for quantification and normalization of gene expression. TPM (Transcripts per million) were obtained using StringTie (v2.1.5) [ 48 ] and transcript counts were quantified using featureCounts (subread package v2.0.2) [ 49 ]. To improve the reliability of our data, we only saved genes with TPM > 0.1 in at least 20% of the samples, and read counts greater than 6 in at least 20% of the samples were retained. EdgeR (v3.34.1) [ 50 ] was used to perform Trimmed Mean of M-values (TMM) and Counts per million (CPM) normalization on these genes. Inverse normal transformed values of gene expression were obtained for downstream analysis.
LeafCutter (v.0.2.9) [ 51 ] was used to identify and quantify the variable alternative splicing events of the genes. First, the bam files obtained from STAR alignment is converted into junction files using the script ‘bam2junc.sh’. Then, the script ‘leafcutter_cluster.py’ was used to performed intron clustering with default settings of 50 reads per cluster and a maximum intron length of 500 kb. Afterward, we conducted the ‘prepare_genotype_table.py’ script in LeafCutter to calculate intron excision ratios and to remove introns used in fewer than 40% of individuals or with no variation. Finally, the standardized and quantile-normalized intron excision ratios were used as the percent spliced-in (PSI) values across samples.
Covariate analysis for QTL discovery
To remove the effects of hidden batch effects and other biological sources of transcriptome-wide variation in gene expression and intron excision ratios, we applied the PEER method (probabilistic estimation of expression residuals) [ 20 ] to identify and account for additional covariates based on the matrix of gene expression and intron excision ratio, respectively. The top five genotype principal components (PCs) were calculated using SNPRelate (v1.26.0) [ 52 ] to account for the effects of population genetic structure. Pearson correlations between the top ten gene expression PCs (EPC), intron excision ratio PCs (SPC), and known phenotypes (week of lactation, parity, RIN and blood cell count) were calculated to identify other factors that affect the expression level of the molecular phenotype. Week of lactation, parity, and the RNA integrity number (RIN) showed the highest correlations and were used as known covariates. Finally, the top five genotype PCs, week of lactation, parity, RIN, and PEER factors (the top 10 peer factors in cis -eQTL mapping and the top eight peer factors in cis -sQTL mapping) were removed from the QTL mapping.
Estimation of the heritability of gene expression and intron excision ratio
A total of 14,303 genes and 227,733 intron clusters were used to estimate the heritability of gene expression and the intron excision ratio, respectively. The cis -SNPs used to estimate the heritability of gene expression were defined as SNPs within 1 Mb of the target gene transcription initiation site (TSS), while cis -SNPs used to estimate the heritability of the intron excision ratio were defined as SNPs within 1 Mb of the target intron clusters. GCTA (v1.93.3 beta2) [ 53 ] was used to generate the corresponding genetic relationship matrix (GRM) based on the cis -SNPs of target genes or intron clusters. Subsequently, heritability was estimated by using the restricted maximum likelihood (REML) algorithm through the “-reml” function in GCTA while correcting for the aforementioned covariates.
cis -eQTL mapping
We used a linear regression model in FastQTL (v2.184) [ 54 ] to test the associations of the expression levels of genes with SNPs within TSS 1 Mb of target genes, while adjusting for the corresponding top 10 PEER factors, top five genotype PCs, and the known covariates (week of lactation, parity and RIN). This method is consistent with cGTEx [ 4 ]. First, cis -eQTL mapping was performed in permutation mode to identify genes (eGene) with at least one significant cis -eQTL. The cis -eQTLs FDR ≤ 0.05 were considered as significant, calculated using the Benjamini–Hochberg method based on the beta distribution-extrapolated empirical P- values from FastQTL. To identify a list of significant eQTL-eGene pairs, the nominal mode was applied to FastQTL. The genome-wide empirical P -value threshold p t for each gene was defined as the empirical P -value of the gene closest to an 0.05 FDR threshold. We then calculated the nominal threshold as F − 1 ( p t ) for each gene using the permutation mode of FastQTL (v2.184), where F − 1 is the binominal inverse cumulative distribution. Variants with nominal P -values below the nominal threshold as significant and included in the list of eGene–eVariant pairs.
cis -sQTL mapping
The cis -sQTL mapping was performed with FastQTL, testing for associations with SNP within ± 1 Mb of target intron clusters and their corresponding intron excision ratio. The covariates used were the same as cis -eQTL mapping, except that the top eight PEER factors were used in cis -sQTL mapping. Unlike cis -eQTL mapping, grouped permutations were used to jointly compute empirical P -value for all intron clusters. The top nominal cis -sQTL for a gene was defined as the highest association among all assigned clusters and introns. The 1,000–10,000 permutations were applied in FastQTL to obtain beta-approximated permutation P -values. The sQTL–intron pairs FDR ≤ 0.05 were considered as significant, and defined cis -sGene as genes containing any introns with a significant cis -sQTL. To identify cis -sGenes, similar to cis -eQTLs, computation of an sGene-level nominal P -value threshold was used to identify all significant variant-intron pairs.
Enrichment analysis of eQTL and sQTL
Ensembl Variant Effect Predictor (VEP) was used to annotate the effects of variants. Additionally, annotations of genomic chromatin states in cow spleen were used for enrichment analysis [ 55 ]. Compared to all SNP loci on the beadchip, Fisher’s exact test is conducted on eQTLs and sQTLs to determine whether they are significantly enriched at these loci or regions.
Comparison of blood cis -eQTL between Holstein in early-mid lactation and cGTEx cattle
To determine the specific cis -eQTLs and eGenes in the early to mid-lactation period of Holsteins, the SNPs detected exclusively in this study and not in cGTEx were firstly removed. Subsequently, the cis -eQTLs ( P < 0.05) and eGenes identified in this study were compared with the cis -eQTLs ( P < 0.05) and eGenes of cGTEx [ 4 ] for SNP overlap analysis.
WGCNA (weighted gene co-expression network analysis) and enrichment analysis of eGenes
Co-expression modules of 3,419 eGenes ( P < 0.05; this study) were built with a soft threshold of 5 to explore the relationship between underlying modules and some phenotypes, including six blood counts from routine blood tests (leukocyte count, neutrophil ratio, lymphocyte ratio, monocyte ratio, eosinophil ratio, and basophil ratio) and milk composition records. The eGenes of modules associated with at least one phenotype were used for GO (Gene Ontology) enrichment analysis using the online website KOBAS-i [ 56 ].
Colocalization analysis and transcriptome-wide association study (TWAS)
To test whether eQTL and sQTL co-localized with GWAS signals of complex traits in dairy cows, we used the GWAS summary statistics of milk yield, milk fat yield, milk protein yield, and somatic cell score from 27,214 bulls for colocalization analysis [ 21 ]. The Bayesian based software Coloc (v5.1.0) [ 57 ] was used for the analysis. PP4 (posterior probability of colocalization hypothesis) > 0.60 in eQTL and sQTL, was used to determine colocalization.
TWAS was performed to estimate the association between gene expression levels and complex traits using S-PrediXcan (v0.6.11) [ 58 ]. In this study a nested cross-validated Elastic Net prediction model was first trained based on the genotype and normalized gene expression data of 101 individuals in this study. In addition to the GWAS summary statistics used for colocalization [ 21 ], retained placenta, productive life, metritis, mastitis, livability, ketosis, hypocalcemia, sire calving ease, and sire stillbirth were used for TWAS [ 59 ]. Genes with P < 0.05 were considered to be significantly correlated with these traits.
Data availability
The raw RNA sequence data reported in this paper have been deposited in the Genome Sequence Archive in National Genomics Data Center, China National Center for Bioinformation / Beijing Institute of Genomics, Chinese Academy of Sciences (GSA: CRA012735) that are publicly accessible at https://ngdc.cncb.ac.cn/gsa/s/saqR97XE . The public GWAS summary statistics from Figshare ( https://figshare.com/s/ea726fa95a5bac158ac1 ). The public eQTL summary statistics from cGTEx ( https://cgtex.roslin.ed.ac.uk/ ). The SNP BeadChip data for the current study are available from the corresponding author on reasonable request.
Hu ZL, Park CA, Reecy JM. Bringing the animal QTLdb and CorrDB into the future: meeting new challenges and providing updated services. Nucleic Acids Res. 2022;50:D956–61.
Article CAS PubMed Google Scholar
Xiang R, Hayes BJ, Vander JC, MacLeod IM, Khansefid M, Bowman PJ, et al. Genome variants associated with RNA splicing variations in bovine are extensively shared between tissues. BMC Genomics. 2018;19:521.
Article PubMed PubMed Central Google Scholar
The GTEx consortium. The GTEx consortium atlas of genetic regulatory effects across human tissues. Science. 2020;369:1318–30.
Article PubMed Central Google Scholar
Liu S, Gao Y, Canela-Xandri O, Wang S, Yu Y, Cai W, et al. A multi-tissue atlas of regulatory variants in cattle. Nat Genet. 2022;54:1438–47.
Article CAS PubMed PubMed Central Google Scholar
Xiang R, Fang L, Liu S, Macleod IM, Liu Z, Breen EJ, et al. Gene expression and RNA splicing explain large proportions of the heritability for complex traits in cattle. Cell Genom. 2023;3:100385.
Walker RL, Ramaswami G, Hartl C, Mancuso N, Gandal MJ, de la Torre-Ubieta L, et al. Genetic control of expression and splicing in developing human brain informs disease mechanisms. Cell. 2019;179:750–71.
Yazar S, Alquicira-Hernandez J, Wing K, Senabouth A, Gordon MG, Andersen S, et al. Single-cell eQTL mapping identifies cell type–specific genetic control of autoimmune disease. Science. 2022;376:f3041.
Article Google Scholar
Lemay DG, Lynn DJ, Martin WF, Neville MC, Casey TM, Rincon G, et al. The bovine lactation genome: insights into the evolution of mammalian milk. Genome Biol. 2009;10:R43.
Wickramasinghe S, Rincon G, Islas-Trejo A, Medrano JF. Transcriptional profiling of bovine milk using RNA sequencing. BMC Genomics. 2012;13:45.
Akers RM. A 100-year review: mammary development and lactation. J Dairy Sci. 2017;100:10332–52.
Contreras GA, Strieder-Barboza C, De Koster J. Symposium review: modulating adipose tissue lipolysis and remodeling to improve immune function during the transition period and early lactation of dairy cows. J Dairy Sci. 2018;101:2737-52.
Bai X, Zheng Z, Liu B, Ji X, Bai Y, Zhang W. Whole blood transcriptional profiling comparison between different milk yield of Chinese holstein cows using RNA-seq data. BMC Genomics. 2016;17 Suppl 7:512.
Dong W, Yang J, Zhang Y, Liu S, Ning C, Ding X, et al. Integrative analysis of genome-wide DNA methylation and gene expression profiles reveals important epigenetic genes related to milk production traits in dairy cattle. J Anim Breed Genet. 2021;138:562–73.
Wang D, Liu L, Augustino S, Duan T, Hall TJ, MacHugh DE, et al. Identification of novel molecular markers of mastitis caused by Staphylococcus aureus using gene expression profiling in two consecutive generations of Chinese holstein dairy cattle. J Anim Sci Biotechnol. 2020;11:98.
Yan Z, Huang H, Freebern E, Santos D, Dai D, Si J, et al. Integrating RNA-seq with GWAS reveals novel insights into the molecular mechanism underpinning ketosis in cattle. BMC Genomics. 2020;21:489.
Qi T, Wu Y, Zeng J, Zhang F, Xue A, Jiang L, et al. Identifying gene targets for brain-related traits using transcriptomic and methylomic data from blood. Nat Commun. 2018;9:2282.
Hawe JS, Wilson R, Schmid KT, Zhou L, Lakshmanan LN, Lehne BC, et al. Genetic variation influencing DNA methylation provides insights into molecular mechanisms regulating genomic function. Nat Genet. 2022;54:18–29.
Xiong X, Hou L, Park YP, Molinie B, Gregory RI, Kellis M. Genetic drivers of m(6)a methylation in human brain, lung, heart and muscle. Nat Genet. 2021;53:1156–65.
Yuan Z, Sunduimijid B, Xiang R, Behrendt R, Knight MI, Mason BA, et al. Expression quantitative trait loci in sheep liver and muscle contribute to variations in meat traits. Genet Sel Evol. 2021;53:8.
Stegle O, Parts L, Piipari M, Winn J, Durbin R. Using probabilistic estimation of expression residuals (PEER) to obtain increased power and interpretability of gene expression analyses. Nat Protoc. 2012;7:500–07.
Jiang J, Cole JB, Freebern E, Da Y, VanRaden PM, Ma L. Functional annotation and bayesian fine-mapping reveals candidate genes for important agronomic traits in Holstein bulls. Commun Biol. 2019;2:212.
Grisart B, Farnir F, Karim L, Cambisano N, Kim JJ, Kvasz A, et al. Genetic and functional confirmation of the causality of the DGAT1 K232A quantitative trait nucleotide in affecting milk yield and composition. Proc Natl Acad Sci U S A. 2004;101:2398–403.
Zhou HJ, Li L, Li Y, Li W, Li JJ. PCA outperforms popular hidden variable inference methods for molecular QTL mapping. bioRxiv. 2022; https://doi.org/10.1101/2022.03.09.483661 .
Buggiotti L, Cheng Z, Salavati M, Wathes CD. Comparison of the transcriptome in circulating leukocytes in early lactation between primiparous and multiparous cows provides evidence for age-related changes. BMC Genomics. 2021;22:693.
Gallego RI, Pai AA, Tung J, Gilad Y. RNA-seq: impact of RNA degradation on transcript quantification. BMC Biol. 2014;12:42.
Kim-Hellmuth S, Aguet F, Oliva M, Muñoz-Aguirre M, Kasela S, Wucher V, et al. Cell type-specific genetic regulation of gene expression across human tissues. Science. 2020;369:eaaz8528.
Qi T, Wu Y, Fang H, Zhang F, Liu S, Zeng J, et al. Genetic control of RNA splicing and its distinct role in complex trait variation. Nat Genet. 2022;54:1355–63.
Danes M, Hanigan MD, Arriola AS, Dias J, Wattiaux MA, Broderick GA. Post-ruminal supplies of glucose and casein, but not acetate, stimulate milk protein synthesis in dairy cows through differential effects on mammary metabolism. J Dairy Sci. 2020;103:6218–32.
Cavani L, Poindexter MB, Nelson CD, Santos J, Peñagaricano F. Gene mapping, gene-set analysis, and genomic prediction of postpartum blood calcium in Holstein cows. J Dairy Sci. 2022;105:525–34.
Basu M, Wang K, Ruppin E, Hannenhalli S. Predicting tissue-specific gene expression from whole blood transcriptome. Sci Adv. 2021;7:eabd6991.
Zhang X, Joehanes R, Chen BH, Huan T, Ying S, Munson PJ, et al. Identification of common genetic variants controlling transcript isoform variation in human whole blood. Nat Genet. 2015;47:345–52.
Li L, Huang K, Gao Y, Cui Y, Wang G, Elrod ND, et al. An atlas of alternative polyadenylation quantitative trait loci contributing to complex trait and disease heritability. Nat Genet. 2021;53:994–1005.
Johnsson M, Jungnickel MK. Evidence for and localization of proposed causative variants in cattle and pig genomes. Genet Sel Evol. 2021;53:67.
Winter A, Krämer W, Werner FA, Kollers S, Kata S, Durstewitz G, et al. Association of a lysine-232/alanine polymorphism in a bovine gene encoding acyl-coa:diacylglycerol acyltransferase (DGAT1) with variation at a quantitative trait locus for milk fat content. Proc Natl Acad Sci U S A. 2002;99:9300–5.
Lu C, Yang R, Shen B, Osman H, Zhang Y, Yan S, et al. RNA interference-mediated knockdown of DGAT1 decreases triglyceride content of bovine mammary epithelial cell line. Gene Expr. 2012;15:199–206.
Article PubMed Google Scholar
Jiang J, Ma L, Prakapenka D, VanRaden PM, Cole JB, Da Y. A large-scale genome-wide association study in U.S. Holstein cattle. Front Genet. 2019;10:412.
Gaiani N, Bourgeois-Brunel L, Rocha D, Boulling A. Analysis of the impact of DGAT1 p.M435L and p.K232A variants on pre-mRNA splicing in a full-length gene assay. Sci Rep. 2023;13:8999.
Fink T, Lopdell TJ, Tiplady K, Handley R, Johnson T, Spelman RJ, et al. A new mechanism for a familiar mutation - bovine DGAT1 K232A modulates gene expression through multi-junction exon splice enhancement. BMC Genomics. 2020;21:591.
Wang Z, Liang Q, Qian X, Hu B, Zheng Z, Wang J, et al. An autoimmune pleiotropic SNP modulates IRF5 alternative promoter usage through ZBTB3-mediated chromatin looping. Nat Commun. 2023;14:1208.
Wainberg M, Sinnott-Armstrong N, Mancuso N, Barbeira AN, Knowles DA, Golan D, et al. Opportunities and challenges for transcriptome-wide association studies. Nat Genet. 2019;51:592–9.
van den Berg I, Hayes BJ, Chamberlain AJ, Goddard ME. Overlap between eQTL and QTL associated with production traits and fertility in dairy cattle. BMC Genomics. 2019;20:291.
Díaz-Gimeno P, Horcajadas JA, Martínez-Conejero JA, Esteban FJ, Alamá P, Pellicer A, et al. A genomic diagnostic tool for human endometrial receptivity based on the transcriptomic signature. Fertil Steril. 2011;95:50–e6015.
Biase FH, Hue I, Dickinson SE, Jaffrezic F, Laloe D, Lewin HA, et al. Fine-tuned adaptation of embryo-endometrium pairs at implantation revealed by transcriptome analyses in Bos taurus. Plos Biol. 2019;17:e3000046.
Sigdel A, Bisinotto RS, Peñagaricano F. Genes and pathways associated with pregnancy loss in dairy cattle. Sci Rep. 2021;11:13329.
Bolger AM, Lohse M, Usadel B. Trimmomatic: a flexible trimmer for illumina sequence data. Bioinformatics. 2014;30:2114–20.
Rosen BD, Bickhart DM, Schnabel RD, Koren S, Elsik CG, Tseng E et al. De novo assembly of the cattle reference genome with single-molecule sequencing. Gigascience. 2020;9.
Dobin A, Davis CA, Schlesinger F, Drenkow J, Zaleski C, Jha S, et al. Star: ultrafast universal RNA-seq aligner. Bioinformatics. 2013;29:15–21.
Pertea M, Kim D, Pertea GM, Leek JT, Salzberg SL. Transcript-level expression analysis of RNA-seq experiments with HISAT, StringTie and Ballgown. Nat Protoc. 2016;11:1650–67.
Liao Y, Smyth GK, Shi W. Featurecounts: an efficient general purpose program for assigning sequence reads to genomic features. Bioinformatics. 2014;30:923–30.
Robinson MD, McCarthy DJ, Smyth GK. edgeR: a Bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics. 2010;26:139–40.
Li YI, Knowles DA, Humphrey J, Barbeira AN, Dickinson SP, Im HK, et al. Annotation-free quantification of RNA splicing using leafcutter. Nat Genet. 2018;50:151–8.
Zheng X, Levine D, Shen J, Gogarten SM, Laurie C, Weir BS. A high-performance computing toolset for relatedness and principal component analysis of SNP data. Bioinformatics. 2012;28:3326–28.
Yang J, Lee SH, Goddard ME, Visscher PM. GCTA: a tool for genome-wide complex trait analysis. Am J Hum Genet. 2011;88:76–82.
Ongen H, Buil A, Brown AA, Dermitzakis ET, Delaneau O. Fast and efficient QTL mapper for thousands of molecular phenotypes. Bioinformatics. 2016;32:1479–85.
Kern C, Wang Y, Xu X, Pan Z, Halstead M, Chanthavixay G, et al. Functional annotations of three domestic animal genomes provide vital resources for comparative. Nat Commun. 2021;12:1821.
Bu D, Luo H, Huo P, Wang Z, Zhang S, He Z, et al. KOBAS-i: intelligent prioritization and exploratory visualization of biological functions for gene enrichment analysis. Nucleic Acids Res. 2021;49:W317–25.
Giambartolomei C, Vukcevic D, Schadt EE, Franke L, Hingorani AD, Wallace C, et al. Bayesian test for colocalisation between pairs of genetic association studies using summary statistics. PLoS Genet. 2014;10:e1004383.
Barbeira AN, Dickinson SP, Bonazzola R, Zheng J, Wheeler HE, Torres JM, et al. Exploring the phenotypic consequences of tissue specific gene expression variation inferred from GWAS summary statistics. Nat Commun. 2018;9:1825.
Freebern E, Santos D, Fang L, Jiang J, Parker GK, Liu GE, et al. GWAS and fine-mapping of livability and six disease traits in Holstein cattle. BMC Genomics. 2020;21:41.
Download references
Acknowledgements
The authors thank the anonymous reviewers for constructive comments and suggestions on the manuscript, and all the member of the Animal Molecular and Quantitative Genetics Laboratory in China Agricultural University. This study was supported by High-performance Computing Platform of China Agricultural University.
This article was financially supported by the National Key R&D Program of China (2021YFD1200903, 2021YFD1200900, 2023YFF1000902), NSFC-PSF Joint Project (31961143009), Beijing Dairy Industry Innovation Team (BAIC06), the Earmarked Fund (CARS-36), Beijing Natural Science Foundation (6182021), the Program for Changjiang Scholar and Innovation Research Team in University (IRT-15R62) and the Seed Fund (CAU).
Author information
Authors and affiliations.
Key Laboratory of Animal Genetics, Breeding and Reproduction, Ministry of Agriculture & National Engineering Laboratory for Animal Breeding, College of Animal Science and Technology, China Agricultural University, Beijing, 100193, China
Yongjie Tang, Jinning Zhang, Wenlong Li, Xueqin Liu, Siqian Chen, Siyuan Mi, Jinyan Yang & Ying Yu
Center for Quantitative Genetics and Genomics, Aarhus University, Aarhus, 8000, Denmark
Lingzhao Fang
State Key Laboratory of Swine and Poultry Breeding Industry, National Engineering Research Center for Breeding Swine Industry, Guangdong Provincial Key Lab of Agro-Animal Genomics and Molecular Breeding, College of Animal Science, South China Agricultural University, Guangzhou, 510642, China
Jinyan Teng
You can also search for this author in PubMed Google Scholar
Contributions
Y.Y., L.F. and Y.T. conceived the study. Y.T., J.Z., S.M., S.C., W.L. and X.L. collected the samples. Y.T. analyzed the data. Y.T. and J.Z. wrote and prepared the manuscript. S.C., J.T., Y.Y., L.F. and J.Y. provided the suggestion about the QTL mapping and functional annotation. All authors read and approved the final manuscript.
Corresponding authors
Correspondence to Lingzhao Fang or Ying Yu .
Ethics declarations
Ethics approval and consent to participate.
All the experiments described here were conducted in accordance with and approved by the Animal Welfare Committee of China Agricultural University (Permit Number: DK996). All efforts were taken to minimize pain and discomfort to animals while conducting these experiments. The study was carried out in compliance with the ARRIVE guidelines.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Supplementary material 2, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Tang, Y., Zhang, J., Li, W. et al. Identification and characterization of whole blood gene expression and splicing quantitative trait loci during early to mid-lactation of dairy cattle. BMC Genomics 25 , 445 (2024). https://doi.org/10.1186/s12864-024-10346-7
Download citation
Received : 30 September 2023
Accepted : 25 April 2024
Published : 06 May 2024
DOI : https://doi.org/10.1186/s12864-024-10346-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Holstein cows
- Early to mid-lactation period
- Colocalization
BMC Genomics
ISSN: 1471-2164
- Submission enquiries: [email protected]
- General enquiries: [email protected]
- Open access
- Published: 16 May 2024
Experiences of UK clinical scientists (Physical Sciences modality) with their regulator, the Health and Care Professions Council: results of a 2022 survey
- Mark McJury 1
BMC Health Services Research volume 24 , Article number: 635 ( 2024 ) Cite this article
Metrics details
In healthcare, regulation of professions is an important tool to protect the public. With increasing regulation however, professions find themselves under increasing scrutiny. Recently there has also been considerable concern with regulator performance, with high profile reports pointing to cases of inefficiency and bias. Whilst reports have often focused on large staff groups, such as doctors, in the literature there is a dearth of data on the experiences of smaller professional groups such Clinical Scientists with their regulator, the Health and Care Professions Council.
This article reports the findings of a survey from Clinical Scientists (Physical Sciences modality) about their experiences with their regulator, and their perception of the quality and safety of that regulation.
Between July–October 2022, a survey was conducted via the Medical Physics and Engineering mail-base, open to all medical physicists & engineers. Questions covered typical topics of registration, communication, audit and fitness to practice. The questionnaire consisted of open and closed questions. Likert scoring, and thematic analysis were used to assess the quantitative and qualitative data.
Of 146 responses recorded, analysis was based on 143 respondents. Overall survey sentiment was significantly more negative than positive, in terms of regulator performance (negative responses 159; positive 106; significant at p < 0.001). Continuous Professional Development audit was rated median 4; other topics were rated as neutral (fitness to practice, policies & procedures); and some as poor (value).
Conclusions
The Clinical Scientist (Physical Sciences) professional registrants rated the performance of their regulator more negatively than other reported assessments (by the Professional Standards Authority). Survey respondents suggested a variety of performance aspects, such as communication and fitness to practice, would benefit from improvement. Indications from this small dataset, suggest a larger survey of HCPC registrants would be useful.
Peer Review reports
In Healthcare, protection of patients and the public is a core principle. Part the framework of protections, includes regulation of professions [ 1 ]. This aims to mitigate risks such as the risk from bogus practitioners – insufficiently trained people acting as fully-trained professional practitioners, see Fig. 1 .

Recent UK media report on a bogus healthcare practitioner [ 2 ]
Regulation of professions ensures that titles (e.g. Doctor, Dentist, Clinical Scientist) are protected in law. The protected title means someone may only use that title, if they are on the national register, managed by the regulator – the Health and Care Professions Council (HCPC). It is a criminal offence to use a protected title if you are not entitled to do so [ 3 ]. There are a large number of regulators in healthcare – see Table 1 . Most of the regulators manage a register for one profession, except the HCPC which regulates 15 professions.
To be included on the register, a candidate must meet the regulators criteria for knowledge and training, and a key element to remain, is to show evidence of continuous professional development (CPD). Being on the register ensures that a practitioner has met the appropriate level of competence and professional practice.
For many healthcare workers, being on the HCPC register is a compulsory requirement to be appointable to a post. They must pay the necessary annual fees, and abide by the policies drawn-up by the regulator, and generally professions have no choice of regulator – these are statutory bodies, setup by government.
Recently, there has been considerable public dissatisfaction with the activity & performance of some regulators, notably Ofwat [ 4 ], and Ofgem [ 5 ]. Healthcare workers should expect a high level of professionalism, efficiency, and integrity from a regulator, as the regulator’s performance directly affects staff and public safety.
In terms of the regulation of UK Clinical Scientists, there is a dearth of data regarding experiences with the HCPC and views on the quality of regulation provided.
Findings are reported here from a 2022 survey of Medical Physicists and Engineers (one of the 16 job roles or ‘modalities’ under the umbrella of Clinical Scientist). The research aim was to assess experiences, and the level of ‘satisfaction’ with the regulator. For the remainder of this report, the term Clinical Scientist will be taken to mean Clinical Scientist (Medical Physicist/Engineer). The survey was designed to gather & explore data about opinions and experiences regarding several key aspects of how the HCPC performs its role, and perception of the quality & safety of regulation delivered.
A short survey questionnaire was developed, with questions aimed to cover the main regulatory processes, including registration & renewal, CPD audit, and fitness-to-practice. There were also questions relating more generally to HCPC’s performance as an organisation, e.g. handling of personal data. Finally, participants were asked to rate the HCPC’s overall performance and what they felt was the ‘value’ of regulation. The survey questions are listed in the Supplementary file along with this article.
Questions were carefully worded and there was a balance of open and closed questions. A five-point Likert score was used to rate closed questions. The survey was anonymous, and the questions were not compulsory, allowing the responders to skip irrelevant or difficult questions. The survey also aimed to be as short & concise as possible, to be a minimal burden to busy clinical staff & hopefully maximise response rate. There were a small number of questions at the start of the survey, to collect basic demographics on the respondents (role, grade, UK nation etc.).
The survey was advertised on the online JISC-hosted UK Medical Physics and Engineering (UKMPE) mail-base. This offered convenient access for the majority of Clinical Scientists. The survey was advertised twice, to allow for potential work absence, holiday/illness etc. It was active from the end of July 2002 until October 2022, when responses appeared to saturate.
The data is a combination of quantitative rating scores, and qualitative text responses. This allows a mixed-methods approach to data analysis, combining quantitative assessment of the Likert scoring, and (recursive) thematic analysis of the free-text answers [ 6 ]. Thematic analysis is a standard tool, and has been reported as a useful & appropriate for assessing experiences, thoughts, or behaviours in a dataset [ 7 ]. The survey questions addressed the main themes, but further themes were identified using an inductive, data-driven approach. Qualitative data analysis (QDA) was performed using NVivo (QSR International).
Two survey questions attempted to obtain an overall perception of HCPC’s performance: the direct one (Q12), and a further question’Would you recommend HCPC as a regulator…?’. This latter question doesn’t perhaps add anything more, and in fact a few respondents suggested it was a slightly awkward question, given professions do not have a choice of regulator – so that has been excluded from the analysis.
Study conduct was performed in accordance with relevant guidelines and regulations [ 8 , 9 ]. Before conducting the survey of Clinical Scientists, the survey was sent to their professional body, the Institute of Physics and Engineering in Medicine (IPEM). The IPEM Professional Standards Committee reviewed the survey questions [ 10 ]. Written informed consent was obtained from participants.
Data analysis
Data was collected via an MS form, in a single excel sheet and stored on a secure network drive. The respondents were anonymised, and the data checked for errors. The data was then imported into NVivo v12.
Qualitative data was manually coded for themes, and auto-coded for sentiment. An inductive approach was used to develop themes.
The sample size of responses allowed the use of simple parametric tests to establish the level of statistical significance.
Survey demographics
A total of 146 responses were collected. Two respondents noted that they worked as an HCPC Partner (a paid role). They were excluded from the analysis due to potential conflict of interest. One respondent’s responses were all blank aside from the demographic data, so they were also excluded from further analysis.
Analysis is based on 143 responses, which represents ~ 6% of the UK profession [ 11 ]. It is arguable whether it is representative of the profession at this proportion of response – but these responses do offer the only sizeable pool of data currently available. The survey was aimed at those who are on the statutory register as they are most likely to have relevant interactions & experiences of the HCPC, but a small number of responses were also received from Clinical Technologists (Medical Technical Officers-MTOs) and Engineers (CEs) and these have been included in the analysis. Figure 2 shows the breakdown in respondents, by nation.

Proportion of respondents, by nation
Of the respondents, 91% are registered Clinical Scientists, and would therefore have a broad range of experience with HCPC and its processes. Mean time on the register was 12 yrs. Respondents show a large range in seniority, and their roles are shown in Fig. 3 (CS-Clinical Scientist; CE-Clinical Engineer; MTO-Medical Technical Officer/Technician; CS-P are those working in private healthcare settings, so not on Agenda for Change (AfC) pay bands).

Breakdown in respondents, by role and pay banding
These data can be compared with the most recent HCPC ‘snapshot’ of the CS registrants (find here: Registrants by profession snapshot—1967 to 2019 | ( https://www.hcpc-uk.org/resources/data/2019/registrant-snapshot/ )).
The perception of overall regulator performance, can be assessed in two ways – one interview question directly asked for a rating score, and the overall survey sentiment also offers additional insight.
The score for overall performance was a median of 3 (mean 2.7; response rate 90%) which suggests neutral satisfaction.
Respondents were not asked directly to explain this overall performance rating – themes were extracted from the questionnaire as a whole.
The auto-coded sentiment scores generated in the NVivo software are shown in Table 2 . There is a significantly stronger negative sentiment than positive for HCPC performance – moderate, strong and total sentiment scores are all higher for negative sentiment. The normal test for a single proportion (109), shows the negative and positive sentiment differences have statistical significance with p < 0.001. Whilst the PSA assessment of HCPC performance in 2022–23 shows 100% performance for 4 out of 5 assessment areas, survey data here from regulated professionals suggests considerably less satisfaction with HCPC. This raises associated questions about the relevance and validity of PSA assessment.
A large number of respondents seem to question the value of regulation. Whilst many accepted the value for it in terms of protecting the safety of the public, many questioned its relevance & benefit to themselves. Many respondents also queried the payment model where although the main beneficiaries of regulation are the public & the employer, it is the registrants actually pay the fees for registration. There was very little mention in survey responses, of benefit in terms of protected-title. These issues were amalgamated into Theme 1— Value of regulation , with the two sub-themes Value in monetary terms (value-for-money) and Value in professional terms (benefit and relevance to the individual professional) (see Table 3 ).
In the survey, several aspects of HCPC organisational performance were scored – handling of personal data, registration and renewal, engagement with the profession, audit, and the quality and usefulness of HCPC policies. These formed Theme 2 and its sub-themes.
A third theme Registrant competence and vulnerability , was developed to focus on responses to questions related to the assessment of registrant competence and Fitness To Practice (FTP) processes.
Finally, the survey also directly asked respondents if they could suggest improvements which would have resulted in higher scoring for regulation quality and performance. These were grouped into Theme 4.
Theme 1 – Value of regulation
Value in monetary terms.
The Likert score for value-for-money was a median of 2 (mean 2.3; response rate 100%) which suggests dissatisfaction. This is one of the few survey questions to elicit a 100% response rate – a clear signal of its importance for registrants.
There was a high number of responses suggesting fees are too expensive (and a significantly smaller number suggesting good value). This ties in with some respondents explaining that the ‘benefit’ from registration is mainly for the employer (an assurance of high quality, well-trained staff). Several respondents point to little ‘tangible’ benefit for registrants and query whether the payment model is fair and if the employer should pay registrant fees.
“Expensive fees for what appears to be very little support.” Resp094
“It seems that I pay about £100 per year to have my name written on a list. It is unclear to me what the HCPC actually does in order to justify such a high fee.” Resp014
“I get, quite literally, nothing from it. It’s essentially a tax on work.” Resp008
Several respondents suggested that as registration was mandated by the employer, it was in essence an additional ‘tax’ on their employment, which was highlighted previously by Unison [ 12 ]. A comparator for payment model, are the checks preformed on potential staff who will be working with children and vulnerable adults. In general, these ‘disclosure’ checks are paid for by the employer, however the checks are not recurrent cost for each individual, but done once at recruitment.
Value in professional terms & relevance
This was not a direct question on the questionnaire, but emerged consistently in survey responses. Aside from value-for-money, the value of regulation can also refer to more general benefit and relevance for a professional, for example in protecting a professional title or emphasising the importance of a role. Many respondents commented, in relation to the ‘value’ of regulation, about the relevance of the HCPC to them and their job/role.
The largest number of responses highlighted the lack of clarity about HCPC’s role, and also to note its lack of relevance felt by a significant proportion of respondents.
“Not sure I have seen any value in my registration except that it is a requirement for my role” Resp017
“I really fail to understand what (sic) the benefits of registration.” Resp018
“They do not promote the profession. I see no evidence of supporting the profession. I pay to have the title and I am not aware of any other benefits.” Resp038
Theme 2 – HCPC performance
Communication & handling data.
The survey questionnaire did not have a specific question relating to communication, therefore no specific Likert scores are available. Rather, communication was a sub-theme which emerged in survey responses. The response numbers related to positive (1) and negative experiences (50) clearly suggest an overall experience of poor communication processes (and statistically significant at p < 0.001 for a normal proportion test).
One respondent noted they had ‘given up’ trying to communicate with HCPC electronically. Several respondents also noted issues with conventional communication—letters from HCPC going to old addresses, or being very slow to arrive.
“…I have given up on contacting by electronic means.” Resp134
When trying to renew their registration, communication with HCPC was so difficult that two respondents noted they raised a formal complaint.
A number of respondents noted that when they eventually got through to the HCPC, staff were helpful, so the main communication issue may relate to insufficiently resourced lines of communication (phones & email) or the need for a more focussed first point of contact e.g. some form of helpdesk or triaging system.
“Recently long wait to get through to speak to someone… Once through staff very helpful.” Resp126
This topic overlaps with the next (Processing Registration & renewals) in that both involve online logins, website use etc.
Security & data handling was rated as neutral (median 3, mean 3.4; response rate 91%). Although responses were balanced in terms of satisfaction, a significant number noted a lack of knowledge about HCPC processes. There are almost equal proportions of respondents reporting no issues, some problems with handling of personal data, or insufficient knowledge to express an opinion.
Registration and renewal
The score for processing registrations & renewals, was a median of 4 (mean 3.5; response rate 92%) which suggests modest satisfaction.
The overall rating also suggests that the issues may have been experienced by a comparative minority of registrants and that for most, renewal was straightforward.
“They expected people to call their phone number, which then wasn’t picked up. They didn’t reply to emails except after repeated attempts and finally having to resort to raising a complaint.” Resp023
“Difficult to get a timely response. Difficult to discuss my situation with a human being…” Resp044
Although the Likert score is positive, the themes in responses explaining the rating, are more mixed. Many respondents mentioned either having or knowing others who had issues with registration renewal, and its online processes including payments. A few respondents mentioned that the process was unforgiving of small errors. One respondent, for example, missed ticking a box on the renewal form, was removed from the register and experienced significant difficulties (poor communication with HCPC) getting the issue resolved.
Some respondents noted issues related to a long absence from work (e.g. maternity/illness etc.) causing them to miss registration deadlines – for some, this seems to have resulted in additional fees to renew registration. It seems rather easy for small errors (on either side) to result in registrants being removed from the register. For registrants, this can have very serious consequences and it can then be difficult and slow to resolve this, sometimes whilst on no pay. There have also been other reported instances of renewal payment collection errors [ 13 ].
“I had been off work… and had missed their renewal emails…I was told that there would be no allowances for this situation, and I would have to pay an additional fee to re-register…” Resp139.
Some respondents raised the issue of exclusion – certain staff groups not being included on the register—such as Clinical Technologists and Clinical Engineers. This desire for inclusion, also points to a perception of value in being on the register. One respondent raised an issue of very difficult and slow processing of registration for a candidate from outside the UK.
“Staff member who qualified as medical physicist abroad…has had a dreadful, drawn out and fruitless experience.” Resp135
Overall, many respondents noted difficulties in renewing registration and issues with HCPC’s online processes. Some of these issues (e.g. website renewal problems) may have been temporary and are now resolved, but others (e.g. available routes for registration) remain to be resolved.
Audit process & policies
In the survey, 12% respondents reported having been audited by HCPC regarding their CPD (response rate 97%). This is well above the level of 2.5% of each profession, which HCPC aims to review at each renewal [ 14 ], and similar values reported by some professional bodies [ 15 ]. The participants seem representative, although two respondents mentioned their perception of low audit rates. Data on CPD audit is available here: https://www.hcpc-uk.org/about-us/insights-and-data/cpd/cpd-audit-reports/
Respondents rated the process of being audited as a median of 4 (mean 3.7), which is the joint highest score on the survey, pointing to satisfaction with the process. From the responses, the overall perception could be summed up as straight-forward, but time-consuming. Without regular record-keeping, unfortunately most audits will be time-consuming – the HCPC more so, as it is not an annual audit, but covers the two preceding years.
Some respondents did find the process not only straight-forward, but also useful (related to feedback received). However, responses regarding feedback were mixed, with comments on both good, and poor feedback from HCPC.
“Not difficult but quite long-winded” Resp008
“Very stressful and time consuming” Resp081
“While it was a lot of work the process seemed very thorough and well explained.” Resp114
The HCPC’s policies & procedures were rated as a median of 3 (mean 3.2; response rate 98%). This neutral score could suggest a mixture of confidence in HCPC practise. This score may also reflect the fact that the majority of respondents had either not read, or felt they had no need to read the policies, and so are largely unfamiliar with them.
The reasons for this lack of familiarity are also explained by some respondents – four commented that the policies & procedures are rather too generic/vague. Three respondents noted that they felt the policies were not sufficiently relevant to their clinical roles to be useful. This may be due to the policies being written at a level to be applicable to registrants from all 16 modalities – and perhaps a limitation of the nature of HCPC as a very large regulator. Familiarity seemed mainly to be restricted to policies around registration, and CPD. There were slightly lower response levels for positive sentiment (6), than negative sentiment (9).
“I’ve never had cause to read them.” Resp115
“Detached from the real clinical interface for our professions…” Resp083
HCPC split their policies into ‘corporate’- which relate to organisational issues (e.g. equality & diversity; find them here: Our policies and procedures | ( https://www.hcpc-uk.org/about-us/corporate-governance/freedom-of-information/policies/#:~:text=Our%20main%20policies%20and%20procedures%201%20Customer%20feedback,scheme%20...%207%20Freedom%20of%20Information%20Policy%20 )) and those more relevant to professions (e.g. relating to the register; find them here: Resources | ( https://www.hcpc-uk.org/resources/?Query=&Categories=76 )).
One respondent noted not only that the policies were ‘as you might expect’, but felt the policies were less demanding than those from other similar bodies such as the CQC ( https://www.cqc.org.uk/publications ).
“…Other regulatory bodies (such as the CQC for example) have policies and procedures that are a lot more challenging to comply with.” Resp022
Theme 3 – Registrant competence and vulnerability
In this survey, 3.5% (5/143) of respondents noted some involvement with the HCPC’s Fitness to Practice service. These interactions were rated at a median of 3 (mean 2.8) suggesting neutral sentiment.
Firstly, we can immediately see the level of interaction with the FTP team is very small. CS registrants represent approx. 2% of HCPC registrants, and the level of CS referrals to FTP in 2020–21 was 0.2% [ 16 ].
The data is a very small sample, but responses vary strongly, so it is worth digging a little further into the granularity of individual responses. Response scores were 1, 1, 2, 5, 5 – which are mainly at the extremes of the rating spectrum. The majority of respondents described poor experiences with the FTP team: errors, a process which was ‘extremely prolonged’, involved slow/poor communication, and processes which were ‘entirely opaque’.
“It is slow, the process was badly managed… and the system was entirely opaque,” Resp37
“They were hard to contact and I didn't feel they listened…no explanation, apology or assurance it would not happen again. It left my colleague disillusioned and me very angry on their behalf…” Resp044
Some respondents commented that the team were not only difficult to contact, but also didn’t seem to listen. At the end of a process which involved errors from HCPC, one respondent noted were ‘no explanation, apologies or assurance that it would not happen again’, leaving the registrant ‘disillusioned’. These experiences do not fit with the HCPC’s stated goal to be a compassionate regulator, see Fig. 4 . Arguably it is more difficult to change a culture of behaviour and beliefs, than to publish a corporate goal or statement of vision.

HCPC’s vision statement & purpose [ 17 ]
Some survey respondents have noted the necessity of regulation for our profession.
“Ultimately I am very grateful that I can register as a professional.” Resp024
Theme 4 – Suggestions for improved regulation
Following the question relating to overall performance, respondents were invited to suggest things which might improve their rating for HCPC’s performance and value. These suggestions were also combined with those which appeared in earlier survey responses.
Although we are in a current cost-of-living crisis, responses did not query simply high absolute cost of fees, but also queried the value/benefit of HCPC regulation for registrants. Many responses expressed doubt as to the added value & relevance of HCPC registration for them. They seem to point to a desire for more tangible benefit from their fees. Perhaps, given the costs and levels of scrutiny, registrants want some definite benefit to balance the scales .
“Cost less and do more for the people who are on the register.” Resp089
“Vastly reduced cost. Employer paying registrant fees.” Resp074
A significant number of responses pointed out that the main benefits of registration are for the public, and for employers – but that it is the registrants who pay for registration. Many queries why this should be, and whether there should be a different payment model, where for example employers pay.
Similarly, some respondents felt that the HCPC’s unusual position of regulating a large swathe of healthcare professions was not necessarily helpful for their profession or others.
Communication and response times are obviously an issue of concern for registrants, and improvements are needed based on the low satisfaction levels reported here. This is also linked to a wish for increased engagement with the CS profession.
“Engagement with the workforce, specialism specific development, reduced fees” Resp025
Some responses suggested they would be comforted by increased accountability / governance of HCPC including improved FTP efficiency.
“More accountability to registrants” Resp130
Finally, improvement in terms of additional registration routes for Engineers & Technical staff were also suggested. It may be damaging to work-place moral, if two professionals doing roles of a similar nature are not being governanced is the same way and if there is not parity of their gross salary due to mandatory professional fees & reductions.
Value-for-money : This will vary between individuals depending on many variables, such as upbringing & environment, salary, lifestyle priorities, political persuasion, and so on. However, many of these factors should balance in a large sample. In general, it can be suggestive of satisfaction (or lack of) with a service. The score here suggesting dissatisfaction, echoes with other reports on HCPC’s spending, and financial irregularities [ 18 , 19 ].
In the survey findings, respondents have voiced dissatisfaction with registration value for money. In fact, HCPC’s registration fees are not high when compared to the other healthcare professions regulators. Table 1 shows data from 2021–22 for regulator annual registration fees. However, the HCPC has risen from having the lowest regulator fees in 2014–5, to its current position (9 th of 13) slightly higher in the table. Perhaps more concerning than the absolute level of fees, are when large increases are proposed [ 12 , 20 , 21 , 22 ].
However, fees have regularly increased to current figure of £196.48 for a two-year cycle. During a consultation process in 2018, the Academy for Healthcare Clinical Scientists (AHCS) wrote an open letter to the HCPC, disputing what they felt was a disproportionate fee increase [ 23 ]. Further fee rises have also been well above the level of inflation at the time.
HCPC expenditure (which is linked to registration fees) has arguably been even more controversial than fee increases – noted by several respondents. A freedom of information (FOI) request in 2016 showed HCPC’s spending of £17,000 for their Christmas party [ 18 ] – which amounts to just over £76 per person. This cost was close to the annual registration fee (at that time) for registrants.
In 2019, regulation of social workers in England moved from HCPC, to Social Work England. This resulted in a loss of over 100,000 registrants, and a loss in registration fee income. HCPC raised fees to compensate, but a freedom of information (FoI) request in 2020 [ 18 ] showed that even though there was an associated lowering in workload associated with the loss of 100 k registrants, the HCPC had no redundancies, suggesting the loss of income was compensated mainly by the fees increase.
Inherent value & relevance
One of HCPC’s aims is to promote ‘the value of regulation’ [ 24 ]. However, not only is there dissatisfaction with value-for-money, the second highest response suggests a lack of inherent value (or benefit) from regulation to the individual registrant. In some ways, there is a lack of balance – registrants are under increasing scrutiny, but feel there is little direct benefit, to provide balance.
This also suggests that HCPC’s aim or message is not getting through to the CS profession. It’s not clear what the HCPC 2021–22 achieved milestone – ‘Embedded our registrant experiences research into employee learning and development and inductions’ has actually achieved.
A large number of responses pointed to the lack of clarity about HCPC’s role, and also to note its lack of relevance for respondents. Some of this is understandable – until recently, many CS registrants will have little interaction with HCPC. They would typically get one email reminder each year to renew their registration and pay those fees, and hear little else from the HCPC. That is beginning to change, and HCPC have recently begun to send more regular, direct emails/updates to registrants.
However, for many registrants, the HCPC appears not to be clearly communicating its role, or the relevance/importance of regulation. As mentioned above, this also links in to previous mentions of the lack of any tangible benefit for registrants. Some note little more relevance other than the mandatory aspects of regulation.
Finally, relevance is also queried in relation to the limited access for some professional groups to a professional register. The current situation of gaps in registration for some groups, results in two situations – firstly, for Clinical Scientists and Clinical Engineers/Technologists, one group has to compulsorily pay a fee to be allowed/approved to do their job and the other does not; also, the public are routinely helped and assisted by Clinical Scientists and Clinical Engineers/Technologists – but only one group is regulated to ensure public safety.
HCPC Communication
This was highlighted by respondents as often poor. Recently in the media, there has been a concern raised by The College of Paramedics (CoP) about communications issues with HCPC—changes to the HCPC policy on the use of social media [ 25 ]. They raised particular concerns about the use of social media content and ‘historical content’ in the context of investigations of fitness-to practice.
There have previously been some concerns raised on the UKMPE mail-base regarding handling of personal data, and lack of efficiency in addressing the issue [ 26 ]. Several messages detailed HCPC communicating unencrypted registrant passwords in emails and sending personal data to the incorrect registrant. Some on the forum noted that they had reported this problem over a period of several years to HCPC, suggesting HCPC’s response to these serious issues was extremely slow. Several responses noted these previous issues.
Registration processes
Although responses here show some satisfaction, there have been reports in the media of significant issues with registration (such as removing registrants from the register in error) with associated impact for patients and the public [ 27 , 28 ]. Similarly, there were reports on the UKMPE mail-base of significant issues with registration renewals being problematic [ 26 ]. In Scotland, NHS.net email accounts ceased to be supported in July-Sept 2020 and the associated lack of access to email accounts and messages used for HCPC communication and registration, caused a major issue in registration renewal. This coincided with COVID lockdowns and a period of unusually difficult communication with HCPC. If NHS staff lose registration (irrespective of the reason), respondents noted that some Human Resources (HR) departments were quick to suspend staff from work, and in some cases withhold pay. That spike in difficulties is likely the cause of the most common responses suggesting issues with a complicated process.
In safe-guarding public safety, a key task for a healthcare regulator is assessing the competence of registrants. This is done via a small set of related activities. Registrants must return regular evidence of CPD, and these are audited for 2.5% registrants. This process is simple and routine, and as seen in Theme 2 responses here suggest registrants are reasonably satisfied with this process.
More formal and in-depth competence assessment happens when a complaint is raised against a registrant, either by a work colleague/management, a member of the public or occasionally by the HCPC itself. The process is complex, lengthy and can end in a registrant attending a court hearing [ 29 ].
It is usual for registrants to continue in their normal job during FTP investigations – effectively the public remains at risk from a registrant if their competence is eventually proven to be below the regulators standards, so there is a need for investigations to be efficient both in timeliness, and outcome.
Obviously, being under investigation can be highly stressful, and has the potential for the registrant to be ‘struck off’ the register, and lose their job if registration is mandated (e.g. NHS posts). There are many reports of the process & experience either provoking or increasing underlying mental health challenges [ 30 , 31 , 32 ]. Along with efficiency, a regulator needs to behave compassionately. Investigations of highly-skilled professionals engaging in complex work activities, is also necessarily complex and requires a high degree of knowledge and experience from the regulator’s investigational panel.
The Professional Standards Authority (PSA) regulate the HCPC, and publish annual reviews of their performance ( https://www.professionalstandards.org.uk/publications/performance-reviews ) (see Table 4 ). HCPC performance as reported by PSA, seems to be generally higher than noted by survey respondents here. For 2022–23, aside from one area, the HCPC has scored 100% for performance, which seems at odds with these survey responses [ 33 ]. The FTP team is notable in repeatedly performing very poorly compared to most other sections of the HCPC (even though the majority of the HCPC budget goes to FTP activity, see Fig. 4 ). The HCPC Annual Report 2018–9 [ 34 ] highlighted the completion of the first phase of the Fitness-To-Practice Improvement Plan. This delivered “A root and branch review of this regulatory function… a restructure, tightened roles and processes and the introduction of a new Threshold Policy”, but this seems to have no impact on the performance reported by the PSA for the next few years shown in Table 4 . However, the most recent data does suggest improvement, and HCPC continues to develop FTP team practice [ 17 ].

HCPC expenditure for the year 2020–21 [ 17 ]
There are other reports of poor experiences with this team [ 35 , 36 ], and in one report the FTP team’s processes have been noted as being rather inhumane [ 35 ].
Regulation is an important part of public protection, but how effectively it is managed & enforced is also a concern, given it involves increased scrutiny of registrants. A topical comparator is the current dissatisfaction by a large section of the public about several other government regulators allowing seemingly poor performance to go unchecked [ 4 , 5 ].
It is arguable, that registrants remain on the register as long as the HCPC allows them. Several respondents in this survey noted being removed from the register through HCPC administrative error. Removal could also happen through poor judgement/decision-making – the FTP team handle large numbers of very complex investigational cases – 1603 concluded cases for the year 2021–22 and 1024 hearings [ 16 ]. Every justice system is subject to a level of error – guilty parties can be erroneously ‘cleared’, and vice-versa. It is essential therefore, that policies & procedures relating to FTP are fit for purpose—that the FTP team work effectively and humanely, and that there is genuine & effective governance of HCPC to ensure accountability. In this survey, some respondents seem to be saying that currently this seems not to be the case.
It might have been anticipated that the greatest concern is costs, especially in the current cost-of-living crisis. The recent HCPC consultation to increase fees [ 37 ] seems particularly tone-deaf and has caused concern across the professions [ 21 , 22 ].
Above findings show respondents are interested in lower fees, but also increased benefit for their fees. Some respondents pointed out that whilst registrants pay for registration, benefit is mainly for the public and employers. The HCPC is a statutory body, its funding model will have been designed/decided upon by government, and may be unlikely to change. However, there are a variety of potential regulation models [ 38 ], and so change is possible. A review of the financial model for regulation may be welcome.
Regulator size
Some aspects of HCPC performance, policies, and distribution of spending, is related to the nature of it being the largest and only multi-professional regulator in the healthcare sector. Data from the HCPC suggests (see Fig. 5 ) that the majority of spending relates to FTP activity. Data also points to Clinical Scientists having very low levels of FTP investigation compared to others in HCPC [ 16 ]. This suggests that a significant proportion of CS registrant fees are used to investigate other professions. It’s possible (perhaps simplistically) that if, like many other healthcare professions such as doctors & dentists who’s regulator is concerned only with that single profession, if CSs were regulated separately, their registrant fees may be reduced. This model of single-profession regulation may also mitigate against other disadvantages of the HCPC’s practice, such as the ‘generic’ policies aiming to apply to a pool of 15 professions.
Although there is a very low level of data for this topic, the concerned raised by registrants are serious in nature. There also seems to be issues in handling of complaints related to this service and advocacy for registrants. Certainly, there is a clear governance path via PSA, to the Health Secretary. However, this does not offer a route for individual complaints to be raised and addressed. Unlike complaints from the public in other areas, there is no recourse to an ombudsman for registrants. The only option for individual registrants, is the submission of a formal complaint to the HCPC itself, which is dealt with internally. Comments from survey respondents suggest this process does not guarantee satisfaction. Indeed, one of the respondents who mentioned submitting a complaint, made it clear they remained unhappy with HCPC’s response. Overall, there seems to be a lack of clear & effective advocacy for registrants.
“…the HCPC’s stance appeared to be guilty until proven innocent… At no point did I feel the HCPC cared that their (sic) was an individual involved....” Resp044.
FTP processes affect a comparatively small number of CS registrants, compared to other professions. However, it seems clear that the majority of those who have interacted with the FTP team have had poor experiences, and respondents have suggested improvements are needed. The reason for FTP investigations, is protection of staff and the public. If processes are slow, and investigations prolonged, or decisions flawed, the public may be exposed to increased levels of risk, as healthcare practitioners who may be lacking in competence continue to practice. The data in Table 4 shows concerning but improving trends in FTP performance levels.
Limitations
There are two main limitations to this work. Firstly, due to time constraints, there was no pilot work done when designing the survey questionnaire. This may have helped, as noted earlier, a few responses pointed to some awkwardness with one survey question. Although no pilot work was done, the questionnaire was reviewed by the IPEM Professional Standards Committee, as noted in the Acknowledgements section.
The other obvious limitation is the low response rate (~ 6% of UK Medical Physicists). Circulation of the survey was performed via the only online forum for the profession currently available. The survey was advertised multiple times to ensure visibility to staff who may have missed it initially due to leave etc. However, the forum does reach 100% of the profession, and some addressees may have filters set to send specific posts to junk folders etc. The professional body IPEM declined to offer support in circulating the survey (believing the issues involved would affect/be of interest only to a small minority of members.)
The low response rate also has a particular impact on the pool of responses relating to FTP issues, which inherently affect low numbers of registrants.
However, the importance of some of the findings here (e.g. expressed dissatisfaction with regulation in terms of value; the poor experience of some members with the Registration, Communication and FTP teams) and the low sample surveyed, both justify the need for a larger follow-on survey, across all of Clinical Science.
In Healthcare, regulation of professions is a key aspect of protecting the public. However, to be effective, regulation must be performed professionally, impartially, and associated concerns or complaints investigated efficiently and respectfully.
This report presents findings from a survey aimed at collecting a snap-shot of the experiences of Clinical Scientists with their regulator, and their perception of the quality and safety of that regulation performance.
Overall survey sentiment scores showed a significantly more negative responses than positive. Survey comments relate not only to current issues, but to previous problems and controversial issues [ 18 , 26 ]. It seems that some respondents have at some point lost confidence and trust in the HCPC, and survey responses suggest there has not been enough engagement and work done by HCPC to repair and rebuild this trust.
In the midst of a cost of living crisis, costs are a large concern for many. The HCPC fees are neither the highest not lowest amongst the healthcare regulators. Spending is transparent, and details can be found in any of the HCPC’s annual reports.
A repeating sub-theme in responses, was a lack of tangible value for the registrant, and that the employer should pay the costs of registration, where registration is mandated by the job.
Many respondents have suggested that they feel there should be more proactive engagement from HCPC with the profession. Most respondents were not familiar with or felt the HCPC policies are relevant/important to them.
Survey data showed moderate satisfaction with registration processes for the majority of respondents. Some respondents also noted a lack of registration route for engineering & technical healthcare staff. CPD processes also achieved a score indicating registrant satisfaction. This generated the highest ratings in the survey. Communication scored poorly and many respondents suggests there needs to be improved levels of communication in terms of response times and access to support.
The CS profession experiences low levels of interaction with the FTP service. However, those interactions which were recorded in the survey, show some poor experiences for registrants. There also seems to be a lack of advocacy/route for complaints about HCPC from individual registrants. There may need to be more engagement between registrants and their professional body regarding HCPC performance, and more proactivity from the stake-holder, IPEM.
Some of the findings reported here relate to important issues, but the survey data are based on a low response rate. A larger survey across all of Clinical Science is being planned.
Availability of data and materials
To protect confidentiality of survey respondents, the source data is not available publicly, but are available from the author on reasonable request.
Abbreviations
Agenda for Change
Academy for Healthcare Clinical Scientists
Continuous professional development
Clinical Engineer
Clinical Scientist
College of Paramedics
Clinical Technologist
Freedom of Information
Fitness-to-practice
Health and Care Professions Council
Human resources
Institute of Physics and Engineering in Medicine
Joint Information Systems Committee
Medical Technical Officer
Professional Standards Authority
Professional Standards Committee
Qualitative data analysis
UK Medical Physics and Engineering
Professional Standards Authority. Professional healthcare regulation in the UK. https://www.professionalstandards.org.uk/news-and-blog/blog/detail/blog/2018/04/10/professional-healthcare-regulation-explained#:~:text=Regulation%20is%20simply%20a%20way,may%20face%20when%20receiving%20treatment . Accessed 26 Jul 2023
Evening Standard. Bogus surgeon treated hundreds. https://www.standard.co.uk/hp/front/bogus-surgeon-treated-hundreds-6326549.html . Accessed 26 Jul 2023.
HCPC . About registration: protected titles. http://www.hcpc-uk.org/aboutregistration/protectedtitles/ . Accessed 27 Jul 23.
The Guardian. Public patience is wearing thin. Ofwat must wield the big stick | Nils Pratley | https://www.theguardian.com/business/nils-pratley-on-finance/2022/dec/08/public-patience-is-wearing-thin-ofwat-must-wield-the-big-stick . Accessed 19 Jul 2023.
TrustPilot. Reviews of Ofgem. Ofgem Reviews | Read Customer Service Reviews of ofgem.com (trustpilot.com). Accessed 19 Jul 2023.
Braun V, Clarke V. Using thematic analysis in psychology. Qual Res Psychol. 2006;3(2):77–101.
Article Google Scholar
Kiger ME, Varpio L. Thematic analysis of qualitative data: AMEE Guide No. 131. Med Teach. 2020;42(8):846–54.
Article PubMed Google Scholar
Declaration of Helsinki. 2013. https://www.wma.net/policies-post/wma-declaration-of-helsinki-ethical-principles-for-medical-research-involving-human-subjects/ . Accessed 12 Sept 2023.
UK Data Protection Act. 2018. https://www.gov.uk/data-protection . Accessed 15 Sept 2023.
Rowbottom C. Private communication on behalf of the IPEM Professional Standards Committee; 2022.
IPEM Workforce Team. Clinical scientist & engineer workforce data. Personal communication. 2022.
Unison. HCPC fee increase is an unjustified ‘tax on practising.’ https://www.unison.org.uk/news/press-release/2019/02/hcpc-fee-increase-unjustified-tax-practising/ . Accessed 27 Jul 2023.
HCPC. Direct debit collection errors. https://www.hcpc-uk.org/news-and-events/news/2020/early-direct-debit-collections/?dm_i=2NJF,141CO,7C0ZNI,4A8IE,1 . Accessed 27 Jul 23.
HCPC. CPD audit rates. https://www.hcpc-uk.org/cpd/cpd-audits/ . Accessed 21 Jul 2023.
IPEM. CPD audit rates. https://www.ipem.ac.uk/your-career/cpd-career-development/cpd-audit/ . Accessed 21 Jul 2023.
HCPC. Fitness to practice annual report 2020–21. https://www.hcpc-uk.org/about-us/insights-and-data/ftp/fitness-to-practise-annual-report-2020-21/ . Accessed 23 Jul 2023.
HCPC. Annual report and accounts, 2020–21. https://www.hcpc-uk.org/resources/reports/2022/annual-report-and-accounts-2020-21/ . Accessed 19 Jul 2023.
Wikipedia. The health and care professions council. https://en.wikipedia.org/wiki/Health_and_Care_Professions_Council . Accessed 2 Jul 23.
HCPC. Annual report 2005–06. https://www.hcpc-uk.org/resources/reports/2006/annual-report-2005-06/ . Accessed 19 Jul 2023.
British Dental Association. BDA very disappointed by HCPC decision to raise registration fees by 18%. https://www.bda.uk.com/resource/bda-very-disappointed-by-hcpc-decision-to-raise-registration-fees-by-18.html . Accessed 27 Jul 2023.
British Psychological Society. HCPC fees consultation – share your views. https://www.bps.org.uk/news/hcpc-fee-consultation-share-your-views . Accessed 27 Jul 23.
IBMS. IBMS response to the HCPC registration fees consultation. https://www.ibms.org/resources/news/ibms-response-to-hcpc-registration-fees-consultation/ . Accessed 17 Jul 23.
Association of HealthCare Scientists. Open letter to HCPC. https://www.ahcs.ac.uk/wp-content/uploads/2018/11/HCPC-Open-Letter.pdf . Accessed 27 Jul 23.
HCPC. Corporate plan 2022–23. https://www.hcpc-uk.org/resources/reports/2022/hcpc-corporate-plan-2022-23/ . Accessed 23 Jul 2023.
College of Paramedics. Our formal response to the HCPC consultation. https://collegeofparamedics.co.uk/COP/News/2023/Our%20formal%20response%20to%20the%20HCPC%20consultation.aspx . Accessed 27 Jul 23.
JISC Mail - MPE mailbase. JISCMail - Medical-physics-engineering list at www.jiscmail.ac.uk . Accessed 19 July 2023.
The Guardian. Thousands miss out on treatment as physiotherapists are taken off UK register. https://www.theguardian.com/society/2022/may/14/thousands-miss-out-on-treatment-as-physiotherapists-are-struck-off-uk-register . Accessed 27 Jul 2023.
HSJJobs.com. https://www.hsjjobs.com/article/thousands-of-clinicians-unable-to-work-after-registration-blunder . Accessed 27 Jul 2023.
HCPC. How we investigate. https://www.hcpc-uk.org/concerns/how-we-investigate/ . Accessed 21 Nov 2023.
Sirriyeh R, Lawton R, Gardner P, Armitage G. Coping with medical error: a systematic review of papers to assess the effects of involvement in medical errors on healthcare professionals’ psychological well-being. Br Med J Qual Saf. 2010;19:6.
Google Scholar
Bourne T, Wynants L, Peters M, van Audenhove C, Timmerman D, van Calster B, et al. The impact of complaints procedures on the welfare, health and clinical practise of 7926 doctors in the UK: a cross-sectional survey. BMJ Open. 2015;5:e006687.
Article PubMed PubMed Central Google Scholar
Jones-Berry S. Suicide risk for nurses during fitness to practice process. Ment Health Pract. 2016;19:8.
Professional Standards Authority. HCPC performance review 2022–23. https://www.professionalstandards.org.uk/publications/performance-review-detail/periodic-review-hcpc-2022-23 . Accessed 25 Jul 2023
HCPC. Annual report and accounts, 2018–19. https://www.hcpc-uk.org/resources/reports/2019/hcpc-annual-report-and-accounts-2018-19/ . Accessed 19 Jul 2023.
Maben J, Hoinville L, Querstret D, Taylor C, Zasada M, Abrams R. Living life in limbo: experiences of healthcare professionals during the HCPC fitness to practice investigation process in the UK. BMC Health Serv Res. 2021;21:839–54.
Leigh J, Worsley A, Richard C, McLaughlin K. An analysis of HCPC fitness to practise hearings: fit to practise or fit for purpose? Ethics Soc Welfare. 2017;11(4):382–96.
HCPC. Consultation changes to fees. https://www.hcpc-uk.org/news-and-events/consultations/2022/consultation-on-changes-to-fees/ . Accessed 27 Jul 23
Department of Health. Review of the regulation of public health professions. London: DoH; 2010.
Download references
Acknowledgements
The author wishes to kindly acknowledge the input of Dr Carl Rowbottom (IPEM Professional Standards Committee), in reviewing the survey questions. Thanks also to Dr Nina Cockton for helpful advice on ethics and recruitment issues.
There were no sources of funding required for this work.
Author information
Authors and affiliations.
University of Glasgow, Level 2, ICE Building, Queen Elizabeth University Hospital Campus, 1345 Govan Road, Glasgow, G51 4TF, UK
Mark McJury
You can also search for this author in PubMed Google Scholar
Contributions
All work to collect, analyse & publish this survey, are the work of the author Dr Mark McJury.
Corresponding author
Correspondence to Mark McJury .
Ethics declarations
Ethics approval and consent to participate.
As this study relates to low risk, survey data, formal ethics committee approval is not required (exemption obtained from NHSGGC REC04 REC Officer Dr Judith Godden [email protected]). As the survey responses were from members of a professional body (The Institute of Medical Physics and Engineering in Medicine (IPEM) it was consulted. Its Professional Standards Committee (PSC) reviewed the survey and raised no objections. The survey questions were assessed for bias and approved unchanged (acknowledged in the manuscript). Written informed consent was obtained from all participants in the study.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1..
The survey questionnaire has been provided as a supplementary file.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
McJury, M. Experiences of UK clinical scientists (Physical Sciences modality) with their regulator, the Health and Care Professions Council: results of a 2022 survey. BMC Health Serv Res 24 , 635 (2024). https://doi.org/10.1186/s12913-024-10956-7
Download citation
Received : 06 September 2023
Accepted : 05 April 2024
Published : 16 May 2024
DOI : https://doi.org/10.1186/s12913-024-10956-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Regulation of professions
- Clinical scientists
- Medical physicists
BMC Health Services Research
ISSN: 1472-6963
- General enquiries: [email protected]
Transcriptome analysis reveals key genes and pathways associated with heat stress in Pleurotus pulmonarius
- Published: 16 May 2024
Cite this article

- Wang Weike ORCID: orcid.org/0000-0002-2228-6519 1 ,
- Lin Jiayao 1 ,
- Lai Liqin 2 &
- Chen Guanping ORCID: orcid.org/0000-0002-2229-9424 3
17 Accesses
Explore all metrics
Pleurotus pulmonarius is a medium temperature edible mushroom, and its yield and quality are severely affected by high temperature. However, the molecular mechanism of Pleurotus pulmonarius response to heat stress remains unknown. In this study, transcriptome sequencing and analysis of Pleurotus pulmonarius mycelia under heat stress were performed, related differentially expressed genes (DEGs) were verified by fluorescence quantitative PCR (qPCR) and the reduced glutathione content was detected. 5906 DEGs, including 1086 upregulated and 4820 downregulated, were identified by RNA-Seq. GO analysis revealed that DEGs were mainly enriched in the pathways of Aminoacyl-tRNA biosynthesis, pyrimidine metabolism, arginine and proline metabolism, fructose and mannose metabolism, and glutathione metabolism. qPCR analysis showed that the expression of ggt decreased after heat stress treatment, while gst 2 and gst 3 increased. The glutathione content in mycelia after heat stress was significantly higher than that in the control group. These results suggest that glutathione metabolism may play an important role in the response to heat stress. Our study will provide a molecular-level perspective on fungal response to heat stress and a basis for research on fungal environmental response and molecular breeding.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
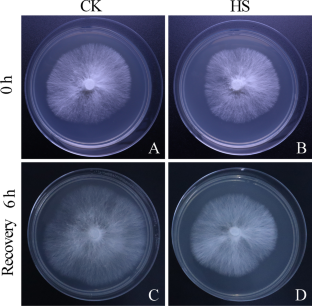
Similar content being viewed by others

Transcriptomic analysis of Stropharia rugosoannulata reveals carbohydrate metabolism and cold resistance mechanisms under low-temperature stress

Comparative analysis of genome-wide transcriptional responses to continuous heat stress in Pleurotus tuoliensis

Transcriptional profiling provides new insights into the role of nitric oxide in enhancing Ganoderma oregonense resistance to heat stress
Data availability.
No datasets were generated or analysed during the current study.
Abbreviations
- Differentially expressed genes
Quantitative real-time polymerase chain reaction
Glutathione-S-transferase
Glutathione
Potato dextrose agar
Gene ontology
Kyoto Encyclopedia of Genes and Genomes
Glyceraldehyde-3-phosphate dehydrogenase
Reactive oxygen species
Anjum NA, Gill R, Kaushik M et al (2015) ATP-sulfurylase, sulfur-compounds, and plant stress tolerance. Front Plant Sci 6:210. https://doi.org/10.3389/fpls.2015.00210
Article PubMed PubMed Central Google Scholar
Bao DP, Xie BG (2020) Some research directions worthy of attention in the genetics of edible mushrooms in China. Mycosystema 6:971–976. https://doi.org/10.13346/j.mycosystema.200168
Article CAS Google Scholar
Cui B, Wang JQ, Song CX et al (2016) Cloning and expression analysis of SOC1 gene from Phalaenopsis. Mol Plant Breed 14(3):548–553. https://doi.org/10.13271/j.mpb.014.000548
Dillies MA, Rau A, Aubert J et al (2013) A comprehensive evaluation of normalization methods for Illumina high-throughput RNA sequencing data analysis. Brief Bioinform 14(6):671–683. https://doi.org/10.1093/bib/bbs046
Article CAS PubMed Google Scholar
Grabherr MG, Haas BJ, Yassour M et al (2011) Full-length transcriptome assembly from RNA-seq data without a reference genome. Nat Biotechnol 29(7):644–652. https://doi.org/10.1038/nbt.1883
Article CAS PubMed PubMed Central Google Scholar
Hao H, Zhang J, Wang Q et al (2022) Transcriptome and differentially expressed gene profiles in mycelium, primordium and fruiting body development in Stropharia rugosoannulata . Genes (basel) 3(6):1080. https://doi.org/10.3390/genes13061080
Kanehisa M, Araki M, Goto S et al (2008) KEGG for linking genomes to life and the environment. Nucleic Acids Res 36:D480–D484. https://doi.org/10.1093/nar/gkm882
Lee J, Nam JY, Jang H et al (2020) Comprehensive transcriptome resource for response to phytohormone-induced signaling in Capsicum annuum L. BMC Res Notes 13(1):440. https://doi.org/10.1186/s13104-020-05281-1
Liu XM, Wu XL, Gao W et al (2019) Protective roles of trehalose in Pleurotus pulmonarius during heat stress response. J Integr Agric 18(2):428–437. https://doi.org/10.1016/S2095-3119(18)62010-6
Liu XB, Xia EH, Li M et al (2020b) Transcriptome data reveal conserved patterns of fruiting body development and response to heat stress in the mushroom-forming fungus Flammulina filiformis. PLoS ONE 15(10):e0239890. https://doi.org/10.1371/journal.pone.0239890
Liu D, Sun X, Diao W et al (2022) Comparative transcriptome analysis revealed candidate genes involved in fruiting body development and sporulation in Ganoderma lucidum. Arch Microbiol 204(8):514. https://doi.org/10.1007/s00203-022-03088-1
Liu LY, Zhou Y, Chen H et al (2020a) Research progress of Pleurotus geesteranus. Microbiol China 11:3650–3657. https://doi.org/10.13344/j.microbiol.china.200504
Pócsi I, Prade RA, Penninckx MJ (2004) Glutathione, altruistic metabolite in fungi. Adv Microb Physiol 49:1–76. https://doi.org/10.1016/S0065-2911(04)49001-8
Tang X, Ding X, Hou YL (2020) Comparative analysis of transcriptomes revealed the molecular mechanism of development of Tricholoma matsutake at different stages of fruiting bodies. Food Sci Biotechnol 29(7):939–951. https://doi.org/10.1007/s10068-020-00732-8
Vidal-Diez de Ulzurrun G, Lee YY, Stajich JE et al (2021) Genomic analyses of two Italian oyster mushroom Pleurotus pulmonarius strains. G3 (Bethesda) 11(2):2160–1836. https://doi.org/10.1093/g3journal/jkaa007
Wang B, Zhang TX, Zhao Q et al (2021) Application progress of plant metabonomics in medicinal plants. Chinese Arch Tradit Chinese Med 39(5):28–31. https://doi.org/10.13193/j.issn.1673-7717.2021.05.008
Article Google Scholar
Young MD, Wakefield MJ, Smyth GK et al (2010) Gene ontology analysis for RNA-seq: accounting for selection bias. Genome Biol 11:R14. https://doi.org/10.1186/gb-2010-11-2-r14
Download references
Acknowledgements
The authors gratefully acknowledge the supports of the Westlake University, Jin Weiyuan.
This research has been funded by Zhejiang Major Science and Technology Projects of New Agricultural Varieties Breeding (2021C02073) and Project of Administration of Traditional Chinese Medicine of Zhejiang Province of China (2024ZF049).
Author information
Authors and affiliations.
Hangzhou Academy of Agricultural Sciences, Hangzhou, China
Wang Weike, Lu Na & Lin Jiayao
Pathology Department, Tongde Hospital of Zhejiang Province, Hangzhou, China
Cancer Institute of Integrated Traditional Chinese and Western Medicine, Zhejiang Academy of Traditional Chinese Medicine, Tongde Hospital of Zhejiang Province, Hangzhou, China
Chen Guanping
You can also search for this author in PubMed Google Scholar
Contributions
WW: conceptualization, project administration, writing—original draft. CG: resources, supervision, methodology, investigation, project administration, writing—review and editing. LN: conceptualization, supervision, writing—review and editing. LJ: methodology, resources. LL: methodology, data curation, formal analysis.
Corresponding author
Correspondence to Chen Guanping .
Ethics declarations
Ethics approval.
This article does not contain any studies with human or animal subjects.
Consent to participate
Not applicable.
Consent for publication
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Weike, W., Na, L., Jiayao, L. et al. Transcriptome analysis reveals key genes and pathways associated with heat stress in Pleurotus pulmonarius . Int Microbiol (2024). https://doi.org/10.1007/s10123-024-00536-4
Download citation
Received : 01 April 2024
Revised : 06 May 2024
Accepted : 10 May 2024
Published : 16 May 2024
DOI : https://doi.org/10.1007/s10123-024-00536-4
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Pleurotus pulmonarius
- Heat stress
- Molecular mechanism
- Find a journal
- Publish with us
- Track your research
IMAGES
VIDEO
COMMENTS
Introduction. Statistical analysis is necessary for any research project seeking to make quantitative conclusions. The following is a primer for research-based statistical analysis. It is intended to be a high-level overview of appropriate statistical testing, while not diving too deep into any specific methodology.
Quantitative data has to be gathered and cleaned before proceeding to the stage of analyzing it. Below are the steps to prepare a data before quantitative research analysis: Step 1: Data Collection. Before beginning the analysis process, you need data. Data can be collected through rigorous quantitative research, which includes methods such as ...
Revised on June 22, 2023. Quantitative research is the process of collecting and analyzing numerical data. It can be used to find patterns and averages, make predictions, test causal relationships, and generalize results to wider populations. Quantitative research is the opposite of qualitative research, which involves collecting and analyzing ...
This analysis seeks to identify data patterns, trends, and linkages to inform decisions and predictions. Quantitative data analysis uses statistics and math to solve problems in business, finance, and risk management problems. It is an important technique that helps financial analysts, scientists, and researchers understand challenging ideas ...
Abstract. Quantitative data analysis serves as part of an essential process of evidence-making in health and social sciences. It is adopted for any types of research question and design whether it is descriptive, explanatory, or causal. However, compared with qualitative counterpart, quantitative data analysis has less flexibility.
Data analysis is important in research because it makes studying data a lot simpler and more accurate. It helps the researchers straightforwardly interpret the data so that researchers don't leave anything out that could help them derive insights from it. Data analysis is a way to study and analyze huge amounts of data.
Quantitative data analysis is one of those things that often strikes fear in students. It's totally understandable - quantitative analysis is a complex topic, full of daunting lingo, like medians, modes, correlation and regression.Suddenly we're all wishing we'd paid a little more attention in math class…. The good news is that while quantitative data analysis is a mammoth topic ...
It is important to know w hat kind of data you are planning to collect or analyse as this w ill. affect your analysis method. A 12 step approach to quantitative data analysis. Step 1: Start with ...
Revised on 10 October 2022. Quantitative research is the process of collecting and analysing numerical data. It can be used to find patterns and averages, make predictions, test causal relationships, and generalise results to wider populations. Quantitative research is the opposite of qualitative research, which involves collecting and ...
Chapter Learning Objectives. Understand the justification for quantitative analysis. Learn how data and the scientific process can be used to inform decisions. Learn and differentiate between some of the commonly used terminology in quantitative analysis. Introduce the functions of quantitative analysis.
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense. Three essential things occur during the data ...
June 14, 2021 in [ Doctoral Journey ] The purpose of quantitative research is to attain greater knowledge and understanding of the social world. Researchers use quantitative methods to observe situations or events that affect people. 1 Quantitative research produces objective data that can be clearly communicated through statistics and numbers.
This article is a practical guide to conducting data analysis in general literature reviews. The general literature review is a synthesis and analysis of published research on a relevant clinical issue, and is a common format for academic theses at the bachelor's and master's levels in nursing, physiotherapy, occupational therapy, public health and other related fields.
Education Research: Quantitative research is used in education research to study the effectiveness of teaching methods, assess student learning outcomes, and identify factors that influence student success. Researchers use experimental and quasi-experimental designs, as well as surveys and other quantitative methods, to collect and analyze data.
Quantitative research methods are concerned with the planning, design, and implementation of strategies to collect and analyze data. Descartes, the seventeenth-century philosopher, suggested that how the results are achieved is often more important than the results themselves, as the journey taken along the research path is a journey of discovery. . High-quality quantitative research is ...
Quantitative data analysis may include the calculation of frequencies of variables and differences between variables. A quantitative approach is usually associated with finding evidence to either support or reject hypotheses you have formulated at the earlier stages of your research process. The same figure within data set can be interpreted in ...
Statistical analysis means investigating trends, patterns, and relationships using quantitative data. It is an important research tool used by scientists, governments, businesses, and other organizations. To draw valid conclusions, statistical analysis requires careful planning from the very start of the research process. You need to specify ...
Teaching quantitative data analysis is not teaching number crunching, but teaching a way of critical thinking for how to analyze the data. The goal of data analysis is to reveal the underlying patterns, trends, and relationships of a study's contextual situation. Learning data analysis is not learning how to use statistical tests to crunch ...
When collecting and analyzing data, quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings. Both are important for gaining different kinds of knowledge. Quantitative research. Quantitative research is expressed in numbers and graphs. It is used to test or confirm theories and assumptions.
Qualitative research aims to produce rich and detailed descriptions of the phenomenon being studied, and to uncover new insights and meanings. Quantitative data is information about quantities, and therefore numbers, and qualitative data is descriptive, and regards phenomenon which can be observed but not measured, such as language.
Descriptive analysis is a quantitative data analysis approach that assists researchers in presenting data in an easily understood, quantitative format, assisting in the interpretation and ...
In PhD studies, the purpose usually involves applying a theory to solve the problem. In other words, the purpose tells the reader what the goal of the study is, and what your study will accomplish, through which theoretical lens. The purpose statement also includes brief information about direction, scope, and where the data will come from.
Key Points. Question What are the minimal clinically important differences (MCIDs) in the Diabetes Distress Scale-17 (DDS-17) and its 4 subscales?. Findings This secondary analysis using data from 248 participants in a randomized clinical trial comparing the Empowering Patients in Chronic Care (EPICC) intervention (123 participants) with enhanced usual care (EUC; 125 participants) found that ...
Background Translational microbiome research using next-generation DNA sequencing is challenging due to the semi-qualitative nature of relative abundance data. A novel method for quantitative analysis was applied in this 12-week clinical trial to understand the mechanical vs. chemotherapeutic actions of brushing, flossing, and mouthrinsing against the supragingival dental plaque microbiome ...
Characterization of regulatory variants (e.g., gene expression quantitative trait loci, eQTL; gene splicing QTL, sQTL) is crucial for biologically interpreting molecular mechanisms underlying loci associated with complex traits. However, regulatory variants in dairy cattle, particularly in specific biological contexts (e.g., distinct lactation stages), remain largely unknown.
This study aims to conduct a comprehensive bibliometric analysis to explore the trajectory and thematic developments of emotional labour research in nursing. Design. Utilizing descriptive and bibliometric analysis techniques. Methods. The data analysis and graphical presentation were conducted using the Bibliometrix Package in R software. Data ...
This allows a mixed-methods approach to data analysis, combining quantitative assessment of the Likert scoring, and (recursive) thematic analysis of the free-text answers . Thematic analysis is a standard tool, and has been reported as a useful & appropriate for assessing experiences, thoughts, or behaviours in a dataset . The survey questions ...
Pleurotus pulmonarius is a medium-temperature edible mushroom whose optimum growth temperature is 20-22 ℃. Temperature is very important for its growth and development; if the temperature is too high, mycelium and fruiting bodies often stop growing or even die (Liu et al. 2020a).High temperature stress is an important reason for the decrease of yield and quality of Pleurotus pulmonarius.